 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCPO: A Universal Constrained Combinatorial Optimization Method via Preference Optimization
Nov 13, 2025Neural solvers have demonstrated remarkable success in combinatorial optimization, often surpassing traditional heuristics in speed, solution quality, and generalization. However, their efficacy deteriorates significantly when confronted with complex constraints that cannot be effectively managed through simple masking mechanisms. To address this limitation, we introduce Universal Constrained Preference Optimization (UCPO), a novel plug-and-play framework that seamlessly integrates preference learning into existing neural solvers via a specially designed loss function, without requiring architectural modifications. UCPO embeds constraint satisfaction directly into a preference-based objective, eliminating the need for meticulous hyperparameter tuning. Leveraging a lightweight warm-start fine-tuning protocol, UCPO enables pre-trained models to consistently produce near-optimal, feasible solutions on challenging constraint-laden tasks, achieving exceptional performance with as little as 1\% of the original training budget.
DIVER: A Multi-Stage Approach for Reasoning-intensive Information Retrieval
Aug 12, 2025Retrieval-augmented generation has achieved strong performance on knowledge-intensive tasks where query-document relevance can be identified through direct lexical or semantic matches. However, many real-world queries involve abstract reasoning, analogical thinking, or multi-step inference, which existing retrievers often struggle to capture. To address this challenge, we present \textbf{DIVER}, a retrieval pipeline tailored for reasoning-intensive information retrieval. DIVER consists of four components: document processing to improve input quality, LLM-driven query expansion via iterative document interaction, a reasoning-enhanced retriever fine-tuned on synthetic multi-domain data with hard negatives, and a pointwise reranker that combines LLM-assigned helpfulness scores with retrieval scores. On the BRIGHT benchmark, DIVER achieves state-of-the-art nDCG@10 scores of 41.6 and 28.9 on original queries, consistently outperforming competitive reasoning-aware models. These results demonstrate the effectiveness of reasoning-aware retrieval strategies in complex real-world tasks. Our code and retrieval model will be released soon.
Neural Combinatorial Optimization via Preference Optimization
Mar 10, 2025
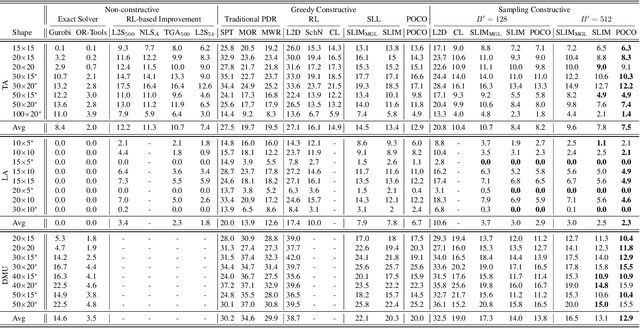


