 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesCartes Builder: A Tool to Develop Machine-Learning Based Digital Twins
Aug 25, 2025Digital twins (DTs) are increasingly utilized to monitor, manage, and optimize complex systems across various domains, including civil engineering. A core requirement for an effective DT is to act as a fast, accurate, and maintainable surrogate of its physical counterpart, the physical twin (PT). To this end, machine learning (ML) is frequently employed to (i) construct real-time DT prototypes using efficient reduced-order models (ROMs) derived from high-fidelity simulations of the PT's nominal behavior, and (ii) specialize these prototypes into DT instances by leveraging historical sensor data from the target PT. Despite the broad applicability of ML, its use in DT engineering remains largely ad hoc. Indeed, while conventional ML pipelines often train a single model for a specific task, DTs typically require multiple, task- and domain-dependent models. Thus, a more structured approach is required to design DTs. In this paper, we introduce DesCartes Builder, an open-source tool to enable the systematic engineering of ML-based pipelines for real-time DT prototypes and DT instances. The tool leverages an open and flexible visual data flow paradigm to facilitate the specification, composition, and reuse of ML models. It also integrates a library of parameterizable core operations and ML algorithms tailored for DT design. We demonstrate the effectiveness and usability of DesCartes Builder through a civil engineering use case involving the design of a real-time DT prototype to predict the plastic strain of a structure.
Adaptive Hierarchical Graph Cut for Multi-granularity Out-of-distribution Detection
Dec 20, 2024This paper focuses on a significant yet challenging task: out-of-distribution detection (OOD detection), which aims to distinguish and reject test samples with semantic shifts, so as to prevent models trained on in-distribution (ID) data from producing unreliable predictions. Although previous works have made decent success, they are ineffective for real-world challenging applications since these methods simply regard all unlabeled data as OOD data and ignore the case that different datasets have different label granularity. For example, "cat" on CIFAR-10 and "tabby cat" on Tiny-ImageNet share the same semantics but have different labels due to various label granularity. To this end, in this paper, we propose a novel Adaptive Hierarchical Graph Cut network (AHGC) to deeply explore the semantic relationship between different images. Specifically, we construct a hierarchical KNN graph to evaluate the similarities between different images based on the cosine similarity. Based on the linkage and density information of the graph, we cut the graph into multiple subgraphs to integrate these semantics-similar samples. If the labeled percentage in a subgraph is larger than a threshold, we will assign the label with the highest percentage to unlabeled images. To further improve the model generalization, we augment each image into two augmentation versions, and maximize the similarity between the two versions. Finally, we leverage the similarity score for OOD detection. Extensive experiments on two challenging benchmarks (CIFAR- 10 and CIFAR-100) illustrate that in representative cases, AHGC outperforms state-of-the-art OOD detection methods by 81.24% on CIFAR-100 and by 40.47% on CIFAR-10 in terms of "FPR95", which shows the effectiveness of our AHGC.
Your Data Is Not Perfect: Towards Cross-Domain Out-of-Distribution Detection in Class-Imbalanced Data
Dec 09, 2024Previous OOD detection systems only focus on the semantic gap between ID and OOD samples. Besides the semantic gap, we are faced with two additional gaps: the domain gap between source and target domains, and the class-imbalance gap between different classes. In fact, similar objects from different domains should belong to the same class. In this paper, we introduce a realistic yet challenging setting: class-imbalanced cross-domain OOD detection (CCOD), which contains a well-labeled (but usually small) source set for training and conducts OOD detection on an unlabeled (but usually larger) target set for testing. We do not assume that the target domain contains only OOD classes or that it is class-balanced: the distribution among classes of the target dataset need not be the same as the source dataset. To tackle this challenging setting with an OOD detection system, we propose a novel uncertainty-aware adaptive semantic alignment (UASA) network based on a prototype-based alignment strategy. Specifically, we first build label-driven prototypes in the source domain and utilize these prototypes for target classification to close the domain gap. Rather than utilizing fixed thresholds for OOD detection, we generate adaptive sample-wise thresholds to handle the semantic gap. Finally, we conduct uncertainty-aware clustering to group semantically similar target samples to relieve the class-imbalance gap. Extensive experiments on three challenging benchmarks demonstrate that our proposed UASA outperforms state-of-the-art methods by a large margin.
