 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGA: Terrain-aware Active Gaze Learning for Generalizable Agile Humanoid Locomotion
Jun 04, 2026Agile humanoid locomotion across diverse challenging terrain demands both wide perceptual coverage and precise local geometry understanding. Motivated by the way humans selectively look at relevant terrain during locomotion, we introduce TAGA, a Terrain-aware Active Gaze learning framework for Attention-based humanoid control. By fusing vision, proprioception, and motion commands, our framework guides the model to learn anticipatory cues and actively attend to specific areas of the height scan, selectively using these informative regions for the downstream network. This adaptively increases the information density of observations under tight onboard computational constraints, thus enabling fine-grained perceptive locomotion over larger-scale terrains. We find that such gaze behaviors can naturally emerge through reinforcement learning alone, without requiring additional supervision or explicit guidance, significantly improve training efficiency. As a result, the trained policy demonstrates robust and generalizable locomotion in simulation and on hardware, including reliable terrain-aware foothold selection, elevated-platform traversal, competitive sparse-foothold traversal, and the largest reported real-world gap traversal distance of 1.2m among perceptive humanoid locomotion systems, while maintaining stability under severe perceptual disturbances and environmental interference.
CROSS: A Mixture-of-Experts Reinforcement Learning Framework for Generalizable Large-Scale Traffic Signal Control
Mar 26, 2026Recent advances in robotics, automation, and artificial intelligence have enabled urban traffic systems to operate with increasing autonomy towards future smart cities, powered in part by the development of adaptive traffic signal control (ATSC), which dynamically optimizes signal phases to mitigate congestion and optimize traffic. However, achieving effective and generalizable large-scale ATSC remains a significant challenge due to the diverse intersection topologies and highly dynamic, complex traffic demand patterns across the network. Existing RL-based methods typically use a single shared policy for all scenarios, whose limited representational capacity makes it difficult to capture diverse traffic dynamics and generalize to unseen environments. To address these challenges, we propose CROSS, a novel Mixture-of-Experts (MoE)-based decentralized RL framework for generalizable ATSC. We first introduce a Predictive Contrastive Clustering (PCC) module that forecasts short-term state transitions to identify latent traffic patterns, followed by clustering and contrastive learning to enhance pattern-level representation. We further design a Scenario-Adaptive MoE module that augments a shared policy with multiple experts, thus enabling adaptive specialization and more flexible scenario-specific strategies. We conduct extensive experiments in the SUMO simulator on both synthetic and real-world traffic datasets. Compared with state-of-the-art baselines, CROSS achieves superior performance and generalization through improved representation of diverse traffic scenarios.
LATS: Large Language Model Assisted Teacher-Student Framework for Multi-Agent Reinforcement Learning in Traffic Signal Control
Mar 25, 2026Adaptive Traffic Signal Control (ATSC) aims to optimize traffic flow and minimize delays by adjusting traffic lights in real time. Recent advances in Multi-agent Reinforcement Learning (MARL) have shown promise for ATSC, yet existing approaches still suffer from limited representational capacity, often leading to suboptimal performance and poor generalization in complex and dynamic traffic environments. On the other hand, Large Language Models (LLMs) excel at semantic representation, reasoning, and analysis, yet their propensity for hallucination and slow inference speeds often hinder their direct application to decision-making tasks. To address these challenges, we propose a novel learning paradigm named LATS that integrates LLMs and MARL, leveraging the former's strong prior knowledge and inductive abilities to enhance the latter's decision-making process. Specifically, we introduce a plug-and-play teacher-student learning module, where a trained embedding LLM serves as a teacher to generate rich semantic features that capture each intersection's topology structures and traffic dynamics. A much simpler (student) neural network then learns to emulate these features through knowledge distillation in the latent space, enabling the final model to operate independently from the LLM for downstream use in the RL decision-making process. This integration significantly enhances the overall model's representational capacity across diverse traffic scenarios, thus leading to more efficient and generalizable control strategies. Extensive experiments across diverse traffic datasets empirically demonstrate that our method enhances the representation learning capability of RL models, thereby leading to improved overall performance and generalization over both traditional RL and LLM-only approaches. [...]
