 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Normal Estimation via Shading Sequence Estimation
Feb 11, 2026Monocular normal estimation aims to estimate the normal map from a single RGB image of an object under arbitrary lights. Existing methods rely on deep models to directly predict normal maps. However, they often suffer from 3D misalignment: while the estimated normal maps may appear to have a correct appearance, the reconstructed surfaces often fail to align with the geometric details. We argue that this misalignment stems from the current paradigm: the model struggles to distinguish and reconstruct varying geometry represented in normal maps, as the differences in underlying geometry are reflected only through relatively subtle color variations. To address this issue, we propose a new paradigm that reformulates normal estimation as shading sequence estimation, where shading sequences are more sensitive to various geometric information. Building on this paradigm, we present RoSE, a method that leverages image-to-video generative models to predict shading sequences. The predicted shading sequences are then converted into normal maps by solving a simple ordinary least-squares problem. To enhance robustness and better handle complex objects, RoSE is trained on a synthetic dataset, MultiShade, with diverse shapes, materials, and light conditions. Experiments demonstrate that RoSE achieves state-of-the-art performance on real-world benchmark datasets for object-based monocular normal estimation.
Semantix: An Energy Guided Sampler for Semantic Style Transfer
Mar 28, 2025
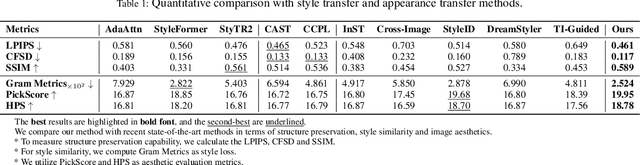
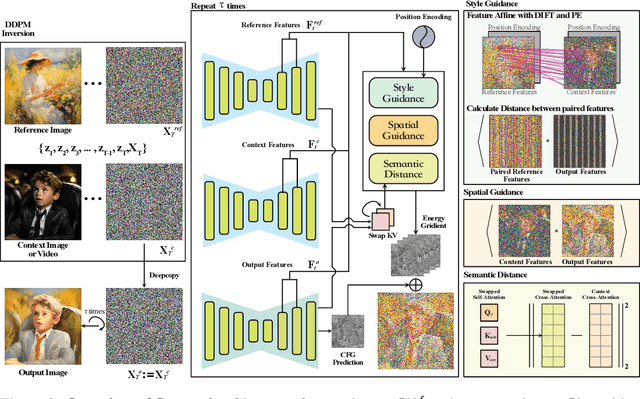
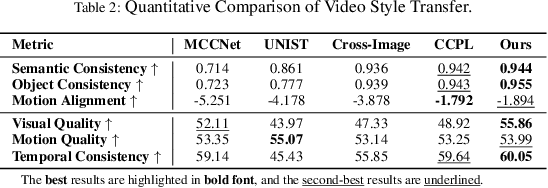
Recent advances in style and appearance transfer are impressive, but most methods isolate global style and local appearance transfer, neglecting semantic correspondence. Additionally, image and video tasks are typically handled in isolation, with little focus on integrating them for video transfer. To address these limitations, we introduce a novel task, Semantic Style Transfer, which involves transferring style and appearance features from a reference image to a target visual content based on semantic correspondence. We subsequently propose a training-free method, Semantix an energy-guided sampler designed for Semantic Style