 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Does Your Reasoning Model Implicitly Know When to Stop Thinking?
Feb 09, 2026Recent advancements in large reasoning models (LRMs) have greatly improved their capabilities on complex reasoning tasks through Long Chains of Thought (CoTs). However, this approach often results in substantial redundancy, impairing computational efficiency and causing significant delays in real-time applications. Recent studies show that longer reasoning chains are frequently uncorrelated with correctness and can even be detrimental to accuracy. In a further in-depth analysis of this phenomenon, we surprisingly uncover and empirically verify that LRMs implicitly know the appropriate time to stop thinking, while this capability is obscured by current sampling paradigms. Motivated by this, we introduce SAGE (Self-Aware Guided Efficient Reasoning), a novel sampling paradigm that unleashes this efficient reasoning potential. Furthermore, integrating SAGE as mixed sampling into group-based reinforcement learning (SAGE-RL) enables SAGE-RL to effectively incorporate SAGE-discovered efficient reasoning patterns into standard pass@1 inference, markedly enhancing both the reasoning accuracy and efficiency of LRMs across multiple challenging mathematical benchmarks.
Real-Time Aligned Reward Model beyond Semantics
Jan 30, 2026Reinforcement Learning from Human Feedback (RLHF) is a pivotal technique for aligning large language models (LLMs) with human preferences, yet it is susceptible to reward overoptimization, in which policy models overfit to the reward model, exploit spurious reward patterns instead of faithfully capturing human intent. Prior mitigations primarily relies on surface semantic information and fails to efficiently address the misalignment between the reward model (RM) and the policy model caused by continuous policy distribution shifts. This inevitably leads to an increasing reward discrepancy, exacerbating reward overoptimization. To address these limitations, we introduce R2M (Real-Time Aligned Reward Model), a novel lightweight RLHF framework. R2M goes beyond vanilla reward models that solely depend on the semantic representations of a pretrained LLM. Instead, it leverages the evolving hidden states of the policy (namely policy feedback) to align with the real-time distribution shift of the policy during the RL process. This work points to a promising new direction for improving the performance of reward models through real-time utilization of feedback from policy models.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Intelligent Anti-Money Laundering Solution Based upon Novel Community Detection in Massive Transaction Networks on Spark
Jan 08, 2025Criminals are using every means available to launder the profits from their illegal activities into ostensibly legitimate assets. Meanwhile, most commercial anti-money laundering systems are still rule-based, which cannot adapt to the ever-changing tricks. Although some machine learning methods have been proposed, they are mainly focused on the perspective of abnormal behavior for single accounts. Considering money laundering activities are often involved in gang criminals, these methods are still not intelligent enough to crack down on criminal gangs all-sidedly. In this paper, a systematic solution is presented to find suspicious money laundering gangs. A temporal-directed Louvain algorithm has been proposed to detect communities according to relevant anti-money laundering patterns. All processes are implemented and optimized on Spark platform. This solution can greatly improve the efficiency of anti-money laundering work for financial regulation agencies.