CAMO: A Conditional Neural Solver for the Multi-objective Multiple Traveling Salesman Problem
Mar 19, 2026Robotic systems often require a team of robots to collectively visit multiple targets while optimizing competing objectives, such as total travel cost and makespan. This setting can be formulated as the Multi-Objective Multiple Traveling Salesman Problem (MOMTSP). Although learning-based methods have shown strong performance on the single-agent TSP and multi-objective TSP variants, they rarely address the combined challenges of multi-agent coordination and multi-objective trade-offs, which introduce dual sources of complexity. To bridge this gap, we propose CAMO, a conditional neural solver for MOMTSP that generalizes across varying numbers of targets, agents, and preference vectors, and yields high-quality approximations to the Pareto front (PF). Specifically, CAMO consists of a conditional encoder to fuse preferences into instance representations, enabling explicit control over multi-objective trade-offs, and a collaborative decoder that coordinates all agents by alternating agent selection and node selection to construct multi-agent tours autoregressively. To further improve generalization, we train CAMO with a REINFORCE-based objective over a mixed distribution of problem sizes. Extensive experiments show that CAMO outperforms both neural and conventional heuristics, achieving a closer approximation of PFs. In addition, ablation results validate the contributions of CAMO's key components, and real-world tests on a mobile robot platform demonstrate its practical applicability.
Fed-GAME: Personalized Federated Learning with Graph Attention Mixture-of-Experts For Time-Series Forecasting
Mar 02, 2026Federated learning (FL) on graphs shows promise for distributed time-series forecasting. Yet, existing methods rely on static topologies and struggle with client heterogeneity. We propose Fed-GAME, a framework that models personalized aggregation as message passing over a learnable dynamic implicit graph. The core is a decoupled parameter difference-based update protocol, where clients transmit parameter differences between their fine-tuned private model and a shared global model. On the server, these differences are decomposed into two streams: (1) averaged difference used to updating the global model for consensus (2) the selective difference fed into a novel Graph Attention Mixture-of-Experts (GAME) aggregator for fine-grained personalization. In this aggregator, shared experts provide scoring signals while personalized gates adaptively weight selective updates to support personalized aggregation. Experiments on two real-world electric vehicle charging datasets demonstrate that Fed-GAME outperforms state-of-the-art personalized FL baselines.
Preference-Driven Multi-Objective Combinatorial Optimization with Conditional Computation
Jun 10, 2025Recent deep reinforcement learning methods have achieved remarkable success in solving multi-objective combinatorial optimization problems (MOCOPs) by decomposing them into multiple subproblems, each associated with a specific weight vector. However, these methods typically treat all subproblems equally and solve them using a single model, hindering the effective exploration of the solution space and thus leading to suboptimal performance. To overcome the limitation, we propose POCCO, a novel plug-and-play framework that enables adaptive selection of model structures for subproblems, which are subsequently optimized based on preference signals rather than explicit reward values. Specifically, we design a conditional computation block that routes subproblems to specialized neural architectures. Moreover, we propose a preference-driven optimization algorithm that learns pairwise preferences between winning and losing solutions. We evaluate the efficacy and versatility of POCCO by applying it to two state-of-the-art neural methods for MOCOPs. Experimental results across four classic MOCOP benchmarks demonstrate its significant superiority and strong generalization.