Neural Combinatorial Optimization (NCO) has emerged as a promising approach for NP-hard problems. However, prevailing RL-based methods suffer from low sample efficiency due to sparse rewards and underused solutions. We propose Preference Optimization for Combinatorial Optimization (POCO), a training paradigm that leverages solution preferences via objective values. It introduces: (1) an efficient preference pair construction for better explore and exploit solutions, and (2) a novel loss function that adaptively scales gradients via objective differences, removing reliance on reward models or reference policies. Experiments on Job-Shop Scheduling (JSP), Traveling Salesman (TSP), and Flexible Job-Shop Scheduling (FJSP) show POCO outperforms state-of-the-art neural methods, reducing optimality gaps impressively with efficient inference. POCO is architecture-agnostic, enabling seamless integration with existing NCO models, and establishes preference optimization as a principled framework for combinatorial optimization.
Heterogeneous Interaction Modeling With Reduced Accumulated Error for Multi-Agent Trajectory Prediction
Oct 28, 2024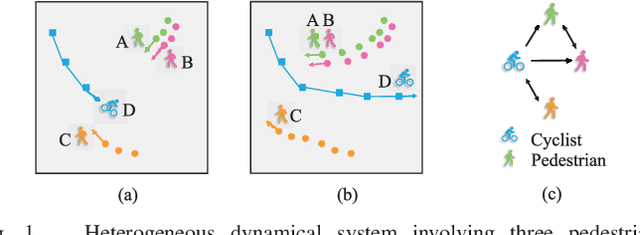
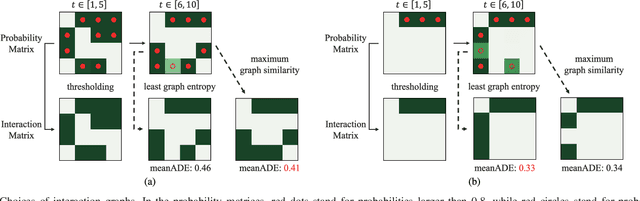
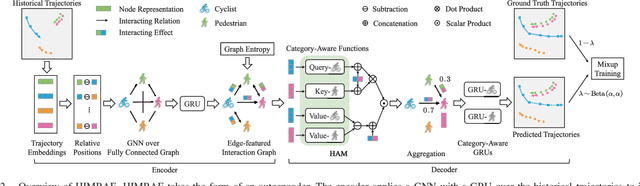
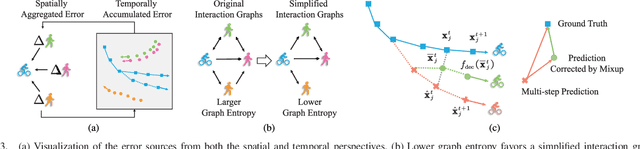
Dynamical complex systems composed of interactive heterogeneous agents are prevalent in the world, including urban traffic systems and social networks. Modeling the interactions among agents is the key to understanding and predicting the dynamics of the complex system, e.g., predicting the trajectories of traffic participants in the city. Compared with interaction modeling in homogeneous systems such as pedestrians in a crowded scene, heterogeneous interaction modeling is less explored. Worse still, the error accumulation problem becomes more severe since the interactions are more complex. To tackle the two problems, this paper proposes heterogeneous interaction modeling with reduced accumulated error for multi-agent trajectory prediction. Based on the historical trajectories, our method infers the dynamic interaction graphs among agents, featured by directed interacting relations and interacting effects. A heterogeneous attention mechanism is defined on the interaction graphs for aggregating the influence from heterogeneous neighbors to the target agent. To alleviate the error accumulation problem, this paper analyzes the error sources from the spatial and temporal perspectives, and proposes to introduce the graph entropy and the mixup training strategy for reducing the two types of errors respectively. Our method is examined on three real-world datasets containing heterogeneous agents, and the experimental results validate the superiority of our method.
A Hierarchical Framework with Spatio-Temporal Consistency Learning for Emergence Detection in Complex Adaptive Systems
Jan 18, 2024


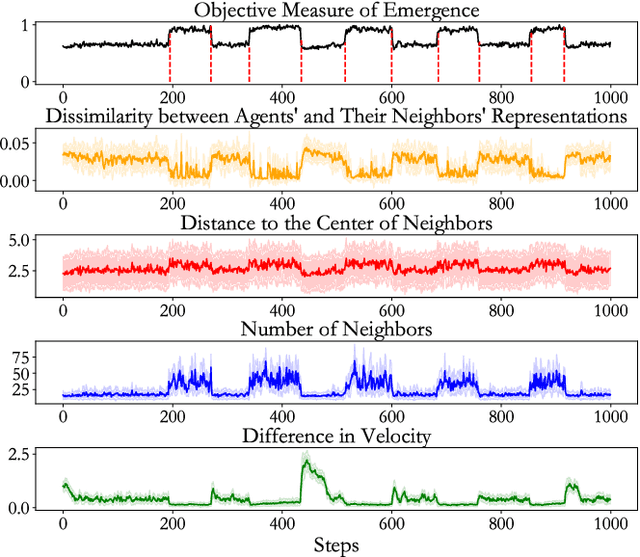
Emergence, a global property of complex adaptive systems (CASs) constituted by interactive agents, is prevalent in real-world dynamic systems, e.g., network-level traffic congestions. Detecting its formation and evaporation helps to monitor the state of a system, allowing to issue a warning signal for harmful emergent phenomena. Since there is no centralized controller of CAS, detecting emergence based on each agent's local observation is desirable but challenging. Existing works are unable to capture emergence-related spatial patterns, and fail to model the nonlinear relationships among agents. This paper proposes a hierarchical framework with spatio-temporal consistency learning to solve these two problems by learning the system representation and agent representations, respectively. Especially, spatio-temporal encoders are tailored to capture agents' nonlinear relationships and the system's complex evolution. Representations of the agents and the system are learned by preserving the intrinsic spatio-temporal consistency in a self-supervised manner. Our method achieves more accurate detection than traditional methods and deep learning methods on three datasets with well-known yet hard-to-detect emergent behaviors. Notably, our hierarchical framework is generic, which can employ other deep learning methods for agent-level and system-level detection.
Efficient Meta Neural Heuristic for Multi-Objective Combinatorial Optimization
Oct 22, 2023



