 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Capacity Planning in Semiconductor Manufacturing
Sep 19, 2025In manufacturing, capacity planning is the process of allocating production resources in accordance with variable demand. The current industry practice in semiconductor manufacturing typically applies heuristic rules to prioritize actions, such as future change lists that account for incoming machine and recipe dedications. However, while offering interpretability, heuristics cannot easily account for the complex interactions along the process flow that can gradually lead to the formation of bottlenecks. Here, we present a neural network-based model for capacity planning on the level of individual machines, trained using deep reinforcement learning. By representing the policy using a heterogeneous graph neural network, the model directly captures the diverse relationships among machines and processing steps, allowing for proactive decision-making. We describe several measures taken to achieve sufficient scalability to tackle the vast space of possible machine-level actions. Our evaluation results cover Intel's small-scale Minifab model and preliminary experiments using the popular SMT2020 testbed. In the largest tested scenario, our trained policy increases throughput and decreases cycle time by about 1.8% each.
Generalizable Heuristic Generation Through Large Language Models with Meta-Optimization
May 27, 2025Heuristic design with large language models (LLMs) has emerged as a promising approach for tackling combinatorial optimization problems (COPs). However, existing approaches often rely on manually predefined evolutionary computation (EC) optimizers and single-task training schemes, which may constrain the exploration of diverse heuristic algorithms and hinder the generalization of the resulting heuristics. To address these issues, we propose Meta-Optimization of Heuristics (MoH), a novel framework that operates at the optimizer level, discovering effective optimizers through the principle of meta-learning. Specifically, MoH leverages LLMs to iteratively refine a meta-optimizer that autonomously constructs diverse optimizers through (self-)invocation, thereby eliminating the reliance on a predefined EC optimizer. These constructed optimizers subsequently evolve heuristics for downstream tasks, enabling broader heuristic exploration. Moreover, MoH employs a multi-task training scheme to promote its generalization capability. Experiments on classic COPs demonstrate that MoH constructs an effective and interpretable meta-optimizer, achieving state-of-the-art performance across various downstream tasks, particularly in cross-size settings.
Learning to Handle Complex Constraints for Vehicle Routing Problems
Oct 28, 2024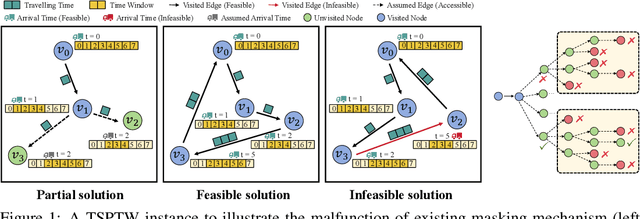
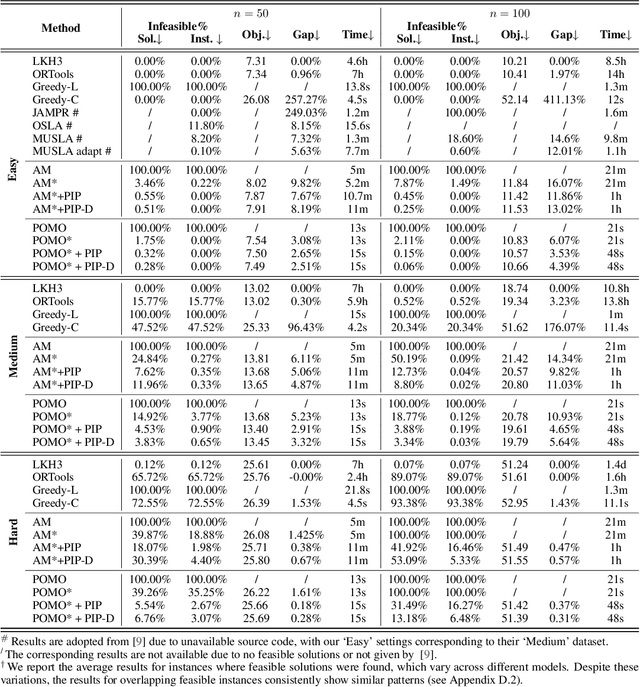
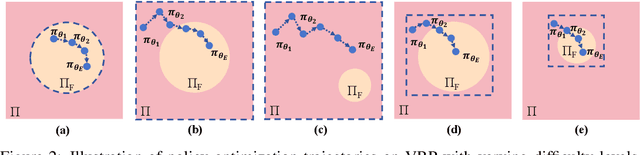
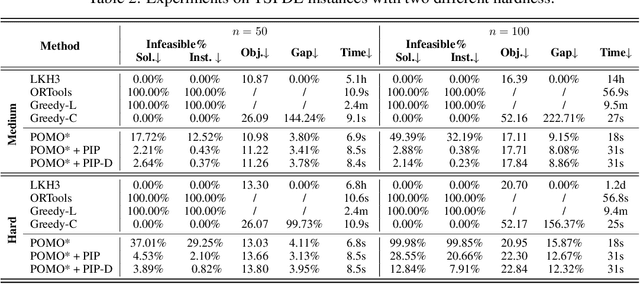
Vehicle Routing Problems (VRPs) can model many real-world scenarios and often involve complex constraints. While recent neural methods excel in constructing solutions based on feasibility masking, they struggle with handling complex constraints, especially when obtaining the masking itself is NP-hard. In this paper, we propose a novel Proactive Infeasibility Prevention (PIP) framework to advance the capabilities of neural methods towards more complex VRPs. Our PIP integrates the Lagrangian multiplier as a basis to enhance constraint awareness and introduces preventative infeasibility masking to proactively steer the solution construction process. Moreover, we present PIP-D, which employs an auxiliary decoder and two adaptive strategies to learn and predict these tailored masks, potentially enhancing performance while significantly reducing computational costs during training. To verify our PIP designs, we conduct extensive experiments on the highly challenging Traveling Salesman Problem with Time Window (TSPTW), and TSP with Draft Limit (TSPDL) variants under different constraint hardness levels. Notably, our PIP is generic to boost many neural methods, and exhibits both a significant reduction in infeasible rate and a substantial improvement in solution quality.
