 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCPO: A Universal Constrained Combinatorial Optimization Method via Preference Optimization
Nov 13, 2025Neural solvers have demonstrated remarkable success in combinatorial optimization, often surpassing traditional heuristics in speed, solution quality, and generalization. However, their efficacy deteriorates significantly when confronted with complex constraints that cannot be effectively managed through simple masking mechanisms. To address this limitation, we introduce Universal Constrained Preference Optimization (UCPO), a novel plug-and-play framework that seamlessly integrates preference learning into existing neural solvers via a specially designed loss function, without requiring architectural modifications. UCPO embeds constraint satisfaction directly into a preference-based objective, eliminating the need for meticulous hyperparameter tuning. Leveraging a lightweight warm-start fine-tuning protocol, UCPO enables pre-trained models to consistently produce near-optimal, feasible solutions on challenging constraint-laden tasks, achieving exceptional performance with as little as 1\% of the original training budget.
Preference-Driven Multi-Objective Combinatorial Optimization with Conditional Computation
Jun 10, 2025Recent deep reinforcement learning methods have achieved remarkable success in solving multi-objective combinatorial optimization problems (MOCOPs) by decomposing them into multiple subproblems, each associated with a specific weight vector. However, these methods typically treat all subproblems equally and solve them using a single model, hindering the effective exploration of the solution space and thus leading to suboptimal performance. To overcome the limitation, we propose POCCO, a novel plug-and-play framework that enables adaptive selection of model structures for subproblems, which are subsequently optimized based on preference signals rather than explicit reward values. Specifically, we design a conditional computation block that routes subproblems to specialized neural architectures. Moreover, we propose a preference-driven optimization algorithm that learns pairwise preferences between winning and losing solutions. We evaluate the efficacy and versatility of POCCO by applying it to two state-of-the-art neural methods for MOCOPs. Experimental results across four classic MOCOP benchmarks demonstrate its significant superiority and strong generalization.
Neural Combinatorial Optimization via Preference Optimization
Mar 10, 2025
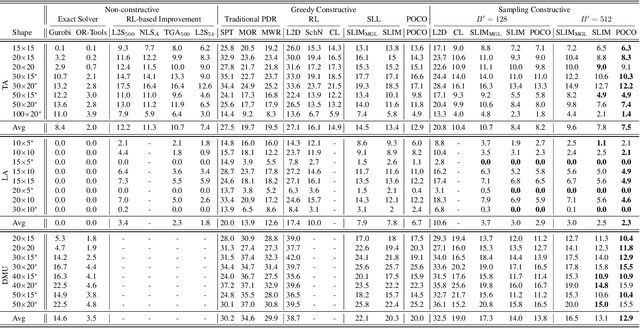


Neural Combinatorial Optimization (NCO) has emerged as a promising approach for NP-hard problems. However, prevailing RL-based methods suffer from low sample efficiency due to sparse rewards and underused solutions. We propose Preference Optimization for Combinatorial Optimization (POCO), a training paradigm that leverages solution preferences via objective values. It introduces: (1) an efficient preference pair construction for better explore and exploit solutions, and (2) a novel loss function that adaptively scales gradients via objective differences, removing reliance on reward models or reference policies. Experiments on Job-Shop Scheduling (JSP), Traveling Salesman (TSP), and Flexible Job-Shop Scheduling (FJSP) show POCO outperforms state-of-the-art neural methods, reducing optimality gaps impressively with efficient inference. POCO is architecture-agnostic, enabling seamless integration with existing NCO models, and establishes preference optimization as a principled framework for combinatorial optimization.
Neural Multi-Objective Combinatorial Optimization with Diversity Enhancement
Oct 22, 2023


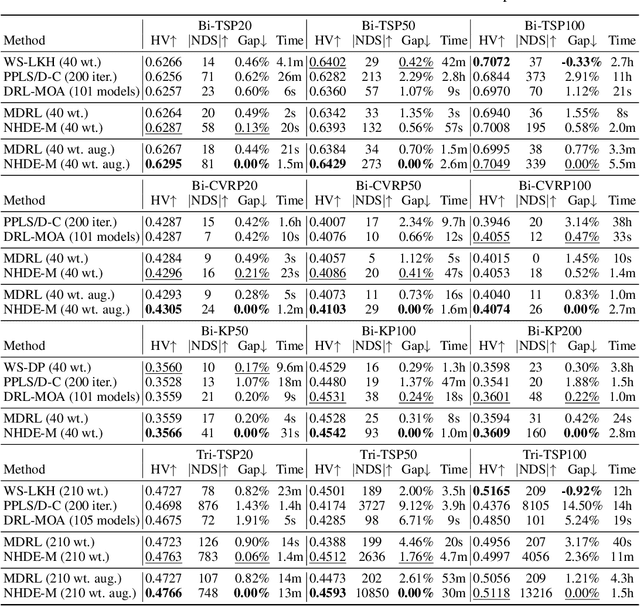
Most of existing neural methods for multi-objective combinatorial optimization (MOCO) problems solely rely on decomposition, which often leads to repetitive solutions for the respective subproblems, thus a limited Pareto set. Beyond decomposition, we propose a novel neural heuristic with diversity enhancement (NHDE) to produce more Pareto solutions from two perspectives. On the one hand, to hinder duplicated solutions for different subproblems, we propose an indicator-enhanced deep reinforcement learning method to guide the model, and design a heterogeneous graph attention mechanism to capture the relations between the instance graph and the Pareto front graph. On the other hand, to excavate more solutions in the neighborhood of each subproblem, we present a multiple Pareto optima strategy to sample and preserve desirable solutions. Experimental results on classic MOCO problems show that our NHDE is able to generate a Pareto front with higher diversity, thereby achieving superior overall performance. Moreover, our NHDE is generic and can be applied to different neural methods for MOCO.
Efficient Meta Neural Heuristic for Multi-Objective Combinatorial Optimization
Oct 22, 2023



