 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Weakness of Large Language Model Agents within a Complex Android Environment
Feb 09, 2024



Large language models (LLMs) have empowered intelligent agents to execute intricate tasks within domain-specific software such as browsers and games. However, when applied to general-purpose software systems like operating systems, LLM agents face three primary challenges. Firstly, the action space is vast and dynamic, posing difficulties for LLM agents to maintain an up-to-date understanding and deliver accurate responses. Secondly, real-world tasks often require inter-application cooperation}, demanding farsighted planning from LLM agents. Thirdly, agents need to identify optimal solutions aligning with user constraints, such as security concerns and preferences. These challenges motivate AndroidArena, an environment and benchmark designed to evaluate LLM agents on a modern operating system. To address high-cost of manpower, we design a scalable and semi-automated method to construct the benchmark. In the task evaluation, AndroidArena incorporates accurate and adaptive metrics to address the issue of non-unique solutions. Our findings reveal that even state-of-the-art LLM agents struggle in cross-APP scenarios and adhering to specific constraints. Additionally, we identify a lack of four key capabilities, i.e., understanding, reasoning, exploration, and reflection, as primary reasons for the failure of LLM agents. Furthermore, we provide empirical analysis on the failure of reflection, and improve the success rate by 27% with our proposed exploration strategy. This work is the first to present valuable insights in understanding fine-grained weakness of LLM agents, and offers a path forward for future research in this area. Environment, benchmark, and evaluation code for AndroidArena are released at https://github.com/AndroidArenaAgent/AndroidArena.
Learning to Solve Multiple-TSP with Time Window and Rejections via Deep Reinforcement Learning
Sep 13, 2022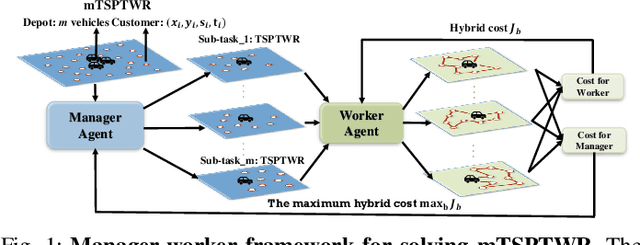
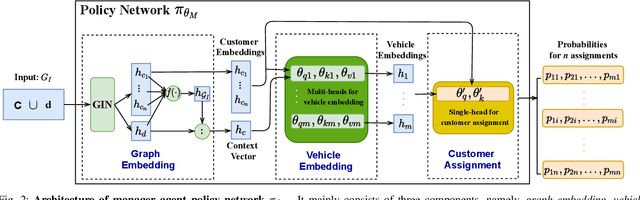
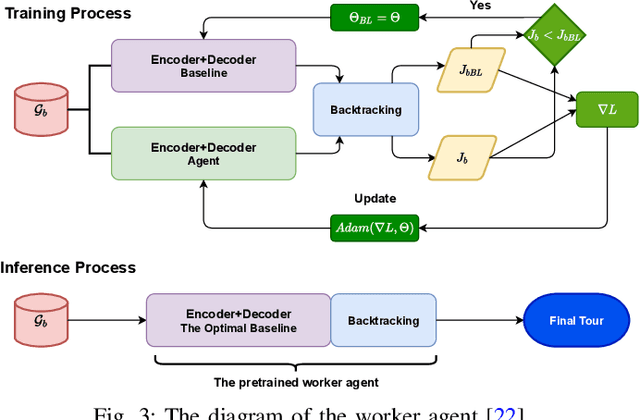
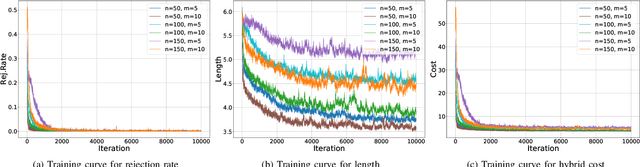
We propose a manager-worker framework based on deep reinforcement learning to tackle a hard yet nontrivial variant of Travelling Salesman Problem (TSP), \ie~multiple-vehicle TSP with time window and rejections (mTSPTWR), where customers who cannot be served before the deadline are subject to rejections. Particularly, in the proposed framework, a manager agent learns to divide mTSPTWR into sub-routing tasks by assigning customers to each vehicle via a Graph Isomorphism Network (GIN) based policy network. A worker agent learns to solve sub-routing tasks by minimizing the cost in terms of both tour length and rejection rate for each vehicle, the maximum of which is then fed back to the manager agent to learn better assignments. Experimental results demonstrate that the proposed framework outperforms strong baselines in terms of higher solution quality and shorter computation time. More importantly, the trained agents also achieve competitive performance for solving unseen larger instances.