Trajectory Consistency Distillation
Feb 29, 2024



Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. To address this limitation, we initially delve into and elucidate the underlying causes. Our investigation identifies that the primary issue stems from errors in three distinct areas. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the distillation errors by broadening the scope of the self-consistency boundary condition and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE. Additionally, strategic stochastic sampling is specifically designed to circumvent the accumulated errors inherent in multi-step consistency sampling, which is meticulously tailored to complement the TCD model. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
One More Step: A Versatile Plug-and-Play Module for Rectifying Diffusion Schedule Flaws and Enhancing Low-Frequency Controls
Nov 27, 2023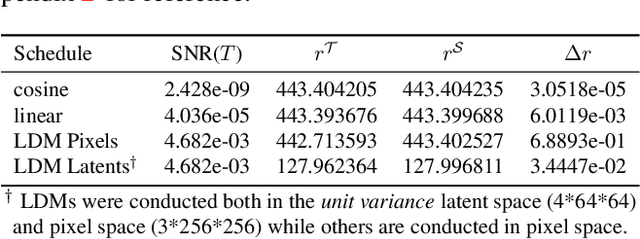
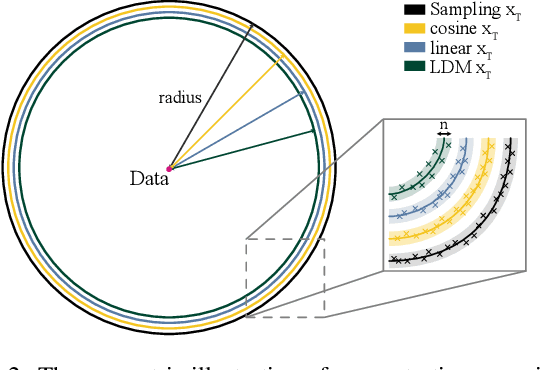
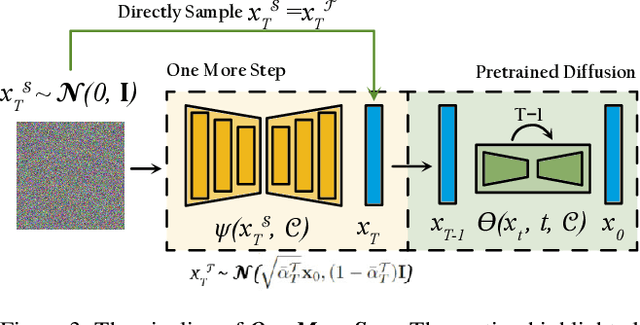
It is well known that many open-released foundational diffusion models have difficulty in generating images that substantially depart from average brightness, despite such images being present in the training data. This is due to an inconsistency: while denoising starts from pure Gaussian noise during inference, the training noise schedule retains residual data even in the final timestep distribution, due to difficulties in numerical conditioning in mainstream formulation, leading to unintended bias during inference. To mitigate this issue, certain $\epsilon$-prediction models are combined with an ad-hoc offset-noise methodology. In parallel, some contemporary models have adopted zero-terminal SNR noise schedules together with $\mathbf{v}$-prediction, which necessitate major alterations to pre-trained models. However, such changes risk destabilizing a large multitude of community-driven applications anchored on these pre-trained models. In light of this, our investigation revisits the fundamental causes, leading to our proposal of an innovative and principled remedy, called One More Step (OMS). By integrating a compact network and incorporating an additional simple yet effective step during inference, OMS elevates image fidelity and harmonizes the dichotomy between training and inference, while preserving original model parameters. Once trained, various pre-trained diffusion models with the same latent domain can share the same OMS module.
DRL4Route: A Deep Reinforcement Learning Framework for Pick-up and Delivery Route Prediction
Jul 30, 2023



Pick-up and Delivery Route Prediction (PDRP), which aims to estimate the future service route of a worker given his current task pool, has received rising attention in recent years. Deep neural networks based on supervised learning have emerged as the dominant model for the task because of their powerful ability to capture workers' behavior patterns from massive historical data. Though promising, they fail to introduce the non-differentiable test criteria into the training process, leading to a mismatch in training and test criteria. Which considerably trims down their performance when applied in practical systems. To tackle the above issue, we present the first attempt to generalize Reinforcement Learning (RL) to the route prediction task, leading to a novel RL-based framework called DRL4Route. It combines the behavior-learning abilities of previous deep learning models with the non-differentiable objective optimization ability of reinforcement learning. DRL4Route can serve as a plug-and-play component to boost the existing deep learning models. Based on the framework, we further implement a model named DRL4Route-GAE for PDRP in logistic service. It follows the actor-critic architecture which is equipped with a Generalized Advantage Estimator that can balance the bias and variance of the policy gradient estimates, thus achieving a more optimal policy. Extensive offline experiments and the online deployment show that DRL4Route-GAE improves Location Square Deviation (LSD) by 0.9%-2.7%, and Accuracy@3 (ACC@3) by 2.4%-3.2% over existing methods on the real-world dataset.
