 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRL4AOI: A DRL Framework for Semantic-aware AOI Segmentation in Location-Based Services
Dec 06, 2024



In Location-Based Services (LBS), such as food delivery, a fundamental task is segmenting Areas of Interest (AOIs), aiming at partitioning the urban geographical spaces into non-overlapping regions. Traditional AOI segmentation algorithms primarily rely on road networks to partition urban areas. While promising in modeling the geo-semantics, road network-based models overlooked the service-semantic goals (e.g., workload equality) in LBS service. In this paper, we point out that the AOI segmentation problem can be naturally formulated as a Markov Decision Process (MDP), which gradually chooses a nearby AOI for each grid in the current AOI's border. Based on the MDP, we present the first attempt to generalize Deep Reinforcement Learning (DRL) for AOI segmentation, leading to a novel DRL-based framework called DRL4AOI. The DRL4AOI framework introduces different service-semantic goals in a flexible way by treating them as rewards that guide the AOI generation. To evaluate the effectiveness of DRL4AOI, we develop and release an AOI segmentation system. We also present a representative implementation of DRL4AOI - TrajRL4AOI - for AOI segmentation in the logistics service. It introduces a Double Deep Q-learning Network (DDQN) to gradually optimize the AOI generation for two specific semantic goals: i) trajectory modularity, i.e., maximize tightness of the trajectory connections within an AOI and the sparsity of connections between AOIs, ii) matchness with the road network, i.e., maximizing the matchness between AOIs and the road network. Quantitative and qualitative experiments conducted on synthetic and real-world data demonstrate the effectiveness and superiority of our method. The code and system is publicly available at https://github.com/Kogler7/AoiOpt.
DataGpt-SQL-7B: An Open-Source Language Model for Text-to-SQL
Sep 24, 2024

In addressing the pivotal role of translating natural language queries into SQL commands, we propose a suite of compact, fine-tuned models and self-refine mechanisms to democratize data access and analysis for non-expert users, mitigating risks associated with closed-source Large Language Models. Specifically, we constructed a dataset of over 20K sample for Text-to-SQL as well as the preference dateset, to improve the efficiency in the domain of SQL generation. To further ensure code validity, a code corrector was integrated into the model. Our system, DataGpt-sql, achieved 87.2\% accuracy on the spider-dev, respectively, showcasing the effectiveness of our solution in text-to-SQL conversion tasks. Our code, data, and models are available at \url{https://github.com/CainiaoTechAi/datagpt-sql-7b}
Differentiation of Multi-objective Data-driven Decision Pipeline
Jun 02, 2024Real-world scenarios frequently involve multi-objective data-driven optimization problems, characterized by unknown problem coefficients and multiple conflicting objectives. Traditional two-stage methods independently apply a machine learning model to estimate problem coefficients, followed by invoking a solver to tackle the predicted optimization problem. The independent use of optimization solvers and prediction models may lead to suboptimal performance due to mismatches between their objectives. Recent efforts have focused on end-to-end training of predictive models that use decision loss derived from the downstream optimization problem. However, these methods have primarily focused on single-objective optimization problems, thus limiting their applicability. We aim to propose a multi-objective decision-focused approach to address this gap. In order to better align with the inherent properties of multi-objective optimization problems, we propose a set of novel loss functions. These loss functions are designed to capture the discrepancies between predicted and true decision problems, considering solution space, objective space, and decision quality, named landscape loss, Pareto set loss, and decision loss, respectively. Our experimental results demonstrate that our proposed method significantly outperforms traditional two-stage methods and most current decision-focused methods.
Robust Representation Learning for Unified Online Top-K Recommendation
Oct 24, 2023