Transfer that simultaneously guides both style and appearance transfer based on semantic understanding capacity of pre-trained diffusion models. Additionally, as a sampler, Semantix be seamlessly applied to both image and video models, enabling semantic style transfer to be generic across various visual media. Specifically, once inverting both reference and context images or videos to noise space by SDEs, Semantix utilizes a meticulously crafted energy function to guide the sampling process, including three key components: Style Feature Guidance, Spatial Feature Guidance and Semantic Distance as a regularisation term. Experimental results demonstrate that Semantix not only effectively accomplishes the task of semantic style transfer across images and videos, but also surpasses existing state-of-the-art solutions in both fields. The project website is available at https://huiang-he.github.io/semantix/
Incremental Online Learning of Randomized Neural Network with Forward Regularization
Dec 17, 2024Online learning of deep neural networks suffers from challenges such as hysteretic non-incremental updating, increasing memory usage, past retrospective retraining, and catastrophic forgetting. To alleviate these drawbacks and achieve progressive immediate decision-making, we propose a novel Incremental Online Learning (IOL) process of Randomized Neural Networks (Randomized NN), a framework facilitating continuous improvements to Randomized NN performance in restrictive online scenarios. Within the framework, we further introduce IOL with ridge regularization (-R) and IOL with forward regularization (-F). -R generates stepwise incremental updates without retrospective retraining and avoids catastrophic forgetting. Moreover, we substituted -R with -F as it enhanced precognition learning ability using semi-supervision and realized better online regrets to offline global experts compared to -R during IOL. The algorithms of IOL for Randomized NN with -R/-F on non-stationary batch stream were derived respectively, featuring recursive weight updates and variable learning rates. Additionally, we conducted a detailed analysis and theoretically derived relative cumulative regret bounds of the Randomized NN learners with -R/-F in IOL under adversarial assumptions using a novel methodology and presented several corollaries, from which we observed the superiority on online learning acceleration and regret bounds of employing -F in IOL. Finally, our proposed methods were rigorously examined across regression and classification tasks on diverse datasets, which distinctly validated the efficacy of IOL frameworks of Randomized NN and the advantages of forward regularization.
