 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRL4AOI: A DRL Framework for Semantic-aware AOI Segmentation in Location-Based Services
Dec 06, 2024



In Location-Based Services (LBS), such as food delivery, a fundamental task is segmenting Areas of Interest (AOIs), aiming at partitioning the urban geographical spaces into non-overlapping regions. Traditional AOI segmentation algorithms primarily rely on road networks to partition urban areas. While promising in modeling the geo-semantics, road network-based models overlooked the service-semantic goals (e.g., workload equality) in LBS service. In this paper, we point out that the AOI segmentation problem can be naturally formulated as a Markov Decision Process (MDP), which gradually chooses a nearby AOI for each grid in the current AOI's border. Based on the MDP, we present the first attempt to generalize Deep Reinforcement Learning (DRL) for AOI segmentation, leading to a novel DRL-based framework called DRL4AOI. The DRL4AOI framework introduces different service-semantic goals in a flexible way by treating them as rewards that guide the AOI generation. To evaluate the effectiveness of DRL4AOI, we develop and release an AOI segmentation system. We also present a representative implementation of DRL4AOI - TrajRL4AOI - for AOI segmentation in the logistics service. It introduces a Double Deep Q-learning Network (DDQN) to gradually optimize the AOI generation for two specific semantic goals: i) trajectory modularity, i.e., maximize tightness of the trajectory connections within an AOI and the sparsity of connections between AOIs, ii) matchness with the road network, i.e., maximizing the matchness between AOIs and the road network. Quantitative and qualitative experiments conducted on synthetic and real-world data demonstrate the effectiveness and superiority of our method. The code and system is publicly available at https://github.com/Kogler7/AoiOpt.
Tensor Composition Net for Visual Relationship Prediction
Dec 10, 2020