In large-scale industrial e-commerce, the efficiency of an online recommendation system is crucial in delivering highly relevant item/content advertising that caters to diverse business scenarios. However, most existing studies focus solely on item advertising, neglecting the significance of content advertising. This oversight results in inconsistencies within the multi-entity structure and unfair retrieval. Furthermore, the challenge of retrieving top-k advertisements from multi-entity advertisements across different domains adds to the complexity. Recent research proves that user-entity behaviors within different domains exhibit characteristics of differentiation and homogeneity. Therefore, the multi-domain matching models typically rely on the hybrid-experts framework with domain-invariant and domain-specific representations. Unfortunately, most approaches primarily focus on optimizing the combination mode of different experts, failing to address the inherent difficulty in optimizing the expert modules themselves. The existence of redundant information across different domains introduces interference and competition among experts, while the distinct learning objectives of each domain lead to varying optimization challenges among experts. To tackle these issues, we propose robust representation learning for the unified online top-k recommendation. Our approach constructs unified modeling in entity space to ensure data fairness. The robust representation learning employs domain adversarial learning and multi-view wasserstein distribution learning to learn robust representations. Moreover, the proposed method balances conflicting objectives through the homoscedastic uncertainty weights and orthogonality constraints. Various experiments validate the effectiveness and rationality of our proposed method, which has been successfully deployed online to serve real business scenarios.
A Survey on Service Route and Time Prediction in Instant Delivery: Taxonomy, Progress, and Prospects
Sep 03, 2023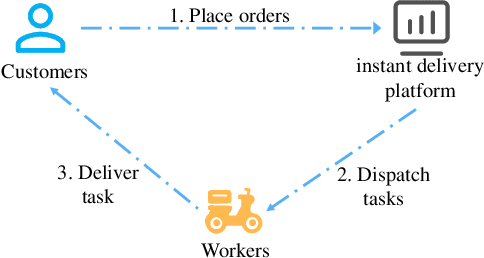
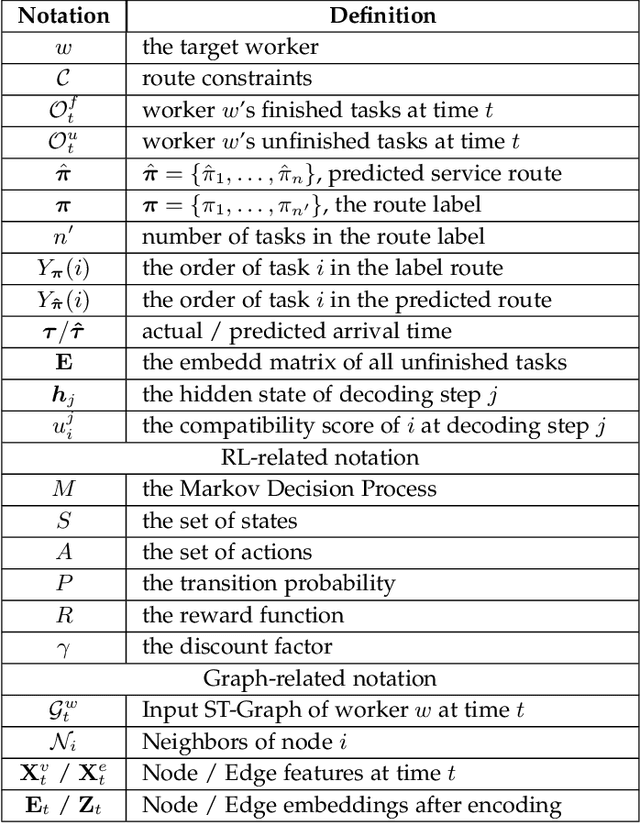
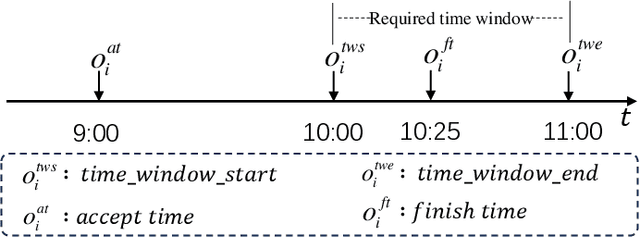
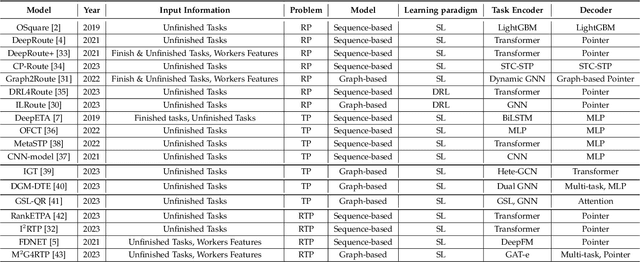
Instant delivery services, such as food delivery and package delivery, have achieved explosive growth in recent years by providing customers with daily-life convenience. An emerging research area within these services is service Route\&Time Prediction (RTP), which aims to estimate the future service route as well as the arrival time of a given worker. As one of the most crucial tasks in those service platforms, RTP stands central to enhancing user satisfaction and trimming operational expenditures on these platforms. Despite a plethora of algorithms developed to date, there is no systematic, comprehensive survey to guide researchers in this domain. To fill this gap, our work presents the first comprehensive survey that methodically categorizes recent advances in service route and time prediction. We start by defining the RTP challenge and then delve into the metrics that are often employed. Following that, we scrutinize the existing RTP methodologies, presenting a novel taxonomy of them. We categorize these methods based on three criteria: (i) type of task, subdivided into only-route prediction, only-time prediction, and joint route\&time prediction; (ii) model architecture, which encompasses sequence-based and graph-based models; and (iii) learning paradigm, including Supervised Learning (SL) and Deep Reinforcement Learning (DRL). Conclusively, we highlight the limitations of current research and suggest prospective avenues. We believe that the taxonomy, progress, and prospects introduced in this paper can significantly promote the development of this field.
DRL4Route: A Deep Reinforcement Learning Framework for Pick-up and Delivery Route Prediction
Jul 30, 2023