Connecting Consistency Distillation to Score Distillation for Text-to-3D Generation
Jul 18, 2024Although recent advancements in text-to-3D generation have significantly improved generation quality, issues like limited level of detail and low fidelity still persist, which requires further improvement. To understand the essence of those issues, we thoroughly analyze current score distillation methods by connecting theories of consistency distillation to score distillation. Based on the insights acquired through analysis, we propose an optimization framework, Guided Consistency Sampling (GCS), integrated with 3D Gaussian Splatting (3DGS) to alleviate those issues. Additionally, we have observed the persistent oversaturation in the rendered views of generated 3D assets. From experiments, we find that it is caused by unwanted accumulated brightness in 3DGS during optimization. To mitigate this issue, we introduce a Brightness-Equalized Generation (BEG) scheme in 3DGS rendering. Experimental results demonstrate that our approach generates 3D assets with more details and higher fidelity than state-of-the-art methods. The codes are released at https://github.com/LMozart/ECCV2024-GCS-BEG.
Trajectory Consistency Distillation
Feb 29, 2024



Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. To address this limitation, we initially delve into and elucidate the underlying causes. Our investigation identifies that the primary issue stems from errors in three distinct areas. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the distillation errors by broadening the scope of the self-consistency boundary condition and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE. Additionally, strategic stochastic sampling is specifically designed to circumvent the accumulated errors inherent in multi-step consistency sampling, which is meticulously tailored to complement the TCD model. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
One More Step: A Versatile Plug-and-Play Module for Rectifying Diffusion Schedule Flaws and Enhancing Low-Frequency Controls