Unicorn: A Universal and Collaborative Reinforcement Learning Approach Towards Generalizable Network-Wide Traffic Signal Control
Mar 14, 2025Adaptive traffic signal control (ATSC) is crucial in reducing congestion, maximizing throughput, and improving mobility in rapidly growing urban areas. Recent advancements in parameter-sharing multi-agent reinforcement learning (MARL) have greatly enhanced the scalable and adaptive optimization of complex, dynamic flows in large-scale homogeneous networks. However, the inherent heterogeneity of real-world traffic networks, with their varied intersection topologies and interaction dynamics, poses substantial challenges to achieving scalable and effective ATSC across different traffic scenarios. To address these challenges, we present Unicorn, a universal and collaborative MARL framework designed for efficient and adaptable network-wide ATSC. Specifically, we first propose a unified approach to map the states and actions of intersections with varying topologies into a common structure based on traffic movements. Next, we design a Universal Traffic Representation (UTR) module with a decoder-only network for general feature extraction, enhancing the model's adaptability to diverse traffic scenarios. Additionally, we incorporate an Intersection Specifics Representation (ISR) module, designed to identify key latent vectors that represent the unique intersection's topology and traffic dynamics through variational inference techniques. To further refine these latent representations, we employ a contrastive learning approach in a self-supervised manner, which enables better differentiation of intersection-specific features. Moreover, we integrate the state-action dependencies of neighboring agents