Cocktail: Mixing Multi-Modality Controls for Text-Conditional Image Generation
Jun 01, 2023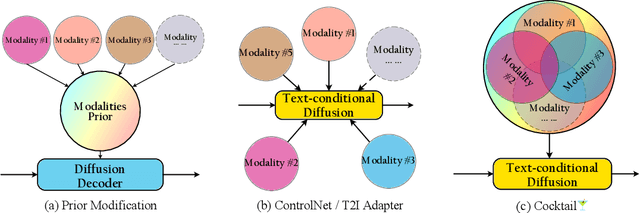

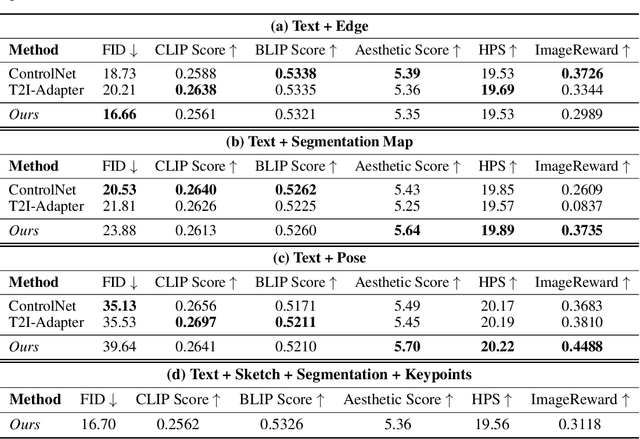
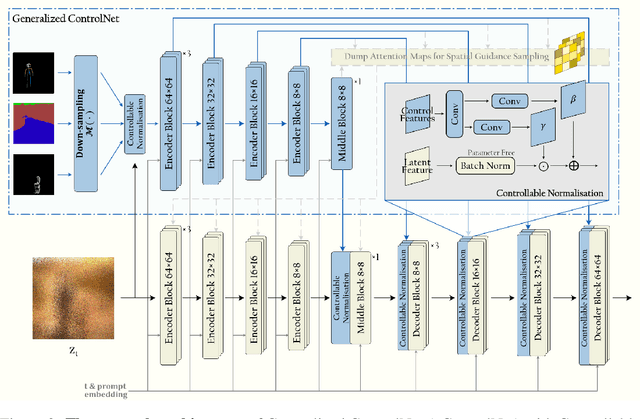
Text-conditional diffusion models are able to generate high-fidelity images with diverse contents. However, linguistic representations frequently exhibit ambiguous descriptions of the envisioned objective imagery, requiring the incorporation of additional control signals to bolster the efficacy of text-guided diffusion models. In this work, we propose Cocktail, a pipeline to mix various modalities into one embedding, amalgamated with a generalized ControlNet (gControlNet), a controllable normalisation (ControlNorm), and a spatial guidance sampling method, to actualize multi-modal and spatially-refined control for text-conditional diffusion models. Specifically, we introduce a hyper-network gControlNet, dedicated to the alignment and infusion of the control signals from disparate modalities into the pre-trained diffusion model. gControlNet is capable of accepting flexible modality signals, encompassing the simultaneous reception of any combination of modality signals, or the supplementary fusion of multiple modality signals. The control signals are then fused and injected into the backbone model according to our proposed ControlNorm. Furthermore, our advanced spatial guidance sampling methodology proficiently incorporates the control signal into the designated region, thereby circumventing the manifestation of undesired objects within the generated image. We demonstrate the results of our method in controlling various modalities, proving high-quality synthesis and fidelity to multiple external signals.
