 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOS-Bench: A Comprehensive Benchmark for Earth Observation Satellite Scheduling
Apr 28, 2026Earth observation satellite imaging scheduling is a challenging NP-hard combinatorial optimisation problem central to space mission operations. While next-generation agile Earth observation satellites (EOS) increase operational flexibility, they also significantly raise scheduling complexity. The lack of a unified, open-source benchmark makes it difficult to compare algorithms across studies. This paper introduces EOS-Bench, a comprehensive framework for systematic and reproducible evaluation of scheduling methods. By integrating high-fidelity orbital dynamics and platform constraints, EOS-Bench generates 1,390 scenarios and 13,900 benchmark instances, spanning from small-scale validation cases to large coordination problems with up to 1,000 satellites and 10,000 requests. We further propose a scenario characterisation scheme to quantify structural difficulty based on factors such as opportunity density, task flexibility, conflict intensity, and satellite congestion. A multidimensional evaluation protocol is introduced, assessing performance across five metrics: task profit, completion rate, workload balance, timeliness, and runtime. The framework is evaluated using mixed-integer programming, heuristics, meta-heuristics, and deep reinforcement learning across both agile and non-agile settings. Results show that EOS-Bench effectively distinguishes solver performance across scales and conditions, revealing trade-offs between solution quality and computational efficiency, and providing deeper insight into scenario complexity. EOS-Bench offers a unified and extensible open testbed for advancing research in Earth observation satellite scheduling. The code and data are available at https://github.com/Ethan19YQ/EOS-Bench.
Adaptive Hierarchical Graph Cut for Multi-granularity Out-of-distribution Detection
Dec 20, 2024This paper focuses on a significant yet challenging task: out-of-distribution detection (OOD detection), which aims to distinguish and reject test samples with semantic shifts, so as to prevent models trained on in-distribution (ID) data from producing unreliable predictions. Although previous works have made decent success, they are ineffective for real-world challenging applications since these methods simply regard all unlabeled data as OOD data and ignore the case that different datasets have different label granularity. For example, "cat" on CIFAR-10 and "tabby cat" on Tiny-ImageNet share the same semantics but have different labels due to various label granularity. To this end, in this paper, we propose a novel Adaptive Hierarchical Graph Cut network (AHGC) to deeply explore the semantic relationship between different images. Specifically, we construct a hierarchical KNN graph to evaluate the similarities between different images based on the cosine similarity. Based on the linkage and density information of the graph, we cut the graph into multiple subgraphs to integrate these semantics-similar samples. If the labeled percentage in a subgraph is larger than a threshold, we will assign the label with the highest percentage to unlabeled images. To further improve the model generalization, we augment each image into two augmentation versions, and maximize the similarity between the two versions. Finally, we leverage the similarity score for OOD detection. Extensive experiments on two challenging benchmarks (CIFAR- 10 and CIFAR-100) illustrate that in representative cases, AHGC outperforms state-of-the-art OOD detection methods by 81.24% on CIFAR-100 and by 40.47% on CIFAR-10 in terms of "FPR95", which shows the effectiveness of our AHGC.
Incremental Online Learning of Randomized Neural Network with Forward Regularization
Dec 17, 2024Online learning of deep neural networks suffers from challenges such as hysteretic non-incremental updating, increasing memory usage, past retrospective retraining, and catastrophic forgetting. To alleviate these drawbacks and achieve progressive immediate decision-making, we propose a novel Incremental Online Learning (IOL) process of Randomized Neural Networks (Randomized NN), a framework facilitating continuous improvements to Randomized NN performance in restrictive online scenarios. Within the framework, we further introduce IOL with ridge regularization (-R) and IOL with forward regularization (-F). -R generates stepwise incremental updates without retrospective retraining and avoids catastrophic forgetting. Moreover, we substituted -R with -F as it enhanced precognition learning ability using semi-supervision and realized better online regrets to offline global experts compared to -R during IOL. The algorithms of IOL for Randomized NN with -R/-F on non-stationary batch stream were derived respectively, featuring recursive weight updates and variable learning rates. Additionally, we conducted a detailed analysis and theoretically derived relative cumulative regret bounds of the Randomized NN learners with -R/-F in IOL under adversarial assumptions using a novel methodology and presented several corollaries, from which we observed the superiority on online learning acceleration and regret bounds of employing -F in IOL. Finally, our proposed methods were rigorously examined across regression and classification tasks on diverse datasets, which distinctly validated the efficacy of IOL frameworks of Randomized NN and the advantages of forward regularization.