Pick-up and Delivery Route Prediction (PDRP), which aims to estimate the future service route of a worker given his current task pool, has received rising attention in recent years. Deep neural networks based on supervised learning have emerged as the dominant model for the task because of their powerful ability to capture workers' behavior patterns from massive historical data. Though promising, they fail to introduce the non-differentiable test criteria into the training process, leading to a mismatch in training and test criteria. Which considerably trims down their performance when applied in practical systems. To tackle the above issue, we present the first attempt to generalize Reinforcement Learning (RL) to the route prediction task, leading to a novel RL-based framework called DRL4Route. It combines the behavior-learning abilities of previous deep learning models with the non-differentiable objective optimization ability of reinforcement learning. DRL4Route can serve as a plug-and-play component to boost the existing deep learning models. Based on the framework, we further implement a model named DRL4Route-GAE for PDRP in logistic service. It follows the actor-critic architecture which is equipped with a Generalized Advantage Estimator that can balance the bias and variance of the policy gradient estimates, thus achieving a more optimal policy. Extensive offline experiments and the online deployment show that DRL4Route-GAE improves Location Square Deviation (LSD) by 0.9%-2.7%, and Accuracy@3 (ACC@3) by 2.4%-3.2% over existing methods on the real-world dataset.
LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry
Jun 19, 2023



Real-world last-mile delivery datasets are crucial for research in logistics, supply chain management, and spatio-temporal data mining. Despite a plethora of algorithms developed to date, no widely accepted, publicly available last-mile delivery dataset exists to support research in this field. In this paper, we introduce \texttt{LaDe}, the first publicly available last-mile delivery dataset with millions of packages from the industry. LaDe has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation. (2) Comprehensive information. It offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen. (3) Diversity. The dataset includes data from various scenarios, including package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations. We verify LaDe on three tasks by running several classical baseline models per task. We believe that the large-scale, comprehensive, diverse feature of LaDe can offer unparalleled opportunities to researchers in the supply chain community, data mining community, and beyond. The dataset homepage is publicly available at https://huggingface.co/datasets/Cainiao-AI/LaDe.
G2PTL: A Pre-trained Model for Delivery Address and its Applications in Logistics System
Apr 04, 2023



Text-based delivery addresses, as the data foundation for logistics systems, contain abundant and crucial location information. How to effectively encode the delivery address is a core task to boost the performance of downstream tasks in the logistics system. Pre-trained Models (PTMs) designed for Natural Language Process (NLP) have emerged as the dominant tools for encoding semantic information in text. Though promising, those NLP-based PTMs fall short of encoding geographic knowledge in the delivery address, which considerably trims down the performance of delivery-related tasks in logistic systems such as Cainiao. To tackle the above problem, we propose a domain-specific pre-trained model, named G2PTL, a Geography-Graph Pre-trained model for delivery address in Logistics field. G2PTL combines the semantic learning capabilities of text pre-training with the geographical-relationship encoding abilities of graph modeling. Specifically, we first utilize real-world logistics delivery data to construct a large-scale heterogeneous graph of delivery addresses, which contains abundant geographic knowledge and delivery information. Then, G2PTL is pre-trained with subgraphs sampled from the heterogeneous graph. Comprehensive experiments are conducted to demonstrate the effectiveness of G2PTL through four downstream tasks in logistics systems on real-world datasets. G2PTL has been deployed in production in Cainiao's logistics system, which significantly improves the performance of delivery-related tasks.
AdaptDHM: Adaptive Distribution Hierarchical Model for Multi-Domain CTR Prediction
Nov 22, 2022