Nov 27, 2023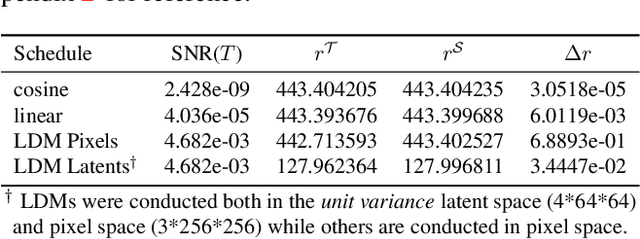
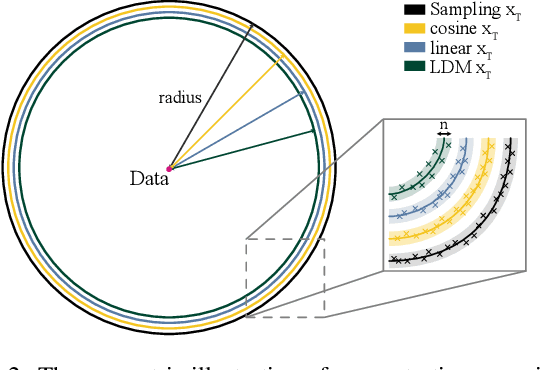
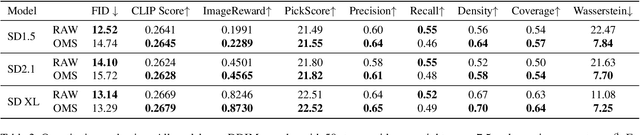
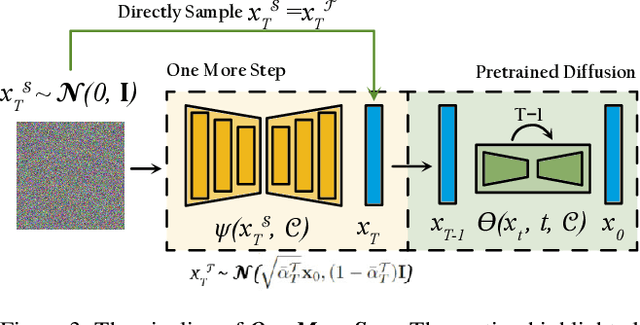
It is well known that many open-released foundational diffusion models have difficulty in generating images that substantially depart from average brightness, despite such images being present in the training data. This is due to an inconsistency: while denoising starts from pure Gaussian noise during inference, the training noise schedule retains residual data even in the final timestep distribution, due to difficulties in numerical conditioning in mainstream formulation, leading to unintended bias during inference. To mitigate this issue, certain $\epsilon$-prediction models are combined with an ad-hoc offset-noise methodology. In parallel, some contemporary models have adopted zero-terminal SNR noise schedules together with $\mathbf{v}$-prediction, which necessitate major alterations to pre-trained models. However, such changes risk destabilizing a large multitude of community-driven applications anchored on these pre-trained models. In light of this, our investigation revisits the fundamental causes, leading to our proposal of an innovative and principled remedy, called One More Step (OMS). By integrating a compact network and incorporating an additional simple yet effective step during inference, OMS elevates image fidelity and harmonizes the dichotomy between training and inference, while preserving original model parameters. Once trained, various pre-trained diffusion models with the same latent domain can share the same OMS module.
Cocktail: Mixing Multi-Modality Controls for Text-Conditional Image Generation
Jun 01, 2023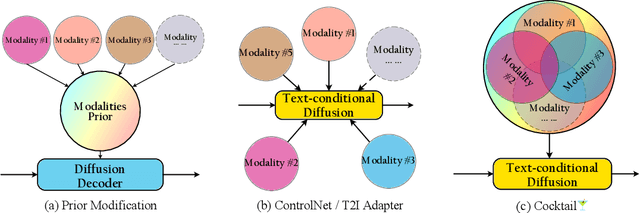

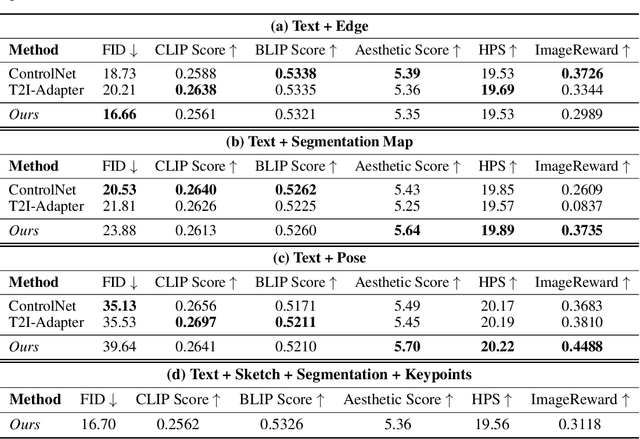
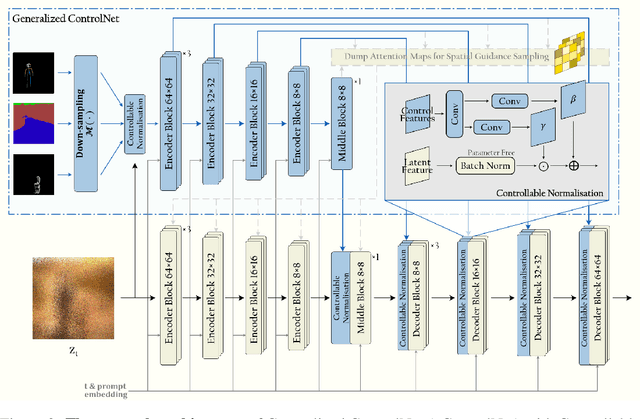
Text-conditional diffusion models are able to generate high-fidelity images with diverse contents. However, linguistic representations frequently exhibit ambiguous descriptions of the envisioned objective imagery, requiring the incorporation of additional control signals to bolster the efficacy of text-guided diffusion models. In this work, we propose Cocktail, a pipeline to mix various modalities into one embedding, amalgamated with a generalized