Your Data Is Not Perfect: Towards Cross-Domain Out-of-Distribution Detection in Class-Imbalanced Data
Dec 09, 2024Previous OOD detection systems only focus on the semantic gap between ID and OOD samples. Besides the semantic gap, we are faced with two additional gaps: the domain gap between source and target domains, and the class-imbalance gap between different classes. In fact, similar objects from different domains should belong to the same class. In this paper, we introduce a realistic yet challenging setting: class-imbalanced cross-domain OOD detection (CCOD), which contains a well-labeled (but usually small) source set for training and conducts OOD detection on an unlabeled (but usually larger) target set for testing. We do not assume that the target domain contains only OOD classes or that it is class-balanced: the distribution among classes of the target dataset need not be the same as the source dataset. To tackle this challenging setting with an OOD detection system, we propose a novel uncertainty-aware adaptive semantic alignment (UASA) network based on a prototype-based alignment strategy. Specifically, we first build label-driven prototypes in the source domain and utilize these prototypes for target classification to close the domain gap. Rather than utilizing fixed thresholds for OOD detection, we generate adaptive sample-wise thresholds to handle the semantic gap. Finally, we conduct uncertainty-aware clustering to group semantically similar target samples to relieve the class-imbalance gap. Extensive experiments on three challenging benchmarks demonstrate that our proposed UASA outperforms state-of-the-art methods by a large margin.
Harnessing Smartphone Sensors for Enhanced Road Safety: A Comprehensive Dataset and Review
Nov 13, 2024Severe collisions can result from aggressive driving and poor road conditions, emphasizing the need for effective monitoring to ensure safety. Smartphones, with their array of built-in sensors, offer a practical and affordable solution for road-sensing. However, the lack of reliable, standardized datasets has hindered progress in assessing road conditions and driving patterns. This study addresses this gap by introducing a comprehensive dataset derived from smartphone sensors, which surpasses existing datasets by incorporating a diverse range of sensors including accelerometer, gyroscope, magnetometer, GPS, gravity, orientation, and uncalibrated sensors. These sensors capture extensive parameters such as acceleration force, gravitation, rotation rate, magnetic field strength, and vehicle speed, providing a detailed understanding of road conditions and driving behaviors. The dataset is designed to enhance road safety, infrastructure maintenance, traffic management, and urban planning. By making this dataset available to the community, the study aims to foster collaboration, inspire further research, and facilitate the development of innovative solutions in intelligent transportation systems.
Vanilla Gradient Descent for Oblique Decision Trees
Aug 22, 2024Decision Trees (DTs) constitute one of the major highly non-linear AI models, valued, e.g., for their efficiency on tabular data. Learning accurate DTs is, however, complicated, especially for oblique DTs, and does take a significant training time. Further, DTs suffer from overfitting, e.g., they proverbially "do not generalize" in regression tasks. Recently, some works proposed ways to make (oblique) DTs differentiable. This enables highly efficient gradient-descent algorithms to be used to learn DTs. It also enables generalizing capabilities by learning regressors at the leaves simultaneously with the decisions in the tree. Prior approaches to making DTs differentiable rely either on probabilistic approximations at the tree's internal nodes (soft DTs) or on approximations in gradient computation at the internal node (quantized gradient descent). In this work, we propose DTSemNet, a novel semantically equivalent and invertible encoding for (hard, oblique) DTs as Neural Networks (NNs), that uses standard vanilla gradient descent. Experiments across various classification and regression benchmarks show that oblique DTs learned using DTSemNet are more accurate than oblique DTs of similar size learned using state-of-the-art techniques. Further, DT training time is significantly reduced. We also experimentally demonstrate that DTSemNet can learn DT policies as efficiently as NN policies in the Reinforcement Learning (RL) setup with physical inputs (dimensions $\leq32$). The code is available at {\color{blue}\textit{\url{https://github.com/CPS-research-group/dtsemnet}}}.
