 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-aware Decoding for Neural Asymmetric Routing
Jun 01, 2026Neural asymmetric routing models increasingly encode directionality through matrix representations and asymmetry-aware attention. The final routing action, however, is not a node in isolation but a directed transition chosen under the current partial route. This creates a representation--decision mismatch: pairwise cost information may be encoded upstream while the final candidate logit is still largely parameterized as context--node compatibility. We propose a decoder-design principle for neural asymmetric routing: the final score should explicitly expose transition-level quantities suggested by the problem's cost-to-go structure. We instantiate this principle with an edge-aware decoder that adds candidate-specific terms for the current directed edge, return-to-start closure, and static lightweight lookahead, while keeping the representation backbone fixed. On a controlled SVD/Sinkhorn asymmetric backbone, the decoder improves over the RADAR reference when trained on ATSP-100 and evaluated zero-shot on ATSP-100/200/500/1000, reducing the ATSP-1000 gap from $4.13\%$ to $2.73\%$. On ACVRP, the same score-level modification shows the same qualitative trend under a richer routing state. ATSP ablations and directed-transition diagnostics sharpen the mechanism: the strongest evidence concerns sensitivity to the current directed edge, while closure and static lookahead act as heuristic continuation cues. The results support a mechanism study: a key decoder-side signal in neural asymmetric routing is decision-time exposure of transition-level edge information.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
UCPO: A Universal Constrained Combinatorial Optimization Method via Preference Optimization
Nov 13, 2025Neural solvers have demonstrated remarkable success in combinatorial optimization, often surpassing traditional heuristics in speed, solution quality, and generalization. However, their efficacy deteriorates significantly when confronted with complex constraints that cannot be effectively managed through simple masking mechanisms. To address this limitation, we introduce Universal Constrained Preference Optimization (UCPO), a novel plug-and-play framework that seamlessly integrates preference learning into existing neural solvers via a specially designed loss function, without requiring architectural modifications. UCPO embeds constraint satisfaction directly into a preference-based objective, eliminating the need for meticulous hyperparameter tuning. Leveraging a lightweight warm-start fine-tuning protocol, UCPO enables pre-trained models to consistently produce near-optimal, feasible solutions on challenging constraint-laden tasks, achieving exceptional performance with as little as 1\% of the original training budget.
Neural Combinatorial Optimization via Preference Optimization
Mar 10, 2025
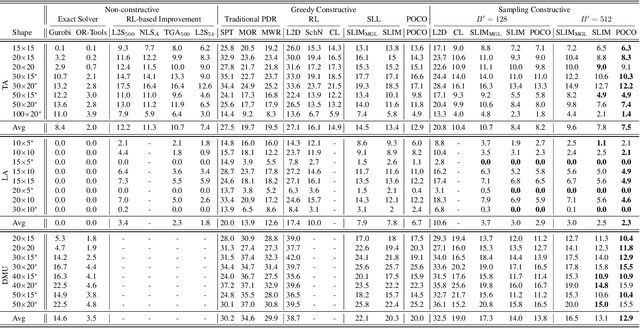


Neural Combinatorial Optimization (NCO) has emerged as a promising approach for NP-hard problems. However, prevailing RL-based methods suffer from low sample efficiency due to sparse rewards and underused solutions. We propose Preference Optimization for Combinatorial Optimization (POCO), a training paradigm that leverages solution preferences via objective values. It introduces: (1) an efficient preference pair construction for better explore and exploit solutions, and (2) a novel loss function that adaptively scales gradients via objective differences, removing reliance on reward models or reference policies. Experiments on Job-Shop Scheduling (JSP), Traveling Salesman (TSP), and Flexible Job-Shop Scheduling (FJSP) show POCO outperforms state-of-the-art neural methods, reducing optimality gaps impressively with efficient inference. POCO is architecture-agnostic, enabling seamless integration with existing NCO models, and establishes preference optimization as a principled framework for combinatorial optimization.
