 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Reasoning Capabilities of Small Language Models via Solution Guidance Fine-Tuning
Dec 13, 2024

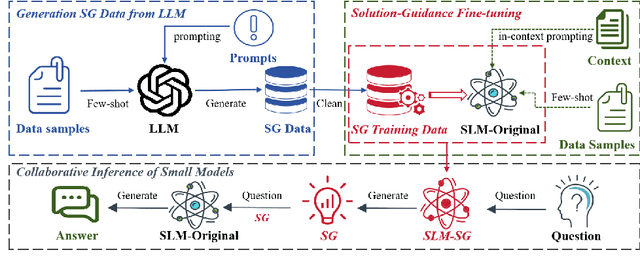
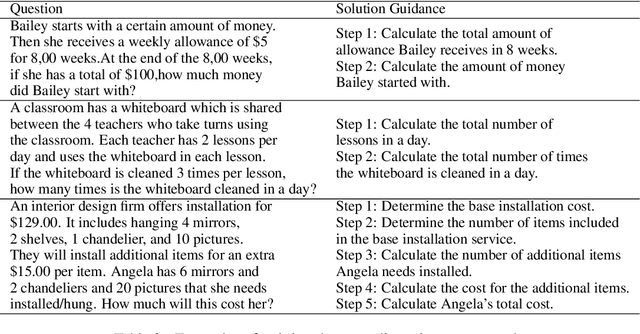
Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks. Advances in prompt engineering and fine-tuning techniques have further enhanced their ability to address complex reasoning challenges. However, these advanced capabilities are often exclusive to models exceeding 100 billion parameters. Although Chain-of-Thought (CoT) fine-tuning methods have been explored for smaller models (under 10 billion parameters), they typically depend on extensive CoT training data, which can introduce inconsistencies and limit effectiveness in low-data settings. To overcome these limitations, this paper introduce a new reasoning strategy Solution Guidance (SG) and a plug-and-play training paradigm Solution-Guidance Fine-Tuning (SGFT) for enhancing the reasoning capabilities of small language models. SG focuses on problem understanding and decomposition at the semantic and logical levels, rather than specific computations, which can effectively improve the SLMs' generalization and reasoning abilities. With only a small amount of SG training data, SGFT can fine-tune a SLM to produce accurate problem-solving guidances, which can then be flexibly fed to any SLM as prompts, enabling it to generate correct answers directly. Experimental results demonstrate that our method significantly improves the performance of SLMs on various reasoning tasks, enhancing both their practicality and efficiency within resource-constrained environments.
DRL4AOI: A DRL Framework for Semantic-aware AOI Segmentation in Location-Based Services
Dec 06, 2024



In Location-Based Services (LBS), such as food delivery, a fundamental task is segmenting Areas of Interest (AOIs), aiming at partitioning the urban geographical spaces into non-overlapping regions. Traditional AOI segmentation algorithms primarily rely on road networks to partition urban areas. While promising in modeling the geo-semantics, road network-based models overlooked the service-semantic goals (e.g., workload equality) in LBS service. In this paper, we point out that the AOI segmentation problem can be naturally formulated as a Markov Decision Process (MDP), which gradually chooses a nearby AOI for each grid in the current AOI's border. Based on the MDP, we present the first attempt to generalize Deep Reinforcement Learning (DRL) for AOI segmentation, leading to a novel DRL-based framework called DRL4AOI. The DRL4AOI framework introduces different service-semantic goals in a flexible way by treating them as rewards that guide the AOI generation. To evaluate the effectiveness of DRL4AOI, we develop and release an AOI segmentation system. We also present a representative implementation of DRL4AOI - TrajRL4AOI - for AOI segmentation in the logistics service. It introduces a Double Deep Q-learning Network (DDQN) to gradually optimize the AOI generation for two specific semantic goals: i) trajectory modularity, i.e., maximize tightness of the trajectory connections within an AOI and the sparsity of connections between AOIs, ii) matchness with the road network, i.e., maximizing the matchness between AOIs and the road network. Quantitative and qualitative experiments conducted on synthetic and real-world data demonstrate the effectiveness and superiority of our method. The code and system is publicly available at https://github.com/Kogler7/AoiOpt.
OverleafCopilot: Empowering Academic Writing in Overleaf with Large Language Models
Mar 13, 2024The rapid development of Large Language Models (LLMs) has facilitated a variety of applications from different domains. In this technical report, we explore the integration of LLMs and the popular academic writing tool, Overleaf, to enhance the efficiency and quality of academic writing. To achieve the above goal, there are three challenges: i) including seamless interaction between Overleaf and LLMs, ii) establishing reliable communication with the LLM provider, and iii) ensuring user privacy. To address these challenges, we present OverleafCopilot, the first-ever tool (i.e., a browser extension) that seamlessly integrates LLMs and Overleaf, enabling researchers to leverage the power of LLMs while writing papers. Specifically, we first propose an effective framework to bridge LLMs and Overleaf. Then, we developed PromptGenius, a website for researchers to easily find and share high-quality up-to-date prompts. Thirdly, we propose an agent command system to help researchers quickly build their customizable agents. OverleafCopilot (https://chromewebstore.google.com/detail/overleaf-copilot/eoadabdpninlhkkbhngoddfjianhlghb ) has been on the Chrome Extension Store, which now serves thousands of researchers. Additionally, the code of PromptGenius is released at https://github.com/wenhaomin/ChatGPT-PromptGenius. We believe our work has the potential to revolutionize academic writing practices, empowering researchers to produce higher-quality papers in less time.