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
May 10, 2023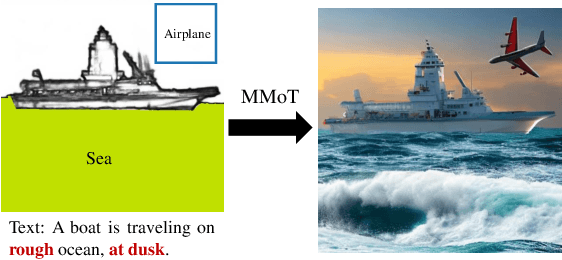
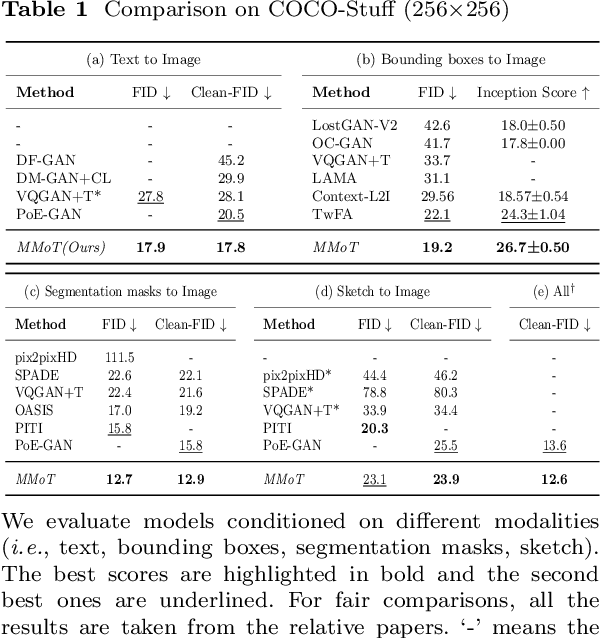
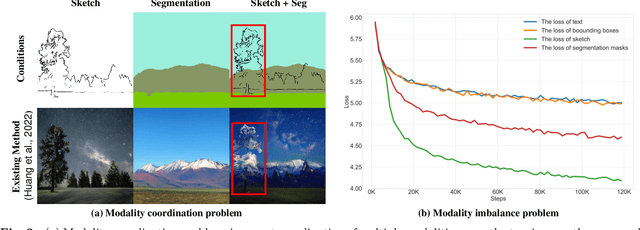
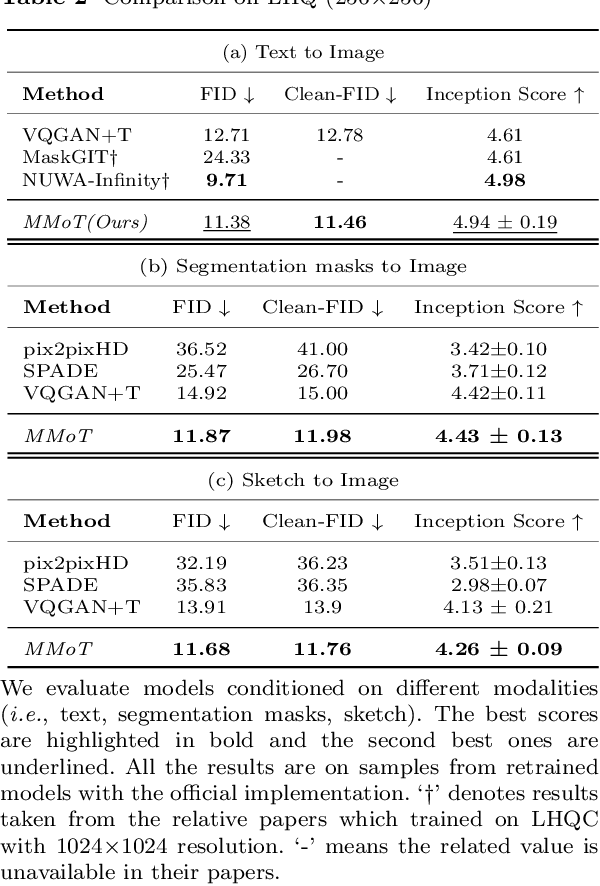
Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.