into policy optimization, which effectively captures dynamic agent interactions and facilitates efficient regional collaboration. Our results show that Unicorn outperforms other methods across various evaluation metrics, highlighting its potential in complex, dynamic traffic networks.
DL-DRL: A double-layer deep reinforcement learning approach for large-scale task scheduling of multi-UAV
Aug 04, 2022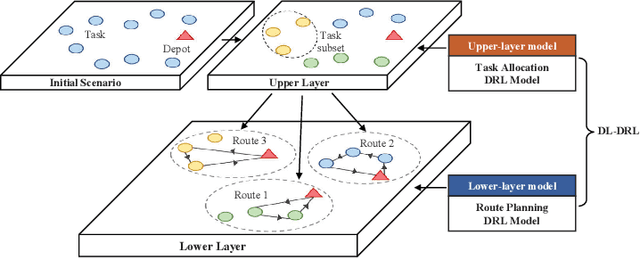
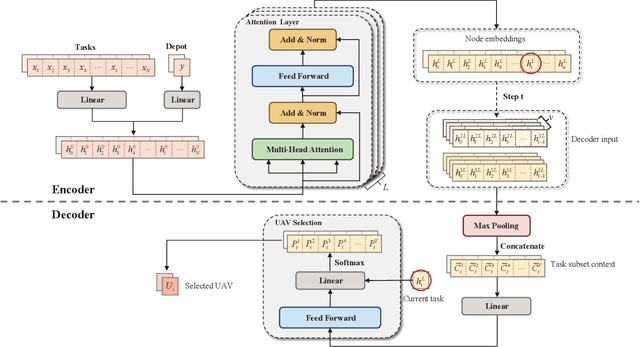
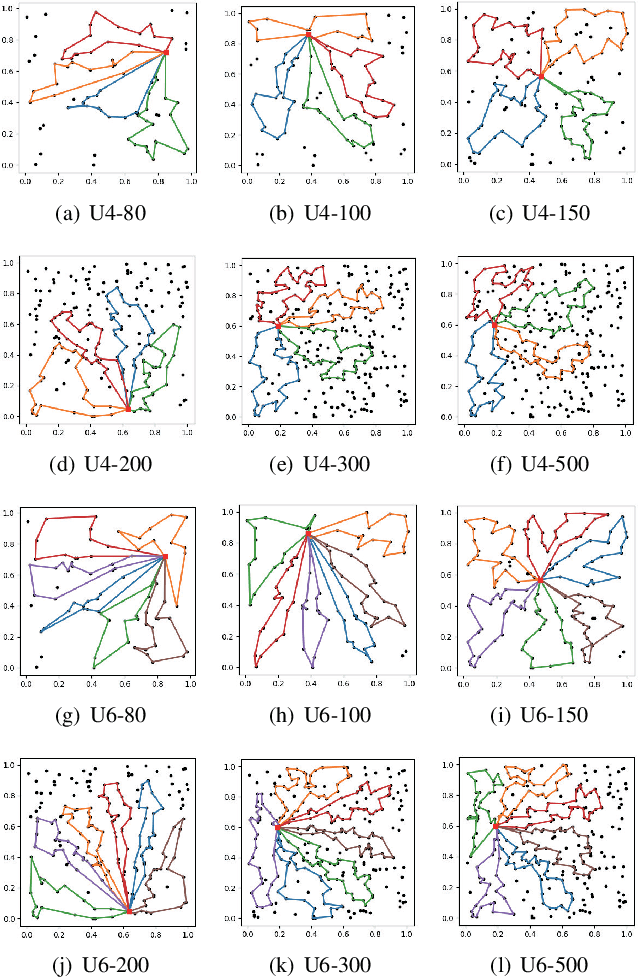
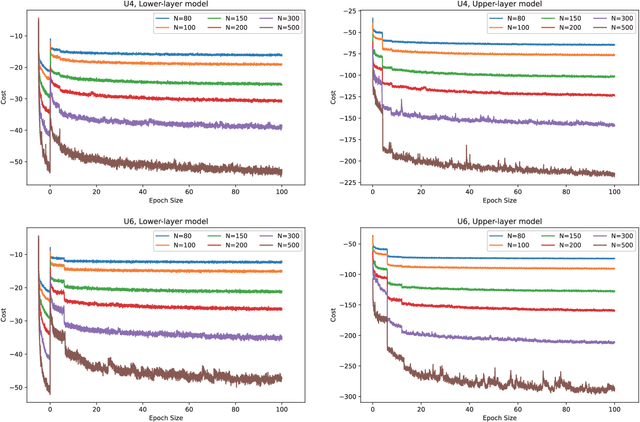
This paper studies deep reinforcement learning (DRL) for the task scheduling problem of multiple unmanned aerial vehicles (UAVs). Current approaches generally use exact and heuristic algorithms to solve the problem, while the computation time rapidly increases as the task scale grows and heuristic rules need manual design. As a self-learning method, DRL can obtain a high-quality solution quickly without hand-engineered rules. However, the huge decision space makes the training of DRL models becomes unstable in situations with large-scale tasks. In this work, to address the large-scale problem, we develop a divide and conquer-based framework (DCF) to decouple the original problem into a task allocation and a UAV route planning subproblems, which are solved in the upper and lower layers, respectively. Based on DCF, a double-layer deep reinforcement learning approach (DL-DRL) is proposed, where an upper-layer DRL model is designed to allocate tasks to appropriate UAVs and a lower-layer DRL model [i.e., the widely used attention model (AM)] is applied to generate viable UAV routes. Since the upper-layer model determines the input data distribution of the lower-layer