Recently, neural heuristics based on deep reinforcement learning have exhibited promise in solving multi-objective combinatorial optimization problems (MOCOPs). However, they are still struggling to achieve high learning efficiency and solution quality. To tackle this issue, we propose an efficient meta neural heuristic (EMNH), in which a meta-model is first trained and then fine-tuned with a few steps to solve corresponding single-objective subproblems. Specifically, for the training process, a (partial) architecture-shared multi-task model is leveraged to achieve parallel learning for the meta-model, so as to speed up the training; meanwhile, a scaled symmetric sampling method with respect to the weight vectors is designed to stabilize the training. For the fine-tuning process, an efficient hierarchical method is proposed to systematically tackle all the subproblems. Experimental results on the multi-objective traveling salesman problem (MOTSP), multi-objective capacitated vehicle routing problem (MOCVRP), and multi-objective knapsack problem (MOKP) show that, EMNH is able to outperform the state-of-the-art neural heuristics in terms of solution quality and learning efficiency, and yield competitive solutions to the strong traditional heuristics while consuming much shorter time.
Neural Multi-Objective Combinatorial Optimization with Diversity Enhancement
Oct 22, 2023


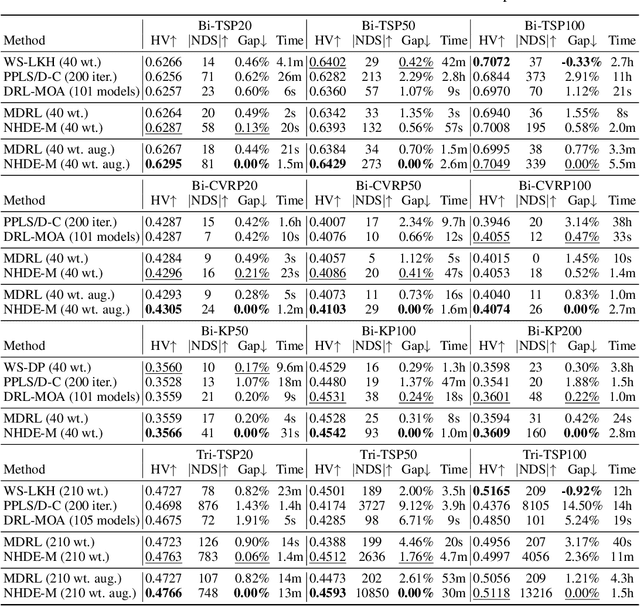
Most of existing neural methods for multi-objective combinatorial optimization (MOCO) problems solely rely on decomposition, which often leads to repetitive solutions for the respective subproblems, thus a limited Pareto set. Beyond decomposition, we propose a novel neural heuristic with diversity enhancement (NHDE) to produce more Pareto solutions from two perspectives. On the one hand, to hinder duplicated solutions for different subproblems, we propose an indicator-enhanced deep reinforcement learning method to guide the model, and design a heterogeneous graph attention mechanism to capture the relations between the instance graph and the Pareto front graph. On the other hand, to excavate more solutions in the neighborhood of each subproblem, we present a multiple Pareto optima strategy to sample and preserve desirable solutions. Experimental results on classic MOCO problems show that our NHDE is able to generate a Pareto front with higher diversity, thereby achieving superior overall performance. Moreover, our NHDE is generic and can be applied to different neural methods for MOCO.
Democratizing Reasoning Ability: Tailored Learning from Large Language Model
Oct 20, 2023