Uncertainty-Guided Appearance-Motion Association Network for Out-of-Distribution Action Detection
Sep 16, 2024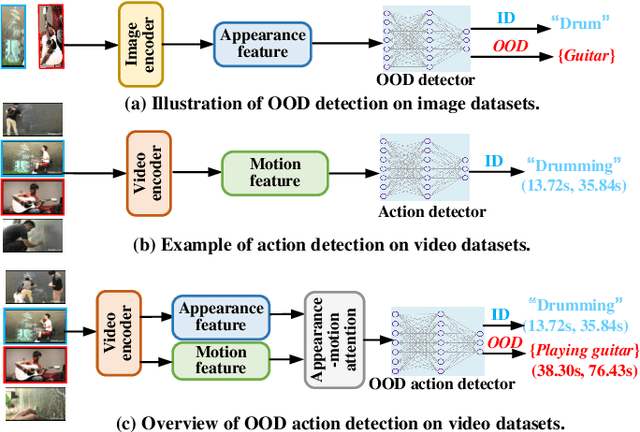
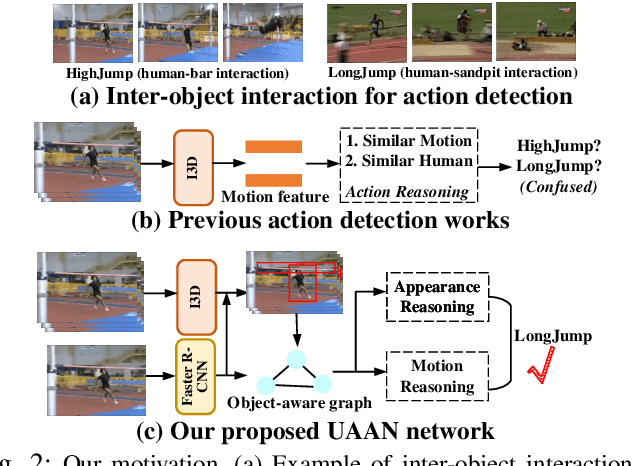
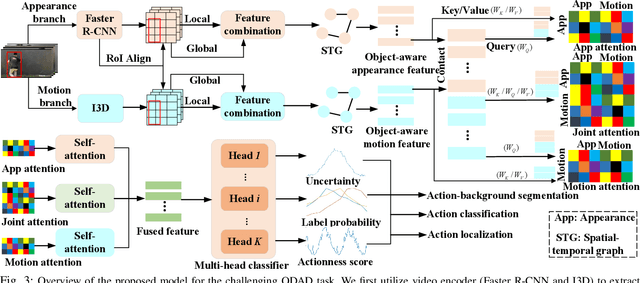
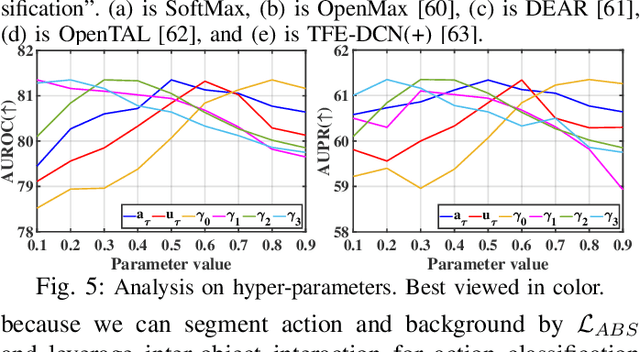
Out-of-distribution (OOD) detection targets to detect and reject test samples with semantic shifts, to prevent models trained on in-distribution (ID) dataset from producing unreliable predictions. Existing works only extract the appearance features on image datasets, and cannot handle dynamic multimedia scenarios with much motion information. Therefore, we target a more realistic and challenging OOD detection task: OOD action detection (ODAD). Given an untrimmed video, ODAD first classifies the ID actions and recognizes the OOD actions, and then localizes ID and OOD actions. To this end, in this paper, we propose a novel Uncertainty-Guided Appearance-Motion Association Network (UAAN), which explores both appearance features and motion contexts to reason spatial-temporal inter-object interaction for ODAD.Firstly, we design separate appearance and motion branches to extract corresponding appearance-oriented and motion-aspect object representations. In each branch, we construct a spatial-temporal graph to reason appearance-guided and motion-driven inter-object interaction. Then, we design an appearance-motion attention module to fuse the appearance and motion features for final action detection. Experimental results on two challenging datasets show that UAAN beats state-of-the-art methods by a significant margin, illustrating its effectiveness.
Vanilla Gradient Descent for Oblique Decision Trees
Aug 22, 2024Decision Trees (DTs) constitute one of the major highly non-linear AI models, valued, e.g., for their efficiency on tabular data. Learning accurate DTs is, however, complicated, especially for oblique DTs, and does take a significant training time. Further, DTs suffer from overfitting, e.g., they proverbially "do not generalize" in regression tasks. Recently, some works proposed ways to make (oblique) DTs differentiable. This enables highly efficient gradient-descent algorithms to be used to learn DTs. It also enables generalizing capabilities by learning regressors at the leaves simultaneously with the decisions in the tree. Prior approaches to making DTs differentiable rely either on probabilistic approximations at the tree's internal nodes (soft DTs) or on approximations in gradient computation at the internal node (quantized gradient descent). In this work, we propose DTSemNet, a novel semantically equivalent and invertible encoding for (hard, oblique) DTs as Neural Networks (NNs), that uses standard vanilla gradient descent. Experiments across various classification and regression benchmarks show that oblique DTs learned using DTSemNet are more accurate than oblique DTs of similar size learned using state-of-the-art techniques. Further, DT training time is significantly reduced. We also experimentally demonstrate that DTSemNet can learn DT policies as efficiently as NN policies in the Reinforcement Learning (RL) setup with physical inputs (dimensions $\leq32$). The code is available at {\color{blue}\textit{\url{https://github.com/CPS-research-group/dtsemnet}}}.
Function+Data Flow: A Framework to Specify Machine Learning Pipelines for Digital Twinning
Jun 28, 2024



The development of digital twins (DTs) for physical systems increasingly leverages artificial intelligence (AI), particularly for combining data from different sources or for creating computationally efficient, reduced-dimension models. Indeed, even in very different application domains, twinning employs common techniques such as model order reduction and modelization with hybrid data (that is, data sourced from both physics-based models and sensors). Despite this apparent generality, current development practices are ad-hoc, making the design of AI pipelines for digital twinning complex and time-consuming. Here we propose Function+Data Flow (FDF), a domain-specific language (DSL) to describe AI pipelines within DTs. FDF aims to facilitate the design and validation of digital twins. Specifically, FDF treats functions as first-class citizens, enabling effective manipulation of models learned with AI. We illustrate the benefits of FDF on two concrete use cases from different domains: predicting the plastic strain of a structure and modeling the electromagnetic behavior of a bearing.