model, and its reward is calculated via the lower-layer model during training, we develop an interactive training strategy (ITS), where the whole training process consists of pre-training, intensive training, and alternate training processes. Experimental results show that our DL-DRL outperforms mainstream learning-based and most traditional methods, and is competitive with the state-of-the-art heuristic method [i.e., OR-Tools], especially on large-scale problems. The great generalizability of DL-DRL is also verified by testing the model learned for a problem size to larger ones. Furthermore, an ablation study demonstrates that our ITS can reach a compromise between the model performance and training duration.
An Overview and Experimental Study of Learning-based Optimization Algorithms for Vehicle Routing Problem
Jul 15, 2021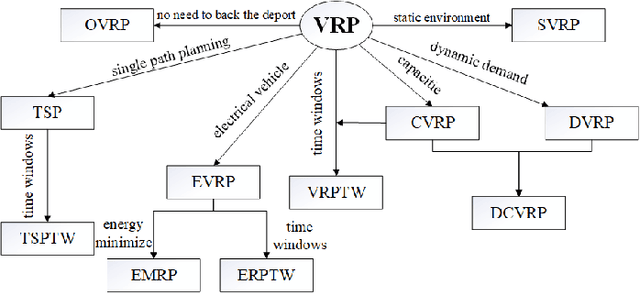
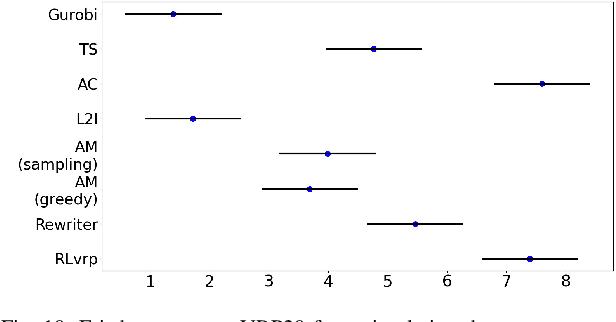
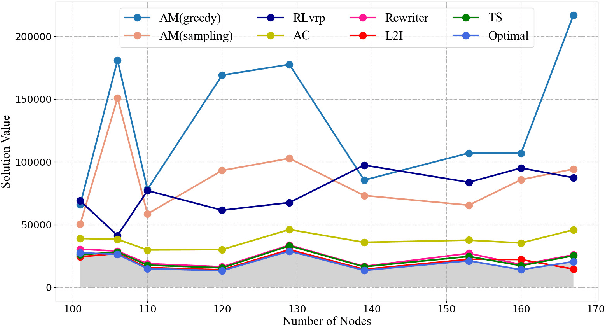
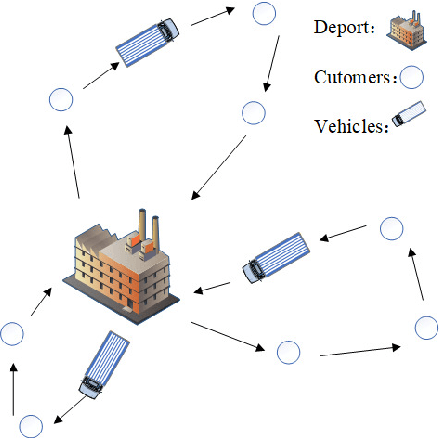
Vehicle routing problem (VRP) is a typical discrete combinatorial optimization problem, and many models and algorithms have been proposed to solve VRP and variants. Although existing approaches has contributed a lot to the development of this field, these approaches either are limited in problem size or need manual intervening in choosing parameters. To tackle these difficulties, many studies consider learning-based optimization algorithms to solve VRP. This paper reviews recent advances in this field and divides relevant approaches into end-to-end approaches and step-by-step approaches. We design three part experiments to justly evaluate performance of four representative learning-based optimization algorithms and conclude that combining heuristic search can effectively improve learning ability and sampled efficiency of LBO models. Finally we point out that research trend of LBO algorithms is to solve large-scale and multiple constraints problems from real world.
