 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Neural Backbone for Mixed-Integer Linear Optimization via Dual Attention
Jan 08, 2026Mixed-integer linear programming (MILP), a widely used modeling framework for combinatorial optimization, are central to many scientific and engineering applications, yet remains computationally challenging at scale. Recent advances in deep learning address this challenge by representing MILP instances as variable-constraint bipartite graphs and applying graph neural networks (GNNs) to extract latent structural patterns and enhance solver efficiency. However, this architecture is inherently limited by the local-oriented mechanism, leading to restricted representation power and hindering neural approaches for MILP. Here we present an attention-driven neural architecture that learns expressive representations beyond the pure graph view. A dual-attention mechanism is designed to perform parallel self- and cross-attention over variables and constraints, enabling global information exchange and deeper representation learning. We apply this general backbone to various downstream tasks at the instance level, element level, and solving state level. Extensive experiments across widely used benchmarks show consistent improvements of our approach over state-of-the-art baselines, highlighting attention-based neural architectures as a powerful foundation for learning-enhanced mixed-integer linear optimization.
Generalizable Heuristic Generation Through Large Language Models with Meta-Optimization
May 27, 2025Heuristic design with large language models (LLMs) has emerged as a promising approach for tackling combinatorial optimization problems (COPs). However, existing approaches often rely on manually predefined evolutionary computation (EC) optimizers and single-task training schemes, which may constrain the exploration of diverse heuristic algorithms and hinder the generalization of the resulting heuristics. To address these issues, we propose Meta-Optimization of Heuristics (MoH), a novel framework that operates at the optimizer level, discovering effective optimizers through the principle of meta-learning. Specifically, MoH leverages LLMs to iteratively refine a meta-optimizer that autonomously constructs diverse optimizers through (self-)invocation, thereby eliminating the reliance on a predefined EC optimizer. These constructed optimizers subsequently evolve heuristics for downstream tasks, enabling broader heuristic exploration. Moreover, MoH employs a multi-task training scheme to promote its generalization capability. Experiments on classic COPs demonstrate that MoH constructs an effective and interpretable meta-optimizer, achieving state-of-the-art performance across various downstream tasks, particularly in cross-size settings.