Efficient Meta Neural Heuristic for Multi-Objective Combinatorial Optimization
Oct 22, 2023



Recently, neural heuristics based on deep reinforcement learning have exhibited promise in solving multi-objective combinatorial optimization problems (MOCOPs). However, they are still struggling to achieve high learning efficiency and solution quality. To tackle this issue, we propose an efficient meta neural heuristic (EMNH), in which a meta-model is first trained and then fine-tuned with a few steps to solve corresponding single-objective subproblems. Specifically, for the training process, a (partial) architecture-shared multi-task model is leveraged to achieve parallel learning for the meta-model, so as to speed up the training; meanwhile, a scaled symmetric sampling method with respect to the weight vectors is designed to stabilize the training. For the fine-tuning process, an efficient hierarchical method is proposed to systematically tackle all the subproblems. Experimental results on the multi-objective traveling salesman problem (MOTSP), multi-objective capacitated vehicle routing problem (MOCVRP), and multi-objective knapsack problem (MOKP) show that, EMNH is able to outperform the state-of-the-art neural heuristics in terms of solution quality and learning efficiency, and yield competitive solutions to the strong traditional heuristics while consuming much shorter time.
Neural Multi-Objective Combinatorial Optimization with Diversity Enhancement
Oct 22, 2023


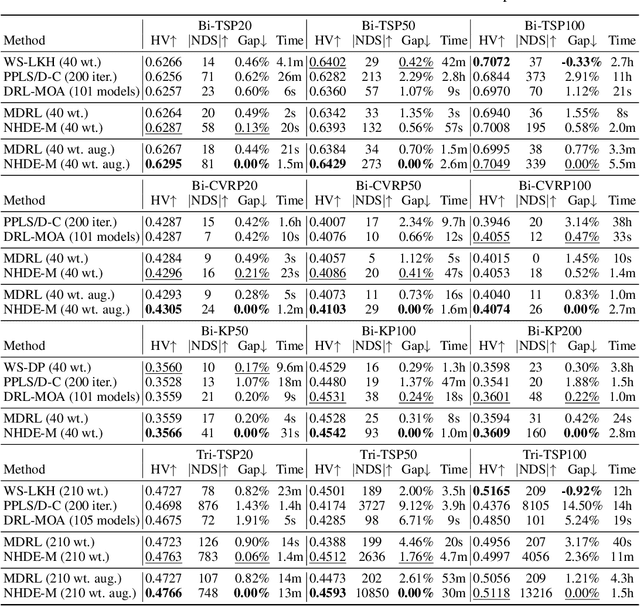
Most of existing neural methods for multi-objective combinatorial optimization (MOCO) problems solely rely on decomposition, which often leads to repetitive solutions for the respective subproblems, thus a limited Pareto set. Beyond decomposition, we propose a novel neural heuristic with diversity enhancement (NHDE) to produce more Pareto solutions from two perspectives. On the one hand, to hinder duplicated solutions for different subproblems, we propose an indicator-enhanced deep reinforcement learning method to guide the model, and design a heterogeneous graph attention mechanism to capture the relations between the instance graph and the Pareto front graph. On the other hand, to excavate more solutions in the neighborhood of each subproblem, we present a multiple Pareto optima strategy to sample and preserve desirable solutions. Experimental results on classic MOCO problems show that our NHDE is able to generate a Pareto front with higher diversity, thereby achieving superior overall performance. Moreover, our NHDE is generic and can be applied to different neural methods for MOCO.
