 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaST: Efficient and Effective Long-Horizon Forecasting for Large-Scale Spatial-Temporal Graphs via Mixture-of-Experts
Jan 08, 2026Spatial-Temporal Graph (STG) forecasting on large-scale networks has garnered significant attention. However, existing models predominantly focus on short-horizon predictions and suffer from notorious computational costs and memory consumption when scaling to long-horizon predictions and large graphs. Targeting the above challenges, we present FaST, an effective and efficient framework based on heterogeneity-aware Mixture-of-Experts (MoEs) for long-horizon and large-scale STG forecasting, which unlocks one-week-ahead (672 steps at a 15-minute granularity) prediction with thousands of nodes. FaST is underpinned by two key innovations. First, an adaptive graph agent attention mechanism is proposed to alleviate the computational burden inherent in conventional graph convolution and self-attention modules when applied to large-scale graphs. Second, we propose a new parallel MoE module that replaces traditional feed-forward networks with Gated Linear Units (GLUs), enabling an efficient and scalable parallel structure. Extensive experiments on real-world datasets demonstrate that FaST not only delivers superior long-horizon predictive accuracy but also achieves remarkable computational efficiency compared to state-of-the-art baselines. Our source code is available at: https://github.com/yijizhao/FaST.
T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models
May 05, 2025Text-to-Time Series generation holds significant potential to address challenges such as data sparsity, imbalance, and limited availability of multimodal time series datasets across domains. While diffusion models have achieved remarkable success in Text-to-X (e.g., vision and audio data) generation, their use in time series generation remains in its nascent stages. Existing approaches face two critical limitations: (1) the lack of systematic exploration of general-proposed time series captions, which are often domain-specific and struggle with generalization; and (2) the inability to generate time series of arbitrary lengths, limiting their applicability to real-world scenarios. In this work, we first categorize time series captions into three levels: point-level, fragment-level, and instance-level. Additionally, we introduce a new fragment-level dataset containing over 600,000 high-resolution time series-text pairs. Second, we propose Text-to-Series (T2S), a diffusion-based framework that bridges the gap between natural language and time series in a domain-agnostic manner. T2S employs a length-adaptive variational autoencoder to encode time series of varying lengths into consistent latent embeddings. On top of that, T2S effectively aligns textual representations with latent embeddings by utilizing Flow Matching and employing Diffusion Transformer as the denoiser. We train T2S in an interleaved paradigm across multiple lengths, allowing it to generate sequences of any desired length. Extensive evaluations demonstrate that T2S achieves state-of-the-art performance across 13 datasets spanning 12 domains.
A Survey on Service Route and Time Prediction in Instant Delivery: Taxonomy, Progress, and Prospects
Sep 03, 2023
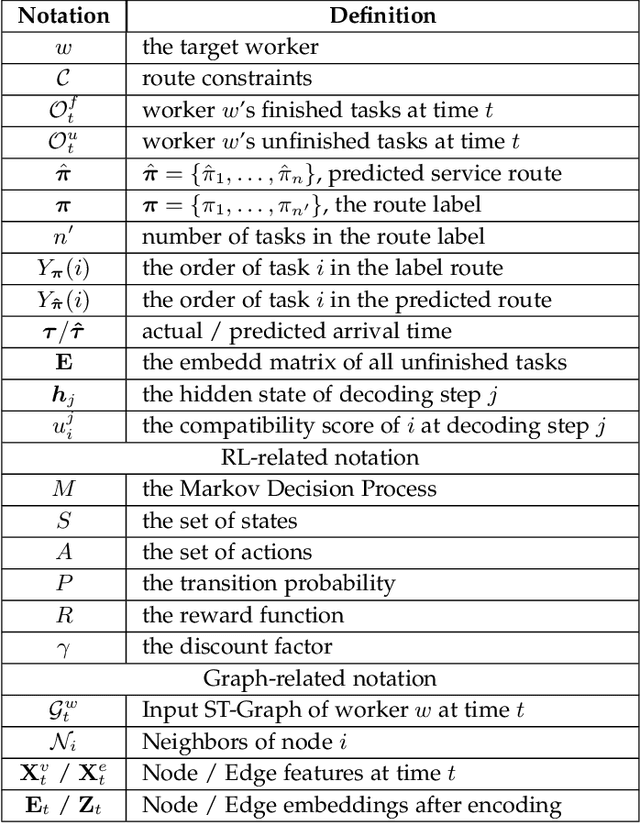
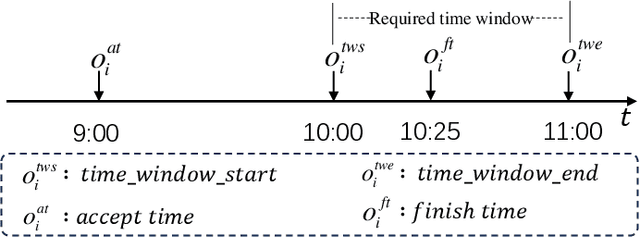
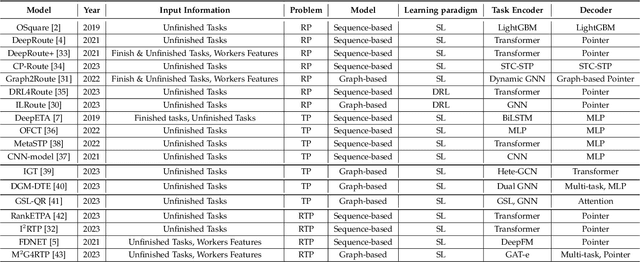
Instant delivery services, such as food delivery and package delivery, have achieved explosive growth in recent years by providing customers with daily-life convenience. An emerging research area within these services is service Route\&Time Prediction (RTP), which aims to estimate the future service route as well as the arrival time of a given worker. As one of the most crucial tasks in those service platforms, RTP stands central to enhancing user satisfaction and trimming operational expenditures on these platforms. Despite a plethora of algorithms developed to date, there is no systematic, comprehensive survey to guide researchers in this domain. To fill this gap, our work presents the first comprehensive survey that methodically categorizes recent advances in service route and time prediction. We start by defining the RTP challenge and then delve into the metrics that are often employed. Following that, we scrutinize the existing RTP methodologies, presenting a novel taxonomy of them. We categorize these methods based on three criteria: (i) type of task, subdivided into only-route prediction, only-time prediction, and joint route\&time prediction; (ii) model architecture, which encompasses sequence-based and graph-based models; and (iii) learning paradigm, including Supervised Learning (SL) and Deep Reinforcement Learning (DRL). Conclusively, we highlight the limitations of current research and suggest prospective avenues. We believe that the taxonomy, progress, and prospects introduced in this paper can significantly promote the development of this field.