A Two-stage Evolutionary Framework For Multi-objective Optimization
Jul 09, 2024In the field of evolutionary multi-objective optimization, the approximation of the Pareto front (PF) is achieved by utilizing a collection of representative candidate solutions that exhibit desirable convergence and diversity. Although several multi-objective evolutionary algorithms (MOEAs) have been designed, they still have difficulties in keeping balance between convergence and diversity of population. To better solve multi-objective optimization problems (MOPs), this paper proposes a Two-stage Evolutionary Framework For Multi-objective Optimization (TEMOF). Literally, algorithms are divided into two stages to enhance the search capability of the population. During the initial half of evolutions, parental selection is exclusively conducted from the primary population. Additionally, we not only perform environmental selection on the current population, but we also establish an external archive to store individuals situated on the first PF. Subsequently, in the second stage, parents are randomly chosen either from the population or the archive. In the experiments, one classic MOEA and two state-of-the-art MOEAs are integrated into the framework to form three new algorithms. The experimental results demonstrate the superior and robust performance of the proposed framework across a wide range of MOPs. Besides, the winner among three new algorithms is compared with several existing MOEAs and shows better results. Meanwhile, we conclude the reasons that why the two-stage framework is effect for the existing benchmark functions.
IF2Net: Innately Forgetting-Free Networks for Continual Learning
Jun 18, 2023Continual learning can incrementally absorb new concepts without interfering with previously learned knowledge. Motivated by the characteristics of neural networks, in which information is stored in weights on connections, we investigated how to design an Innately Forgetting-Free Network (IF2Net) for continual learning context. This study proposed a straightforward yet effective learning paradigm by ingeniously keeping the weights relative to each seen task untouched before and after learning a new task. We first presented the novel representation-level learning on task sequences with random weights. This technique refers to tweaking the drifted representations caused by randomization back to their separate task-optimal working states, but the involved weights are frozen and reused (opposite to well-known layer-wise updates of weights). Then, sequential decision-making without forgetting can be achieved by projecting the output weight updates into the parsimonious orthogonal space, making the adaptations not disturb old knowledge while maintaining model plasticity. IF2Net allows a single network to inherently learn unlimited mapping rules without telling task identities at test time by integrating the respective strengths of randomization and orthogonalization. We validated the effectiveness of our approach in the extensive theoretical analysis and empirical study.
SFE: A Simple, Fast and Efficient Feature Selection Algorithm for High-Dimensional Data