MODRL/D-EL: Multiobjective Deep Reinforcement Learning with Evolutionary Learning for Multiobjective Optimization
Jul 16, 2021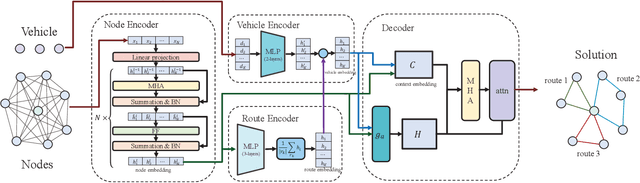
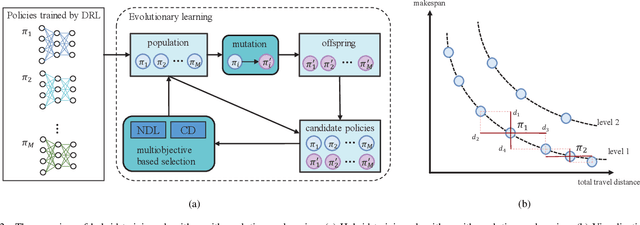

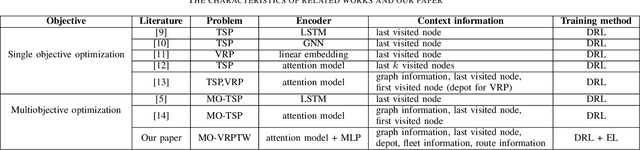
Learning-based heuristics for solving combinatorial optimization problems has recently attracted much academic attention. While most of the existing works only consider the single objective problem with simple constraints, many real-world problems have the multiobjective perspective and contain a rich set of constraints. This paper proposes a multiobjective deep reinforcement learning with evolutionary learning algorithm for a typical complex problem called the multiobjective vehicle routing problem with time windows (MO-VRPTW). In the proposed algorithm, the decomposition strategy is applied to generate subproblems for a set of attention models. The comprehensive context information is introduced to further enhance the attention models. The evolutionary learning is also employed to fine-tune the parameters of the models. The experimental results on MO-VRPTW instances demonstrate the superiority of the proposed algorithm over other learning-based and iterative-based approaches.
Meta-Learning-based Deep Reinforcement Learning for Multiobjective Optimization Problems
May 06, 2021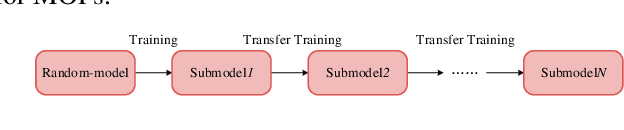
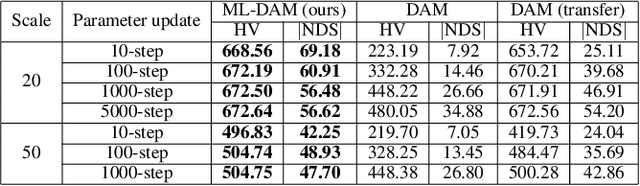
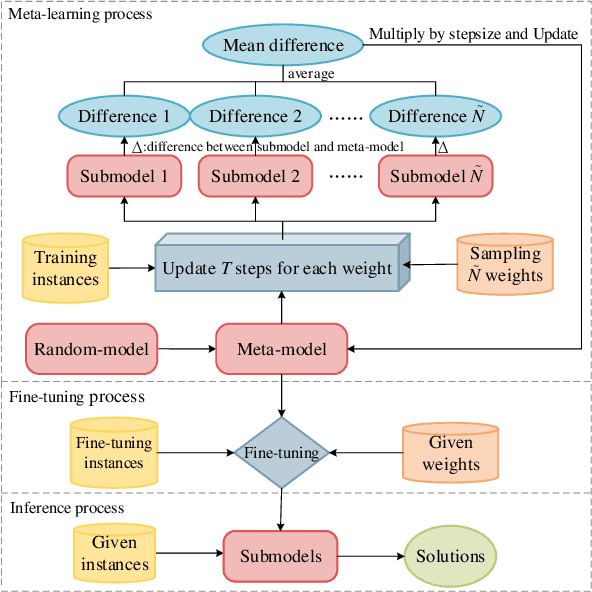
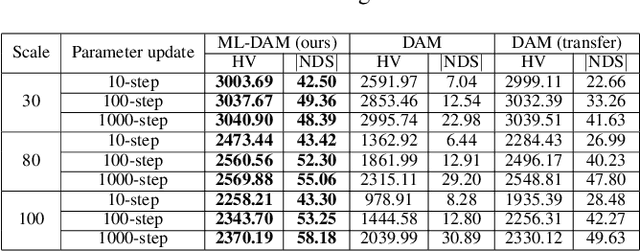
Deep reinforcement learning (DRL) has recently shown its success in tackling complex combinatorial optimization problems. When these problems are extended to multiobjective ones, it becomes difficult for the existing DRL approaches to flexibly and efficiently deal with multiple subproblems determined by weight decomposition of objectives. This paper proposes a concise meta-learning-based DRL approach. It first trains a meta-model by meta-learning. The meta-model is fine-tuned with a few update steps to derive submodels for the corresponding subproblems. The Pareto front is built accordingly. The computational experiments on multiobjective traveling salesman problems demonstrate the superiority of our method over most of learning-based and iteration-based approaches.