Learning to Handle Complex Constraints for Vehicle Routing Problems
Oct 28, 2024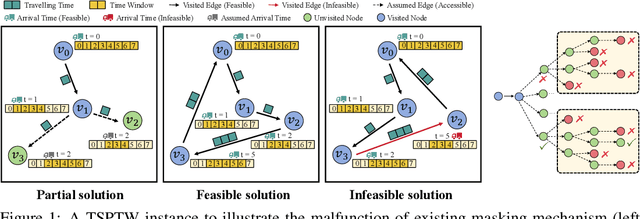
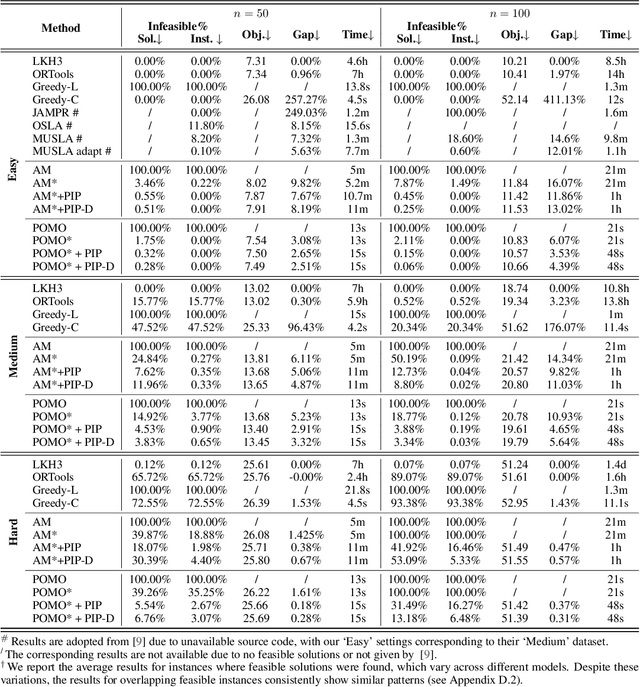
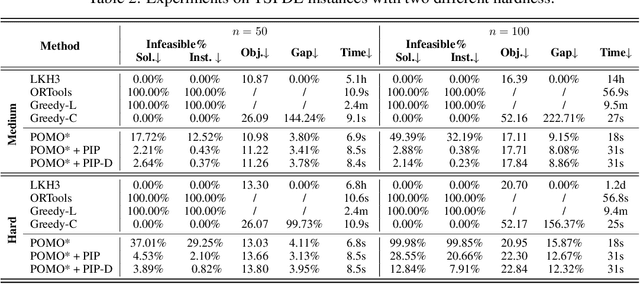
Vehicle Routing Problems (VRPs) can model many real-world scenarios and often involve complex constraints. While recent neural methods excel in constructing solutions based on feasibility masking, they struggle with handling complex constraints, especially when obtaining the masking itself is NP-hard. In this paper, we propose a novel Proactive Infeasibility Prevention (PIP) framework to advance the capabilities of neural methods towards more complex VRPs. Our PIP integrates the Lagrangian multiplier as a basis to enhance constraint awareness and introduces preventative infeasibility masking to proactively steer the solution construction process. Moreover, we present PIP-D, which employs an auxiliary decoder and two adaptive strategies to learn and predict these tailored masks, potentially enhancing performance while significantly reducing computational costs during training. To verify our PIP designs, we conduct extensive experiments on the highly challenging Traveling Salesman Problem with Time Window (TSPTW), and TSP with Draft Limit (TSPDL) variants under different constraint hardness levels. Notably, our PIP is generic to boost many neural methods, and exhibits both a significant reduction in infeasible rate and a substantial improvement in solution quality.
Collaboration! Towards Robust Neural Methods for Routing Problems
Oct 07, 2024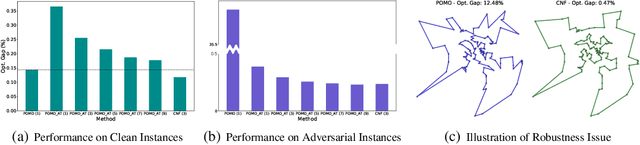
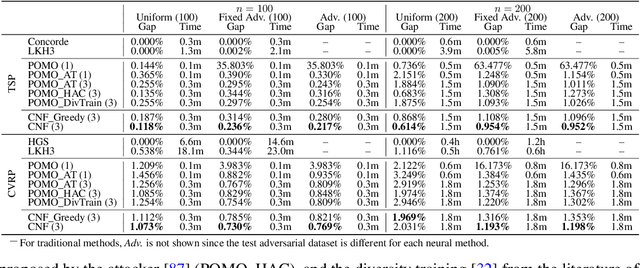
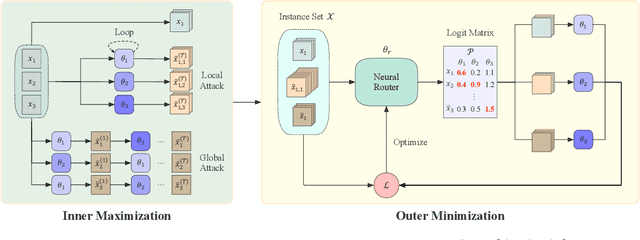
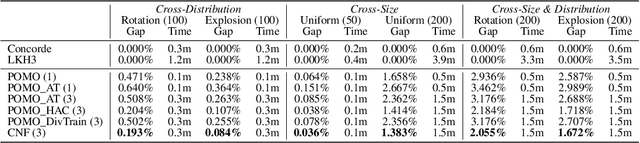
Despite enjoying desirable efficiency and reduced reliance on domain expertise, existing neural methods for vehicle routing problems (VRPs) suffer from severe robustness issues -- their performance significantly deteriorates on clean instances with crafted perturbations. To enhance robustness, we propose an ensemble-based Collaborative Neural Framework (CNF) w.r.t. the defense of neural VRP methods, which is crucial yet underexplored in the literature. Given a neural VRP method, we adversarially train multiple models in a collaborative manner to synergistically promote robustness against attacks, while boosting standard generalization on clean instances. A neural router is designed to adeptly distribute training instances among models, enhancing overall load balancing and collaborative efficacy. Extensive experiments verify the effectiveness and versatility of CNF in defending against various attacks across different neural VRP methods. Notably, our approach also achieves impressive out-of-distribution generalization on benchmark instances.
