 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
Paper and Code
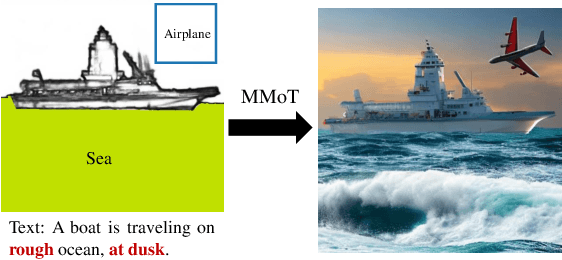
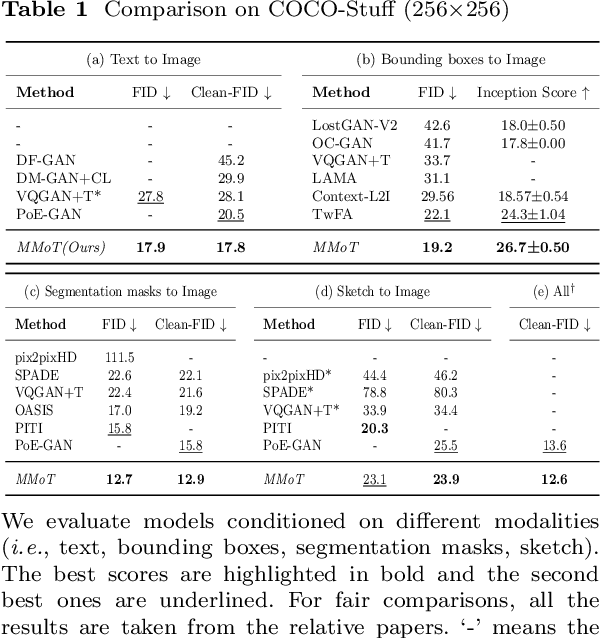
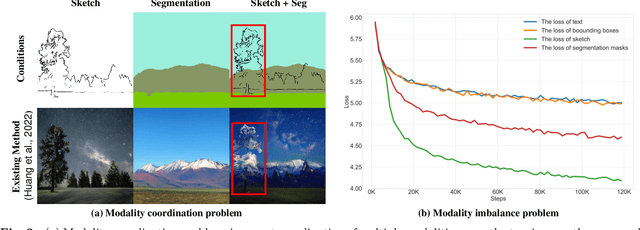
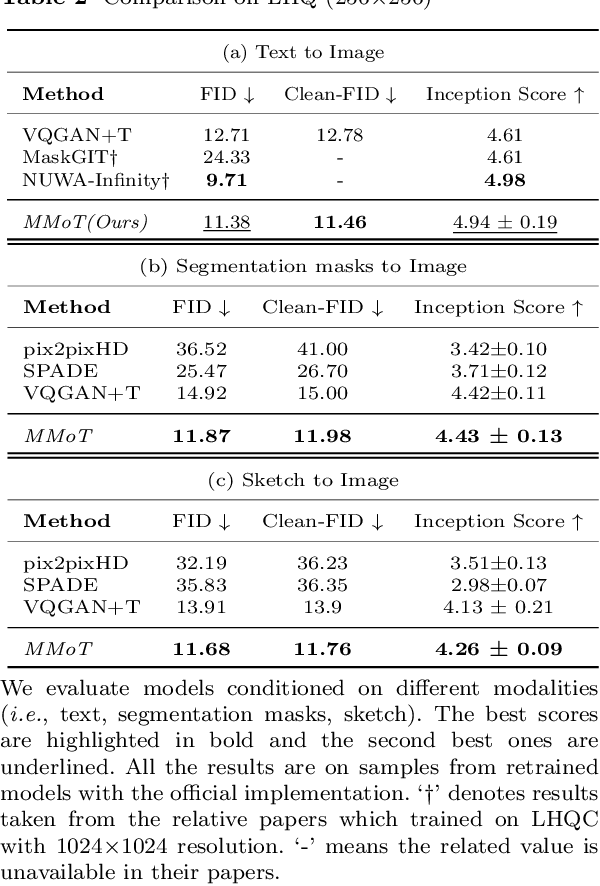
Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.