Large-scale commercial platforms usually involve numerous business domains for diverse business strategies and expect their recommendation systems to provide click-through rate (CTR) predictions for multiple domains simultaneously. Existing promising and widely-used multi-domain models discover domain relationships by explicitly constructing domain-specific networks, but the computation and memory boost significantly with the increase of domains. To reduce computational complexity, manually grouping domains with particular business strategies is common in industrial applications. However, this pre-defined data partitioning way heavily relies on prior knowledge, and it may neglect the underlying data distribution of each domain, hence limiting the model's representation capability. Regarding the above issues, we propose an elegant and flexible multi-distribution modeling paradigm, named Adaptive Distribution Hierarchical Model (AdaptDHM), which is an end-to-end optimization hierarchical structure consisting of a clustering process and classification process. Specifically, we design a distribution adaptation module with a customized dynamic routing mechanism. Instead of introducing prior knowledge for pre-defined data allocation, this routing algorithm adaptively provides a distribution coefficient for each sample to determine which cluster it belongs to. Each cluster corresponds to a particular distribution so that the model can sufficiently capture the commonalities and distinctions between these distinct clusters. Extensive experiments on both public and large-scale Alibaba industrial datasets verify the effectiveness and efficiency of AdaptDHM: Our model achieves impressive prediction accuracy and its time cost during the training stage is more than 50% less than that of other models.
An end-to-end predict-then-optimize clustering method for intelligent assignment problems in express systems
Feb 18, 2022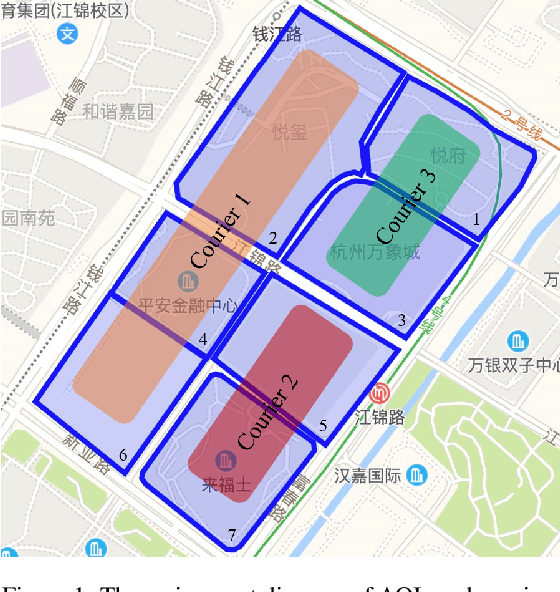
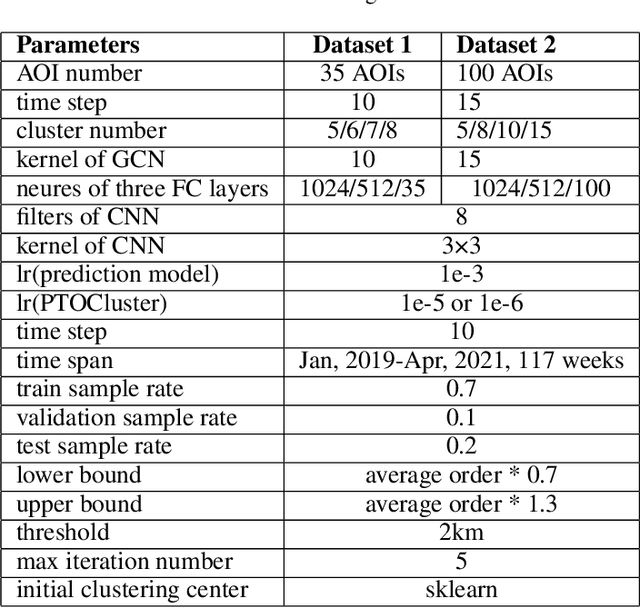
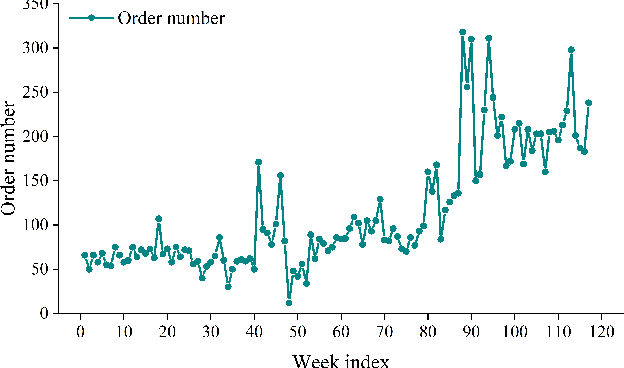

Express systems play important roles in modern major cities. Couriers serving for the express system pick up packages in certain areas of interest (AOI) during a specific time. However, future pick-up requests vary significantly with time. While the assignment results are generally static without changing with time. Using the historical pick-up request number to conduct AOI assignment (or pick-up request assignment) for couriers is thus unreasonable. Moreover, even we can first predict future pick-up requests and then use the prediction results to conduct the assignments, this kind of two-stage method is also impractical and trivial, and exists some drawbacks, such as the best prediction results might not ensure the best clustering results. To solve these problems, we put forward an intelligent end-to-end predict-then-optimize clustering method to simultaneously predict the future pick-up requests of AOIs and assign AOIs to couriers by clustering. At first, we propose a deep learning-based prediction model to predict order numbers on AOIs. Then a differential constrained K-means clustering method is introduced to cluster AOIs based on the prediction results. We finally propose a one-stage end-to-end predict-then-optimize clustering method to assign AOIs to couriers reasonably, dynamically, and intelligently. Results show that this kind of one-stage predict-then-optimize method is beneficial to improve the performance of optimization results, namely the clustering results. This study can provide critical experiences for predict-and-optimize related tasks and intelligent assignment problems in express systems.