MVMoE: Multi-Task Vehicle Routing Solver with Mixture-of-Experts
May 02, 2024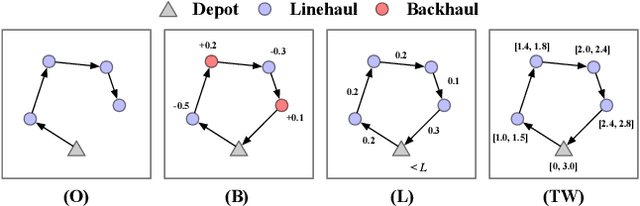
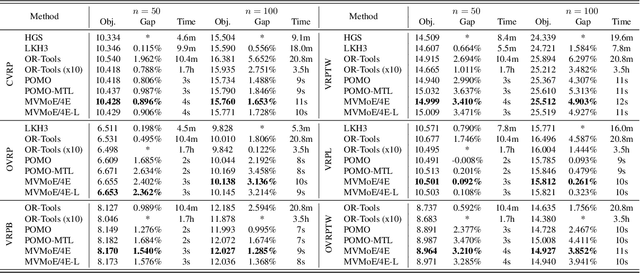
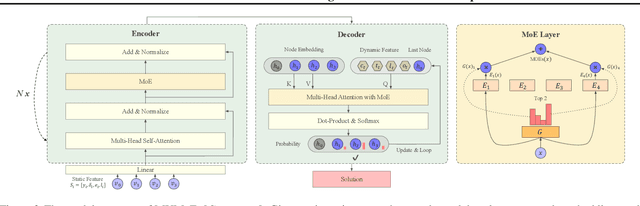
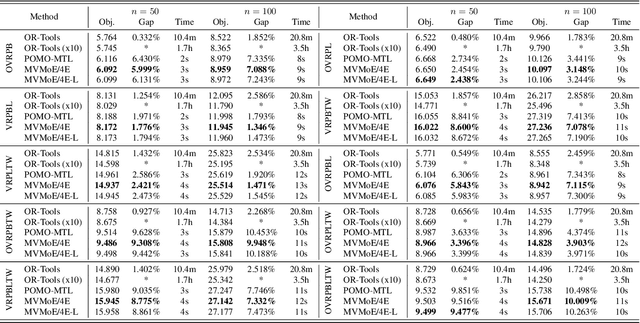
Learning to solve vehicle routing problems (VRPs) has garnered much attention. However, most neural solvers are only structured and trained independently on a specific problem, making them less generic and practical. In this paper, we aim to develop a unified neural solver that can cope with a range of VRP variants simultaneously. Specifically, we propose a multi-task vehicle routing solver with mixture-of-experts (MVMoE), which greatly enhances the model capacity without a proportional increase in computation. We further develop a hierarchical gating mechanism for the MVMoE, delivering a good trade-off between empirical performance and computational complexity. Experimentally, our method significantly promotes the zero-shot generalization performance on 10 unseen VRP variants, and showcases decent results on the few-shot setting and real-world benchmark instances. We further provide extensive studies on the effect of MoE configurations in solving VRPs. Surprisingly, the hierarchical gating can achieve much better out-of-distribution generalization performance. The source code is available at: https://github.com/RoyalSkye/Routing-MVMoE.