Recently, neural heuristics based on deep reinforcement learning have exhibited promise in solving multi-objective combinatorial optimization problems (MOCOPs). However, they are still struggling to achieve high learning efficiency and solution quality. To tackle this issue, we propose an efficient meta neural heuristic (EMNH), in which a meta-model is first trained and then fine-tuned with a few steps to solve corresponding single-objective subproblems. Specifically, for the training process, a (partial) architecture-shared multi-task model is leveraged to achieve parallel learning for the meta-model, so as to speed up the training; meanwhile, a scaled symmetric sampling method with respect to the weight vectors is designed to stabilize the training. For the fine-tuning process, an efficient hierarchical method is proposed to systematically tackle all the subproblems. Experimental results on the multi-objective traveling salesman problem (MOTSP), multi-objective capacitated vehicle routing problem (MOCVRP), and multi-objective knapsack problem (MOKP) show that, EMNH is able to outperform the state-of-the-art neural heuristics in terms of solution quality and learning efficiency, and yield competitive solutions to the strong traditional heuristics while consuming much shorter time.
Learning Generalizable Models for Vehicle Routing Problems via Knowledge Distillation
Oct 14, 2022
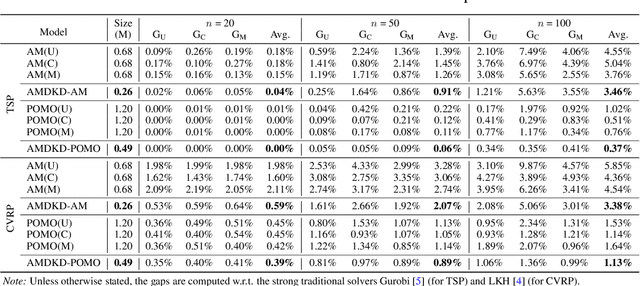
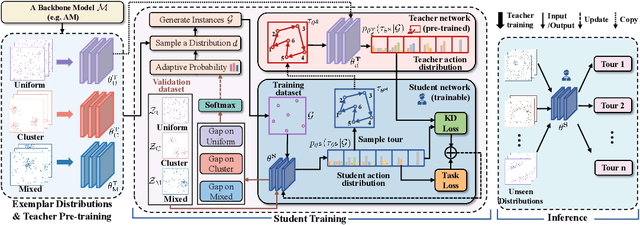
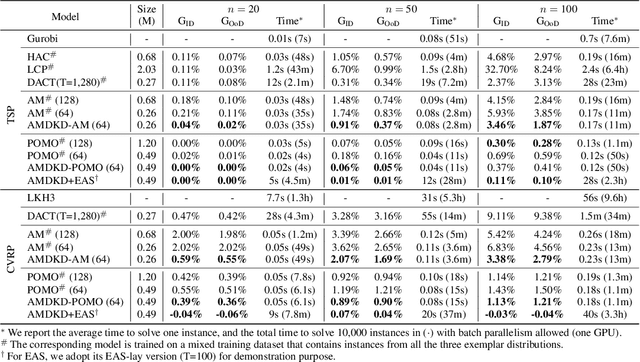
Recent neural methods for vehicle routing problems always train and test the deep models on the same instance distribution (i.e., uniform). To tackle the consequent cross-distribution generalization concerns, we bring the knowledge distillation to this field and propose an Adaptive Multi-Distribution Knowledge Distillation (AMDKD) scheme for learning more generalizable deep models. Particularly, our AMDKD leverages various knowledge from multiple teachers trained on exemplar distributions to yield a light-weight yet generalist student model. Meanwhile, we equip AMDKD with an adaptive strategy that allows the student to concentrate on difficult distributions, so as to absorb hard-to-master knowledge more effectively. Extensive experimental results show that, compared with the baseline neural methods, our AMDKD is able to achieve competitive results on both unseen in-distribution and out-of-distribution instances, which are either randomly synthesized or adopted from benchmark datasets (i.e., TSPLIB and CVRPLIB). Notably, our AMDKD is generic, and consumes less computational resources for inference.