ControlNet (gControlNet), a controllable normalisation (ControlNorm), and a spatial guidance sampling method, to actualize multi-modal and spatially-refined control for text-conditional diffusion models. Specifically, we introduce a hyper-network gControlNet, dedicated to the alignment and infusion of the control signals from disparate modalities into the pre-trained diffusion model. gControlNet is capable of accepting flexible modality signals, encompassing the simultaneous reception of any combination of modality signals, or the supplementary fusion of multiple modality signals. The control signals are then fused and injected into the backbone model according to our proposed ControlNorm. Furthermore, our advanced spatial guidance sampling methodology proficiently incorporates the control signal into the designated region, thereby circumventing the manifestation of undesired objects within the generated image. We demonstrate the results of our method in controlling various modalities, proving high-quality synthesis and fidelity to multiple external signals.
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
May 10, 2023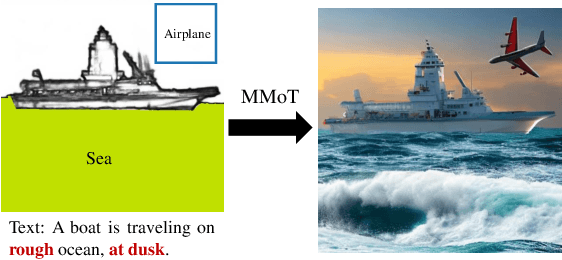
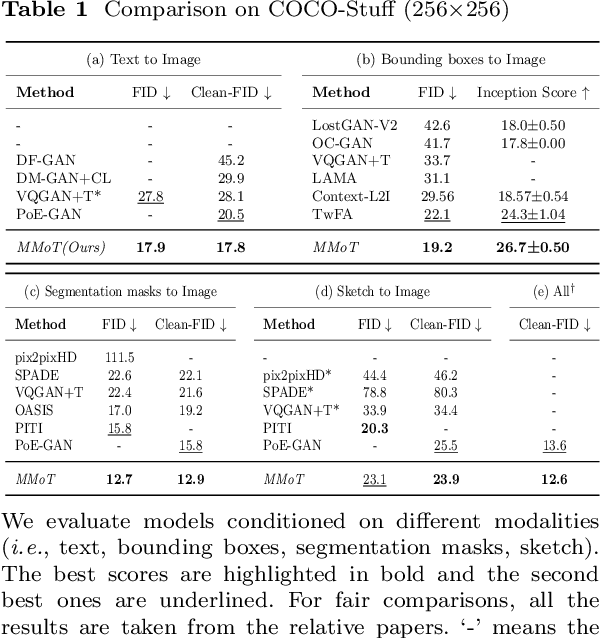
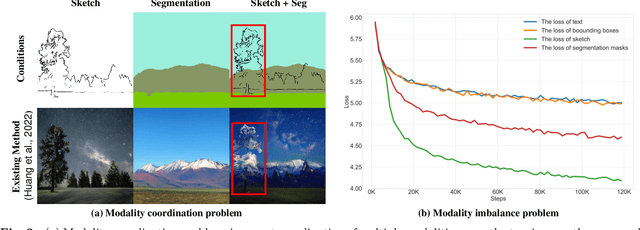
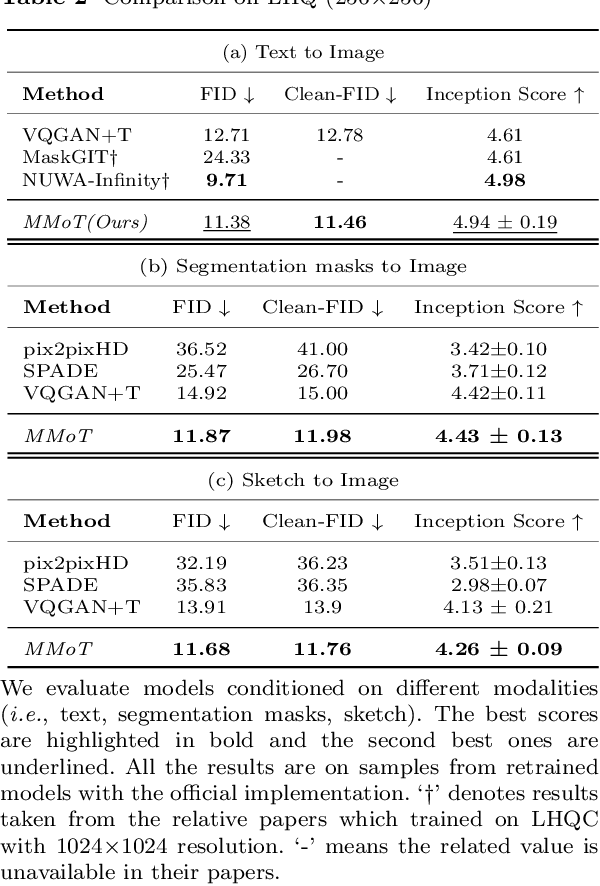
Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.
Unified Discrete Diffusion for Simultaneous Vision-Language Generation
Nov 27, 2022



The recently developed discrete diffusion models perform extraordinarily well in the text-to-image task, showing significant promise for handling the multi-modality signals. In this work, we harness these traits and present a unified multimodal generation model that can conduct both the "modality translation" and "multi-modality generation" tasks using a single model, performing text-based, image-based, and even vision-language simultaneous generation. Specifically, we unify the discrete diffusion process for multimodal signals by proposing a unified transition matrix. Moreover, we design a mutual attention module with fused embedding layer and a unified objective function to emphasise the inter-modal linkages, which are vital for multi-modality generation. Extensive experiments indicate that our proposed method can perform comparably to the state-of-the-art solutions in various generation tasks.