REPNP: Plug-and-Play with Deep Reinforcement Learning Prior for Robust Image Restoration
Jul 25, 2022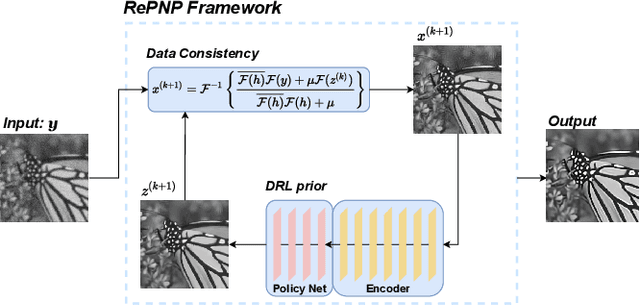
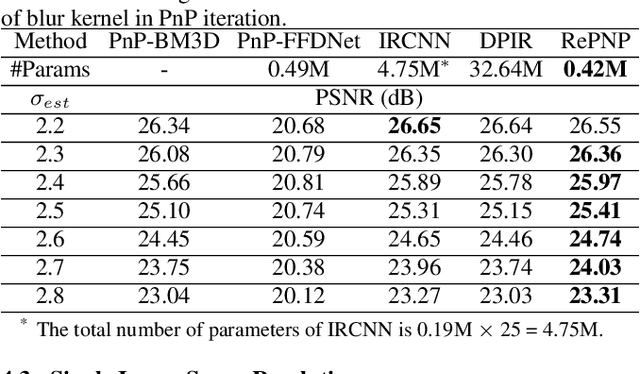
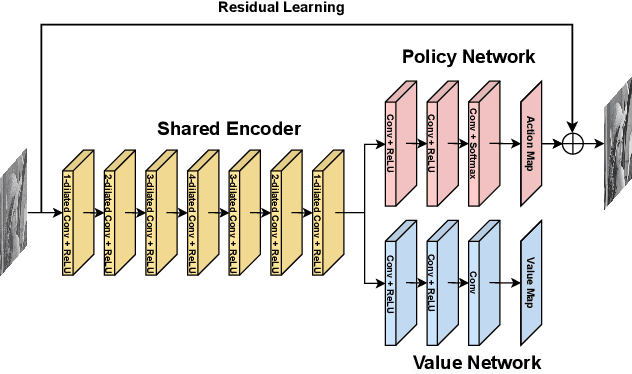
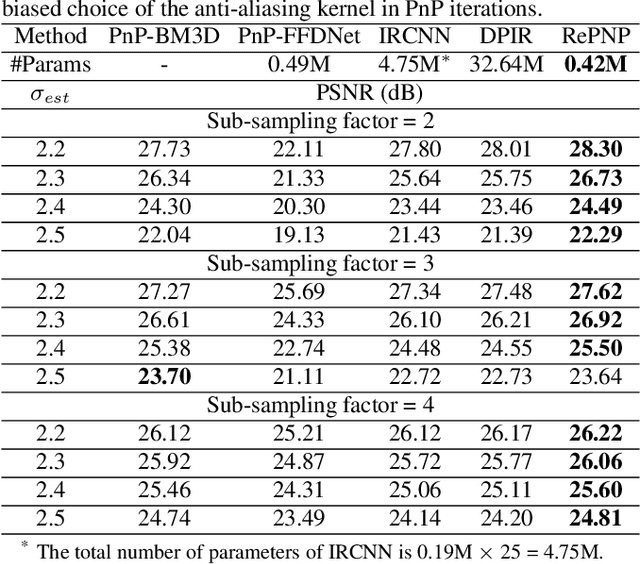
Image restoration schemes based on the pre-trained deep models have received great attention due to their unique flexibility for solving various inverse problems. In particular, the Plug-and-Play (PnP) framework is a popular and powerful tool that can integrate an off-the-shelf deep denoiser for different image restoration tasks with known observation models. However, obtaining the observation model that exactly matches the actual one can be challenging in practice. Thus, the PnP schemes with conventional deep denoisers may fail to generate satisfying results in some real-world image restoration tasks. We argue that the robustness of the PnP framework is largely limited by using the off-the-shelf deep denoisers that are trained by deterministic optimization. To this end, we propose a novel deep reinforcement learning (DRL) based PnP framework, dubbed RePNP, by leveraging a light-weight DRL-based denoiser for robust image restoration tasks. Experimental results demonstrate that the proposed RePNP is robust to the observation model used in the PnP scheme deviating from the actual one. Thus, RePNP can generate more reliable restoration results for image deblurring and super resolution tasks. Compared with several state-of-the-art deep image restoration baselines, RePNP achieves better results subjective to model deviation with fewer model parameters.