Cross-Problem Learning for Solving Vehicle Routing Problems
Apr 17, 2024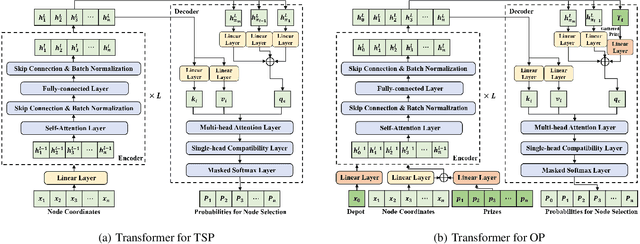

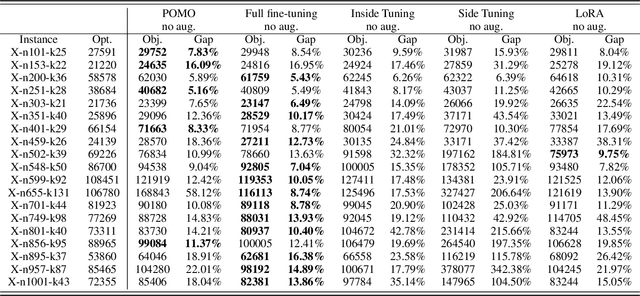

Existing neural heuristics often train a deep architecture from scratch for each specific vehicle routing problem (VRP), ignoring the transferable knowledge across different VRP variants. This paper proposes the cross-problem learning to assist heuristics training for different downstream VRP variants. Particularly, we modularize neural architectures for complex VRPs into 1) the backbone Transformer for tackling the travelling salesman problem (TSP), and 2) the additional lightweight modules for processing problem-specific features in complex VRPs. Accordingly, we propose to pre-train the backbone Transformer for TSP, and then apply it in the process of fine-tuning the Transformer models for each target VRP variant. On the one hand, we fully fine-tune the trained backbone Transformer and problem-specific modules simultaneously. On the other hand, we only fine-tune small adapter networks along with the modules, keeping the backbone Transformer still. Extensive experiments on typical VRPs substantiate that 1) the full fine-tuning achieves significantly better performance than the one trained from scratch, and 2) the adapter-based fine-tuning also delivers comparable performance while being notably parameter-efficient. Furthermore, we empirically demonstrate the favorable effect of our method in terms of cross-distribution application and versatility.
Learning Topological Representations with Bidirectional Graph Attention Network for Solving Job Shop Scheduling Problem
Feb 27, 2024Existing learning-based methods for solving job shop scheduling problem (JSSP) usually use off-the-shelf GNN models tailored to undirected graphs and neglect the rich and meaningful topological structures of disjunctive graphs (DGs). This paper proposes the topology-aware bidirectional graph attention network (TBGAT), a novel GNN architecture based on the attention mechanism, to embed the DG for solving JSSP in a local search framework. Specifically, TBGAT embeds the DG from a forward and a backward view, respectively, where the messages are propagated by following the different topologies of the views and aggregated via graph attention. Then, we propose a novel operator based on the message-passing mechanism to calculate the forward and backward topological sorts of the DG, which are the features for characterizing the topological structures and exploited by our model. In addition, we theoretically and experimentally show that TBGAT has linear computational complexity to the number of jobs and machines, respectively, which strengthens the practical value of our method. Besides, extensive experiments on five synthetic datasets and seven classic benchmarks show that TBGAT achieves new SOTA results by outperforming a wide range of neural methods by a large margin.
Towards Omni-generalizable Neural Methods for Vehicle Routing Problems
May 31, 2023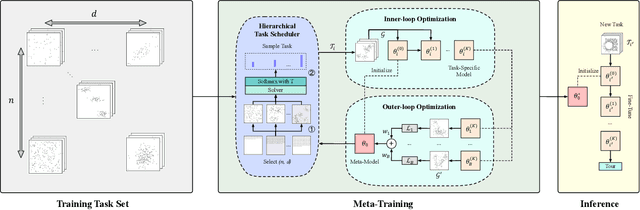
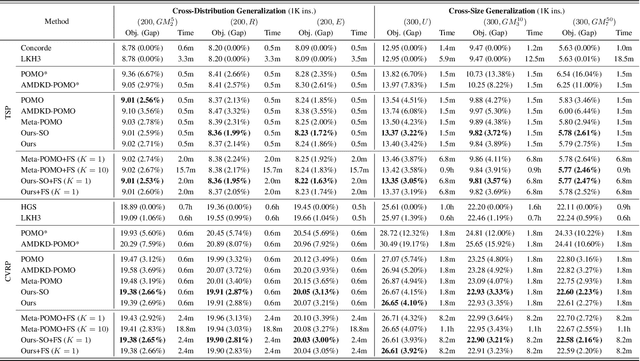
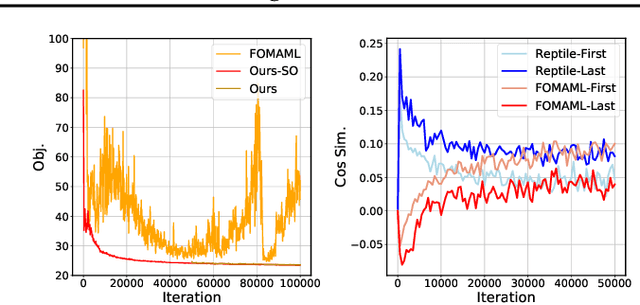
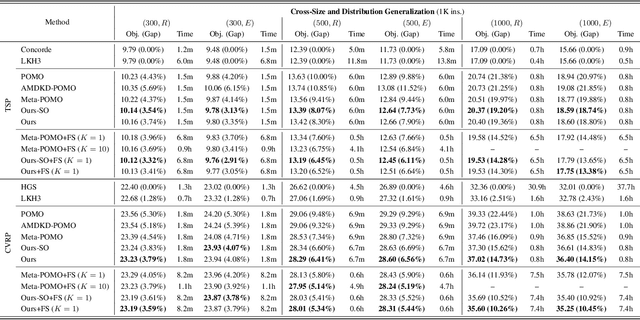