Mar 17, 2023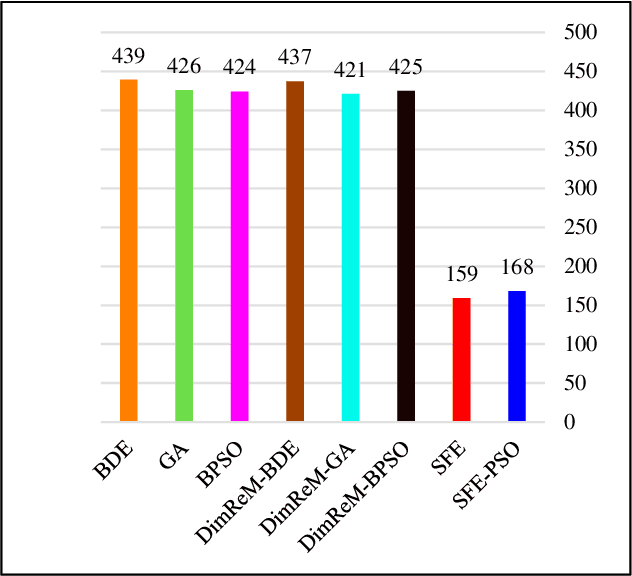

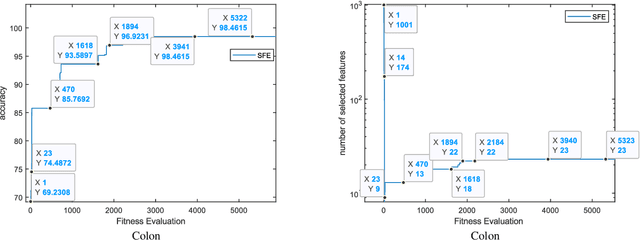
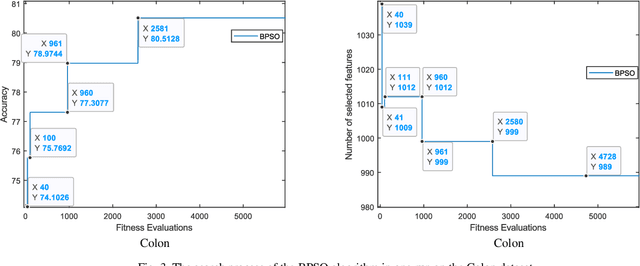
In this paper, a new feature selection algorithm, called SFE (Simple, Fast, and Efficient), is proposed for high-dimensional datasets. The SFE algorithm performs its search process using a search agent and two operators: non-selection and selection. It comprises two phases: exploration and exploitation. In the exploration phase, the non-selection operator performs a global search in the entire problem search space for the irrelevant, redundant, trivial, and noisy features, and changes the status of the features from selected mode to non-selected mode. In the exploitation phase, the selection operator searches the problem search space for the features with a high impact on the classification results, and changes the status of the features from non-selected mode to selected mode. The proposed SFE is successful in feature selection from high-dimensional datasets. However, after reducing the dimensionality of a dataset, its performance cannot be increased significantly. In these situations, an evolutionary computational method could be used to find a more efficient subset of features in the new and reduced search space. To overcome this issue, this paper proposes a hybrid algorithm, SFE-PSO (particle swarm optimization) to find an optimal feature subset. The efficiency and effectiveness of the SFE and the SFE-PSO for feature selection are compared on 40 high-dimensional datasets. Their performances were compared with six recently proposed feature selection algorithms. The results obtained indicate that the two proposed algorithms significantly outperform the other algorithms, and can be used as efficient and effective algorithms in selecting features from high-dimensional datasets.
Weighting and Pruning based Ensemble Deep Random Vector Functional Link Network for Tabular Data Classification
Jan 21, 2022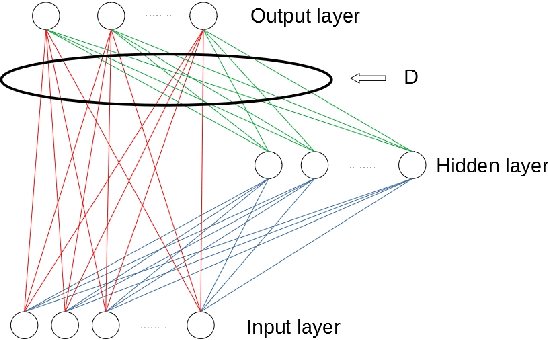



In this paper, we first introduce batch normalization to the edRVFL network. This re-normalization method can help the network avoid divergence of the hidden features. Then we propose novel variants of Ensemble Deep Random Vector Functional Link (edRVFL). Weighted edRVFL (WedRVFL) uses weighting methods to give training samples different weights in different layers according to how the samples were classified confidently in the previous layer thereby increasing the ensemble's diversity and accuracy. Furthermore, a pruning-based edRVFL (PedRVFL) has also been proposed. We prune some inferior neurons based on their importance for classification before generating the next hidden layer. Through this method, we ensure that the randomly generated inferior features will not propagate to deeper layers. Subsequently, the combination of weighting and pruning, called Weighting and Pruning based Ensemble Deep Random Vector Functional Link Network (WPedRVFL), is proposed. We compare their performances with other state-of-the-art deep feedforward neural networks (FNNs) on 24 tabular UCI classification datasets. The experimental results illustrate the superior performance of our proposed methods.