We present a novel Tensor Composition Network (TCN) to predict visual relationships in images. Visual Relationships in subject-predicate-object form provide a more powerful query modality than simple image tags. However Visual Relationship Prediction (VRP) also provides a more challenging test of image understanding than conventional image tagging, and is difficult to learn due to a large label-space and incomplete annotation. The key idea of our TCN is to exploit the low rank property of the visual relationship tensor, so as to leverage correlations within and across objects and relationships, and make a structured prediction of all objects and their relations in an image. To show the effectiveness of our method, we first empirically compare our model with multi-label classification alternatives on VRP, and show that our model outperforms state-of-the-art MLIC methods. We then show that, thanks to our tensor (de)composition layer, our model can predict visual relationships which have not been seen in training dataset. We finally show our TCN's image-level visual relationship prediction provides a simple and efficient mechanism for relation-based image retrieval.
Deep Comparison: Relation Columns for Few-Shot Learning
Nov 20, 2018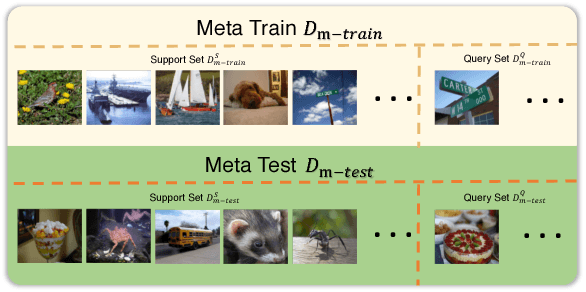
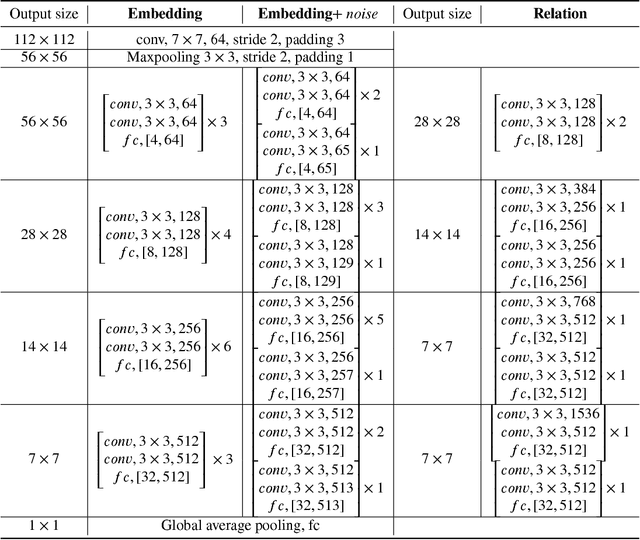
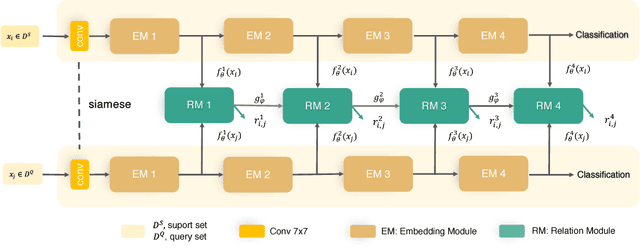
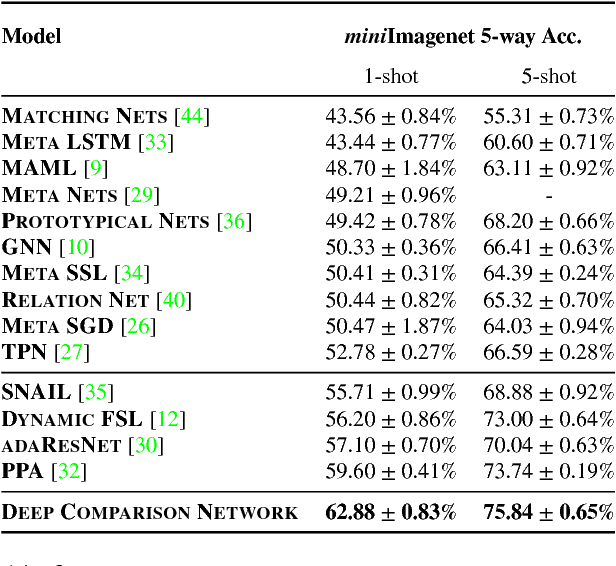
Few-shot deep learning is a topical challenge area for scaling visual recognition to open-ended growth in the space of categories to recognise. A promising line work towards realising this vision is deep networks that learn to match queries with stored training images. However, methods in this paradigm usually train a deep embedding followed by a single linear classifier. Our insight is that effective general-purpose matching requires discrimination with regards to features at multiple abstraction levels. We therefore propose a new framework termed Deep Comparison Network(DCN) that decomposes embedding learning into a sequence of modules, and pairs each with a relation module. The relation modules compute a non-linear metric to score the match using the corresponding embedding module's representation. To ensure that all embedding module's features are used, the relation modules are deeply supervised. Finally generalisation is further improved by a learned noise regulariser. The resulting network achieves state of the art performance on both miniImageNet and tieredImageNet, while retaining the appealing simplicity and efficiency of deep metric learning approaches.
Learning to Generate Posters of Scientific Papers
Apr 05, 2016
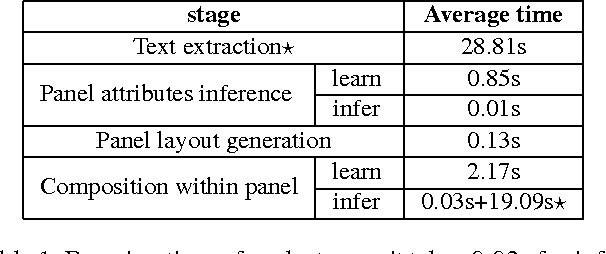
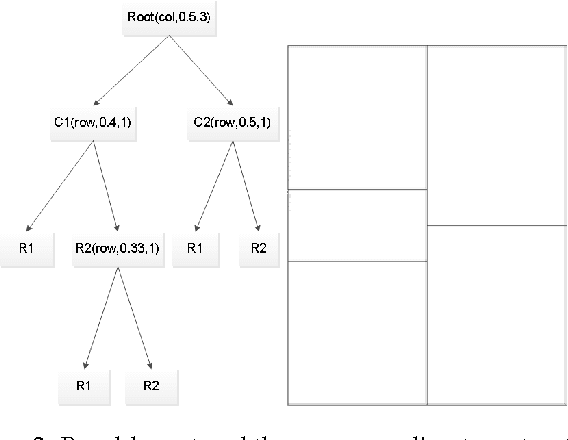

Researchers often summarize their work in the form of posters. Posters provide a coherent and efficient way to convey core ideas from scientific papers. Generating a good scientific poster, however, is a complex and time consuming cognitive task, since such posters need to be readable, informative, and visually aesthetic. In this paper, for the first time, we study the challenging problem of learning to generate posters from scientific papers. To this end, a data-driven framework, that utilizes graphical models, is proposed. Specifically, given content to display, the key elements of a good poster, including panel layout and attributes of each panel, are learned and inferred from data. Then, given inferred layout and attributes, composition of graphical elements within each panel is synthesized. To learn and validate our model, we collect and make public a Poster-Paper dataset, which consists of scientific papers and corresponding posters with exhaustively labelled panels and attributes. Qualitative and quantitative results indicate the effectiveness of our approach.