Global Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation
Dec 03, 2021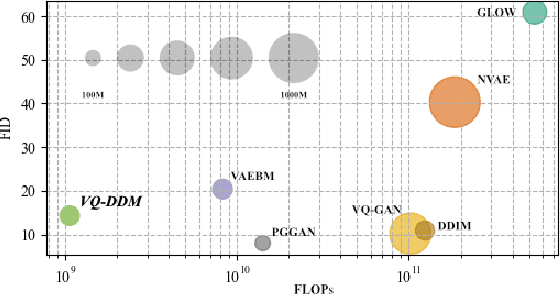
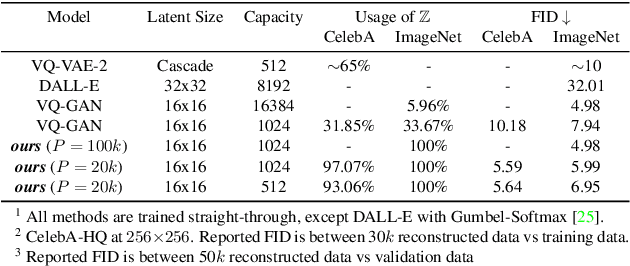
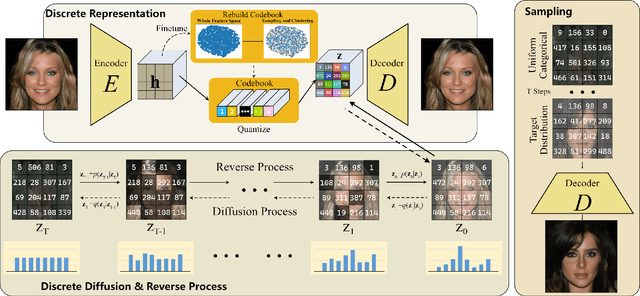
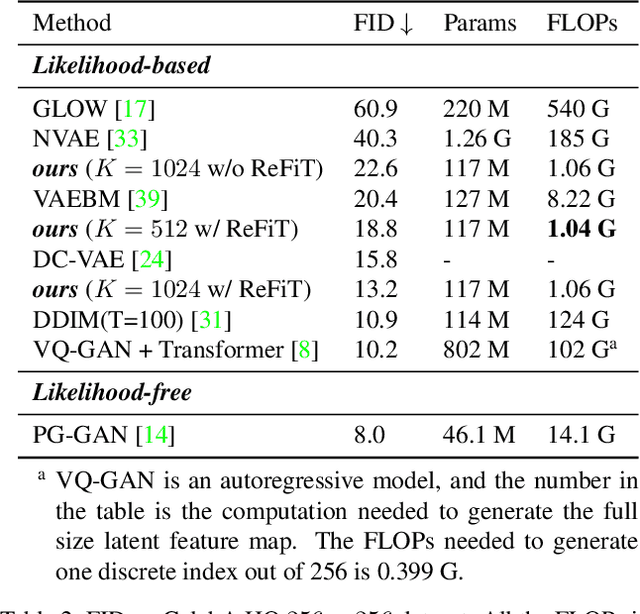
The integration of Vector Quantised Variational AutoEncoder (VQ-VAE) with autoregressive models as generation part has yielded high-quality results on image generation. However, the autoregressive models will strictly follow the progressive scanning order during the sampling phase. This leads the existing VQ series models to hardly escape the trap of lacking global information. Denoising Diffusion Probabilistic Models (DDPM) in the continuous domain have shown a capability to capture the global context, while generating high-quality images. In the discrete state space, some works have demonstrated the potential to perform text generation and low resolution image generation. We show that with the help of a content-rich discrete visual codebook from VQ-VAE, the discrete diffusion model can also generate high fidelity images with global context, which compensates for the deficiency of the classical autoregressive model along pixel space. Meanwhile, the integration of the discrete VAE with the diffusion model resolves the drawback of conventional autoregressive models being oversized, and the diffusion model which demands excessive time in the sampling process when generating images. It is found that the quality of the generated images is heavily dependent on the discrete visual codebook. Extensive experiments demonstrate that the proposed Vector Quantised Discrete Diffusion Model (VQ-DDM) is able to achieve comparable performance to top-tier methods with low complexity. It also demonstrates outstanding advantages over other vectors quantised with autoregressive models in terms of image inpainting tasks without additional training.