ReLLIE: Deep Reinforcement Learning for Customized Low-Light Image Enhancement
Jul 13, 2021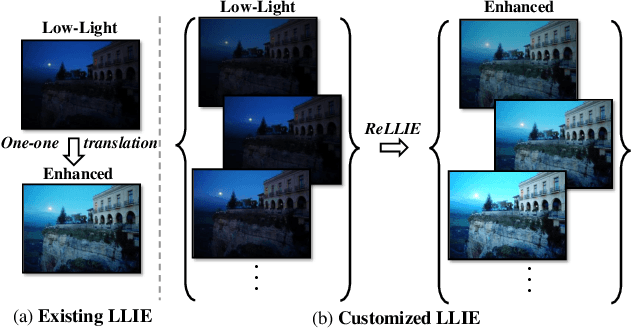
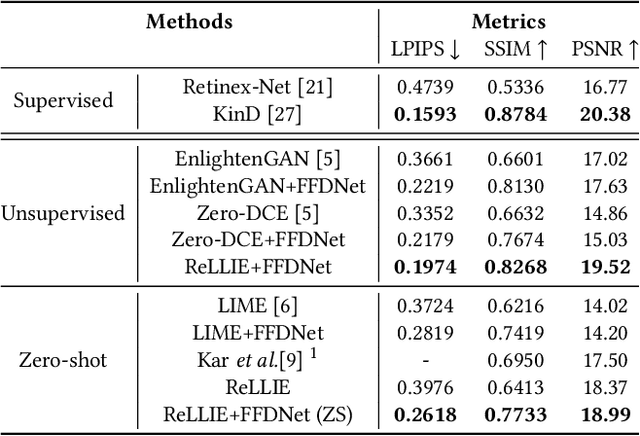

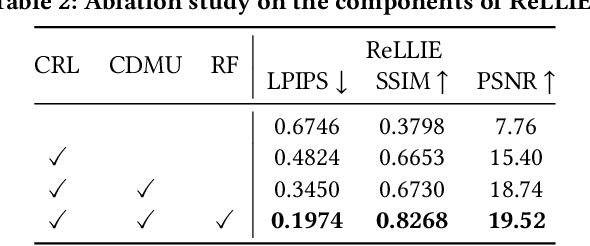
Low-light image enhancement (LLIE) is a pervasive yet challenging problem, since: 1) low-light measurements may vary due to different imaging conditions in practice; 2) images can be enlightened subjectively according to diverse preferences by each individual. To tackle these two challenges, this paper presents a novel deep reinforcement learning based method, dubbed ReLLIE, for customized low-light enhancement. ReLLIE models LLIE as a markov decision process, i.e., estimating the pixel-wise image-specific curves sequentially and recurrently. Given the reward computed from a set of carefully crafted non-reference loss functions, a lightweight network is proposed to estimate the curves for enlightening of a low-light image input. As ReLLIE learns a policy instead of one-one image translation, it can handle various low-light measurements and provide customized enhanced outputs by flexibly applying the policy different times. Furthermore, ReLLIE can enhance real-world images with hybrid corruptions, e.g., noise, by using a plug-and-play denoiser easily. Extensive experiments on various benchmarks demonstrate the advantages of ReLLIE, comparing to the state-of-the-art methods.