An Autonomous Path Planning Method for Unmanned Aerial Vehicle based on A Tangent Intersection and Target Guidance Strategy
Jun 07, 2020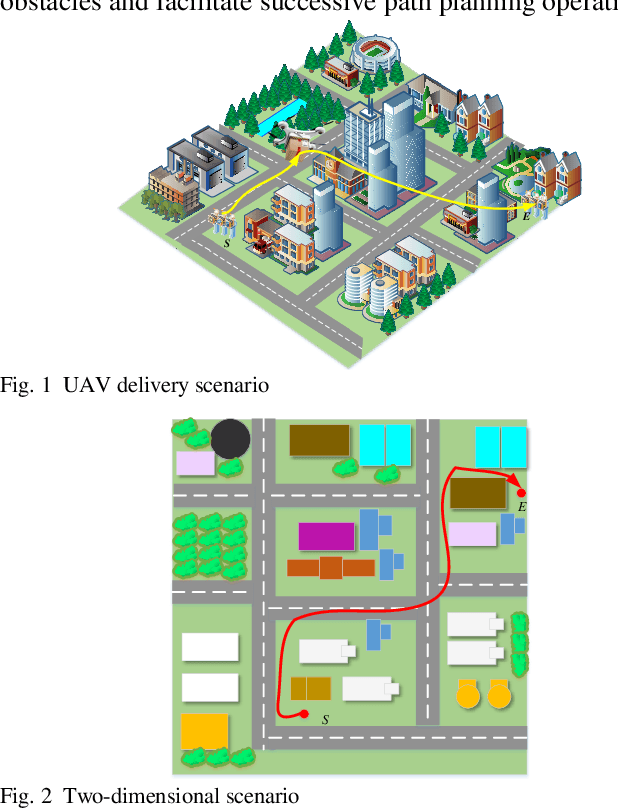
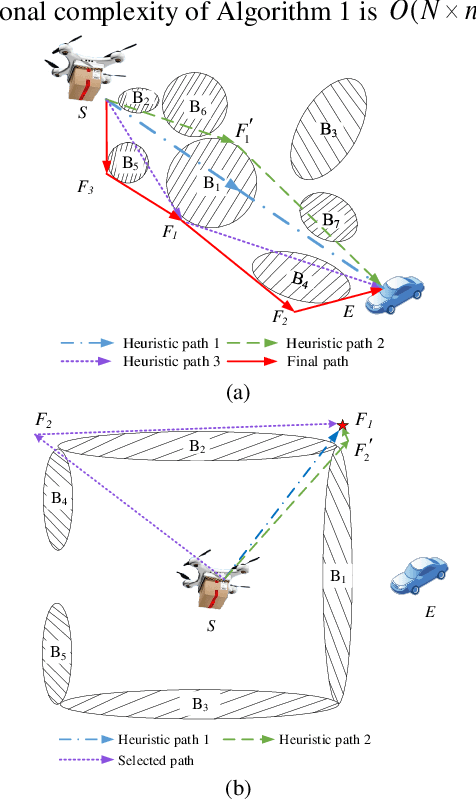
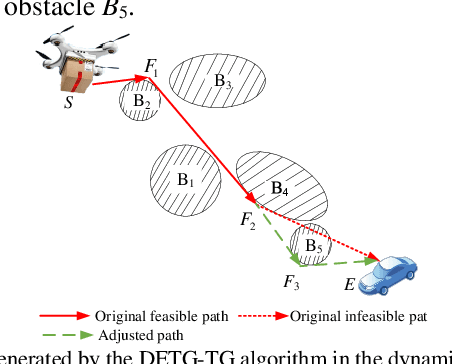
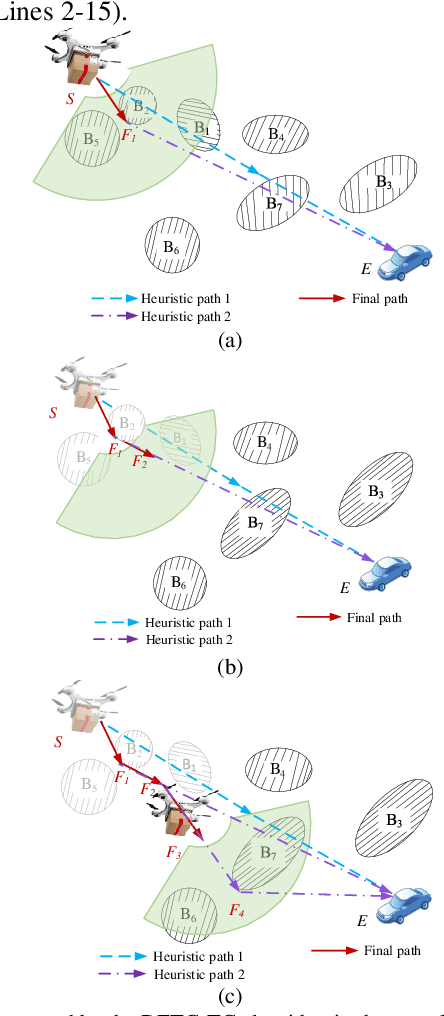
Unmanned aerial vehicle (UAV) path planning enables UAVs to avoid obstacles and reach the target efficiently. To generate high-quality paths without obstacle collision for UAVs, this paper proposes a novel autonomous path planning algorithm based on a tangent intersection and target guidance strategy (APPATT). Guided by a target, the elliptic tangent graph method is used to generate two sub-paths, one of which is selected based on heuristic rules when confronting an obstacle. The UAV flies along the selected sub-path and repeatedly adjusts its flight path to avoid obstacles through this way until the collision-free path extends to the target. Considering the UAV kinematic constraints, the cubic B-spline curve is employed to smooth the waypoints for obtaining a feasible path. Compared with A*, PRM, RRT and VFH, the experimental results show that APPATT can generate the shortest collision-free path within 0.05 seconds for each instance under static environments. Moreover, compared with VFH and RRTRW, APPATT can generate satisfactory collision-free paths under uncertain environments in a nearly real-time manner. It is worth noting that APPATT has the capability of escaping from simple traps within a reasonable time.