Large language models (LLMs) exhibit impressive emergent abilities in natural language processing, but their democratization is hindered due to huge computation requirements and closed-source nature. Recent research on advancing open-source smaller LMs by distilling knowledge from black-box LLMs has obtained promising results in the instruction-following ability. However, the reasoning ability which is more challenging to foster, is relatively rarely explored. In this paper, we propose a tailored learning approach to distill such reasoning ability to smaller LMs to facilitate the democratization of the exclusive reasoning ability. In contrast to merely employing LLM as a data annotator, we exploit the potential of LLM as a reasoning teacher by building an interactive multi-round learning paradigm. This paradigm enables the student to expose its deficiencies to the black-box teacher who then can provide customized training data in return. Further, to exploit the reasoning potential of the smaller LM, we propose self-reflection learning to motivate the student to learn from self-made mistakes. The learning from self-reflection and LLM are all tailored to the student's learning status, thanks to the seamless integration with the multi-round learning paradigm. Comprehensive experiments and analysis on mathematical and commonsense reasoning tasks demonstrate the effectiveness of our method. The code will be available at https://github.com/Raibows/Learn-to-Reason.
Adaptive-Solver Framework for Dynamic Strategy Selection in Large Language Model Reasoning
Oct 01, 2023



Large Language Models (LLMs) are showcasing impressive ability in handling complex reasoning tasks. In real-world situations, problems often span a spectrum of complexities. Humans inherently adjust their problem-solving approaches based on task complexity. However, most methodologies that leverage LLMs tend to adopt a uniform approach: utilizing consistent models, prompting methods, and degrees of problem decomposition, regardless of the problem complexity. Inflexibility of them can bring unnecessary computational overhead or sub-optimal performance. To address this problem, we introduce an Adaptive-Solver framework. It strategically modulates solving strategies based on the difficulties of the problems. Given an initial solution, the framework functions with two primary modules. The initial evaluation module assesses the adequacy of the current solution. If improvements are needed, the subsequent adaptation module comes into play. Within this module, three key adaptation strategies are employed: (1) Model Adaptation: Switching to a stronger LLM when a weaker variant is inadequate. (2) Prompting Method Adaptation: Alternating between different prompting techniques to suit the problem's nuances. (3) Decomposition Granularity Adaptation: Breaking down a complex problem into more fine-grained sub-questions to enhance solvability. Through such dynamic adaptations, our framework not only enhances computational efficiency but also elevates the overall performance. This dual-benefit ensures both the efficiency of the system for simpler tasks and the precision required for more complex questions. Experimental results from complex reasoning tasks reveal that the prompting method adaptation and decomposition granularity adaptation enhance performance across all tasks. Furthermore, the model adaptation approach significantly reduces API costs (up to 50%) while maintaining superior performance.
Disentangling Reasoning Capabilities from Language Models with Compositional Reasoning Transformers
Oct 20, 2022
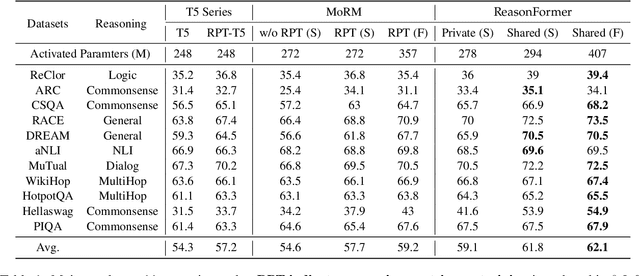


This paper presents ReasonFormer, a unified reasoning framework for mirroring the modular and compositional reasoning process of humans in complex decision making. Inspired by dual-process theory in cognitive science, the representation module (automatic thinking) and reasoning modules (controlled thinking) are disentangled to capture different levels of cognition. Upon the top of the representation module, the pre-trained reasoning modules are modular and expertise in specific and fundamental reasoning skills (e.g., logic, simple QA, etc). To mimic the controlled compositional thinking process, different reasoning modules are dynamically activated and composed in both parallel and cascaded manners to control what reasoning skills are activated and how deep the reasoning process will be reached to solve the current problems. The unified reasoning framework solves multiple tasks with a single model,and is trained and inferred in an end-to-end manner. Evaluated on 11 datasets requiring different reasoning skills and complexity, ReasonFormer demonstrates substantial performance boosts, revealing the compositional reasoning ability. Few-shot experiments exhibit better generalization ability by learning to compose pre-trained skills for new tasks with limited data,and decoupling the representation module and the reasoning modules. Further analysis shows the modularity of reasoning modules as different tasks activate distinct reasoning skills at different reasoning depths.