Learning Generalizable Models for Vehicle Routing Problems via Knowledge Distillation
Oct 14, 2022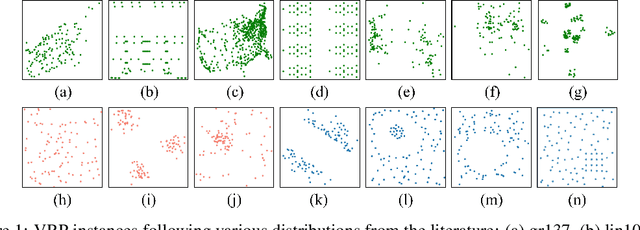
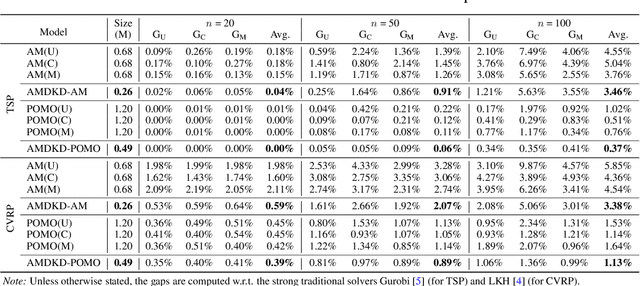
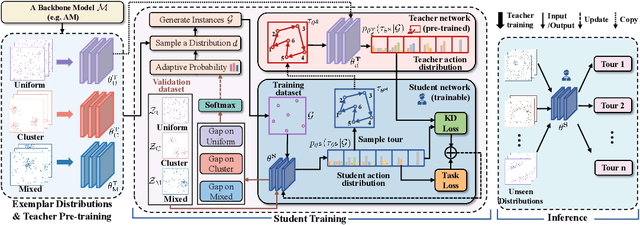
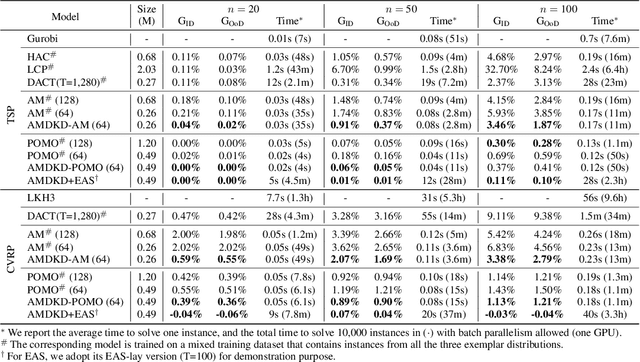
Recent neural methods for vehicle routing problems always train and test the deep models on the same instance distribution (i.e., uniform). To tackle the consequent cross-distribution generalization concerns, we bring the knowledge distillation to this field and propose an Adaptive Multi-Distribution Knowledge Distillation (AMDKD) scheme for learning more generalizable deep models. Particularly, our AMDKD leverages various knowledge from multiple teachers trained on exemplar distributions to yield a light-weight yet generalist student model. Meanwhile, we equip AMDKD with an adaptive strategy that allows the student to concentrate on difficult distributions, so as to absorb hard-to-master knowledge more effectively. Extensive experimental results show that, compared with the baseline neural methods, our AMDKD is able to achieve competitive results on both unseen in-distribution and out-of-distribution instances, which are either randomly synthesized or adopted from benchmark datasets (i.e., TSPLIB and CVRPLIB). Notably, our AMDKD is generic, and consumes less computational resources for inference.