Learning heuristics for vehicle routing problems (VRPs) has gained much attention due to the less reliance on hand-crafted rules. However, existing methods are typically trained and tested on the same task with a fixed size and distribution (of nodes), and hence suffer from limited generalization performance. This paper studies a challenging yet realistic setting, which considers generalization across both size and distribution in VRPs. We propose a generic meta-learning framework, which enables effective training of an initialized model with the capability of fast adaptation to new tasks during inference. We further develop a simple yet efficient approximation method to reduce the training overhead. Extensive experiments on both synthetic and benchmark instances of the traveling salesman problem (TSP) and capacitated vehicle routing problem (CVRP) demonstrate the effectiveness of our method. The code is available at: https://github.com/RoyalSkye/Omni-VRP.
Learning Large Neighborhood Search for Vehicle Routing in Airport Ground Handling
Feb 27, 2023



Dispatching vehicle fleets to serve flights is a key task in airport ground handling (AGH). Due to the notable growth of flights, it is challenging to simultaneously schedule multiple types of operations (services) for a large number of flights, where each type of operation is performed by one specific vehicle fleet. To tackle this issue, we first represent the operation scheduling as a complex vehicle routing problem and formulate it as a mixed integer linear programming (MILP) model. Then given the graph representation of the MILP model, we propose a learning assisted large neighborhood search (LNS) method using data generated based on real scenarios, where we integrate imitation learning and graph convolutional network (GCN) to learn a destroy operator to automatically select variables, and employ an off-the-shelf solver as the repair operator to reoptimize the selected variables. Experimental results based on a real airport show that the proposed method allows for handling up to 200 flights with 10 types of operations simultaneously, and outperforms state-of-the-art methods. Moreover, the learned method performs consistently accompanying different solvers, and generalizes well on larger instances, verifying the versatility and scalability of our method.
Learning to Search for Job Shop Scheduling via Deep Reinforcement Learning
Nov 27, 2022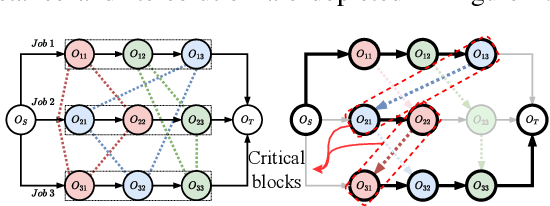



Recent studies in using deep reinforcement learning (DRL) to solve Job-shop scheduling problems (JSSP) focus on construction heuristics. However, their performance is still far from optimality, mainly because the underlying graph representation scheme is unsuitable for modeling partial solutions at each construction step. This paper proposes a novel DRL-based method to learn improvement heuristics for JSSP, where graph representation is employed to encode complete solutions. We design a Graph Neural Network based representation scheme, consisting of two modules to effectively capture the information of dynamic topology and different types of nodes in graphs encountered during the improvement process. To speed up solution evaluation during improvement, we design a novel message-passing mechanism that can evaluate multiple solutions simultaneously. Extensive experiments on classic benchmarks show that the improvement policy learned by our method outperforms state-of-the-art DRL-based methods by a large margin.