R3L: Connecting Deep Reinforcement Learning to Recurrent Neural Networks for Image Denoising via Residual Recovery
Jul 12, 2021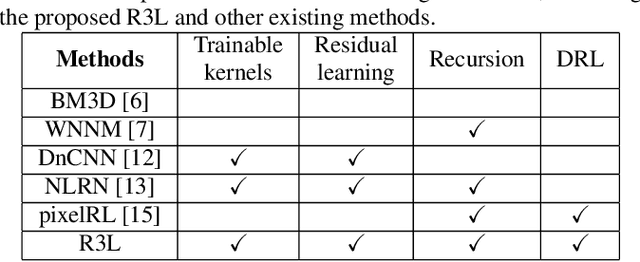
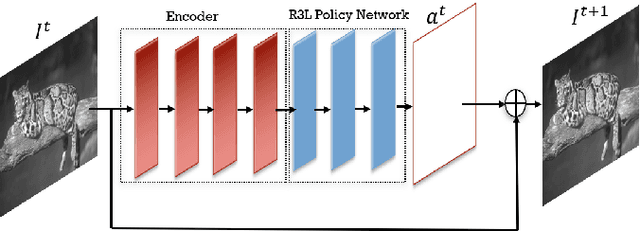
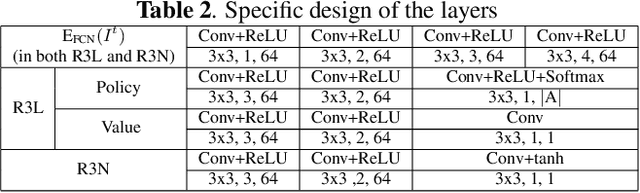
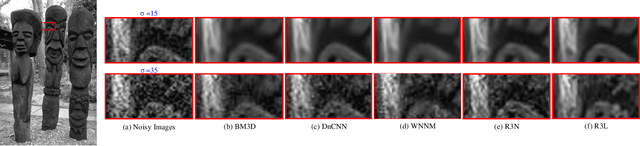
State-of-the-art image denoisers exploit various types of deep neural networks via deterministic training. Alternatively, very recent works utilize deep reinforcement learning for restoring images with diverse or unknown corruptions. Though deep reinforcement learning can generate effective policy networks for operator selection or architecture search in image restoration, how it is connected to the classic deterministic training in solving inverse problems remains unclear. In this work, we propose a novel image denoising scheme via Residual Recovery using Reinforcement Learning, dubbed R3L. We show that R3L is equivalent to a deep recurrent neural network that is trained using a stochastic reward, in contrast to many popular denoisers using supervised learning with deterministic losses. To benchmark the effectiveness of reinforcement learning in R3L, we train a recurrent neural network with the same architecture for residual recovery using the deterministic loss, thus to analyze how the two different training strategies affect the denoising performance. With such a unified benchmarking system, we demonstrate that the proposed R3L has better generalizability and robustness in image denoising when the estimated noise level varies, comparing to its counterparts using deterministic training, as well as various state-of-the-art image denoising algorithms.