MODRL/D-AM: Multiobjective Deep Reinforcement Learning Algorithm Using Decomposition and Attention Model for Multiobjective Optimization
Feb 13, 2020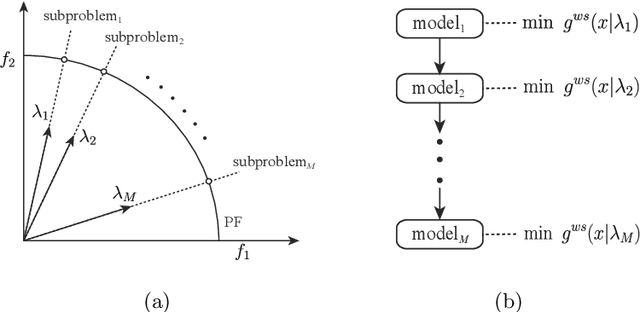
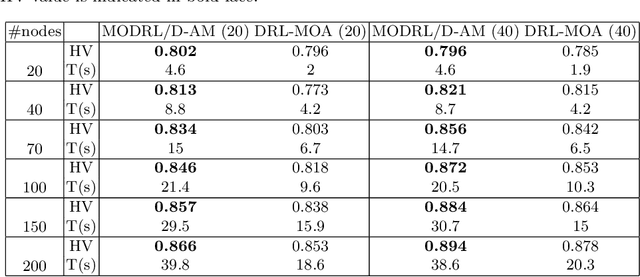
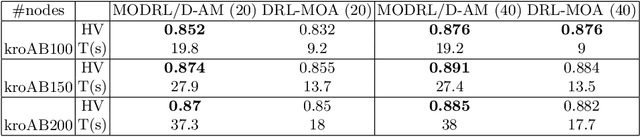
Recently, a deep reinforcement learning method is proposed to solve multiobjective optimization problem. In this method, the multiobjective optimization problem is decomposed to a number of single-objective optimization subproblems and all the subproblems are optimized in a collaborative manner. Each subproblem is modeled with a pointer network and the model is trained with reinforcement learning. However, when pointer network extracts the features of an instance, it ignores the underlying structure information of the input nodes. Thus, this paper proposes a multiobjective deep reinforcement learning method using decomposition and attention model to solve multiobjective optimization problem. In our method, each subproblem is solved by an attention model, which can exploit the structure features as well as node features of input nodes. The experiment results on multiobjective travelling salesman problem show the proposed algorithm achieves better performance compared with the previous method.
A Deep Reinforcement Learning Algorithm Using Dynamic Attention Model for Vehicle Routing Problems
Feb 09, 2020


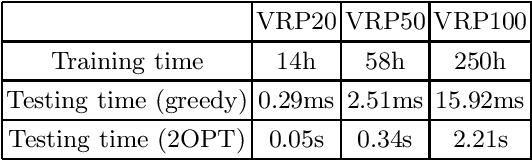
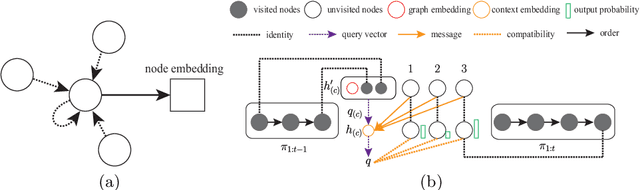
Recent researches show that machine learning has the potential to learn better heuristics than the one designed by human for solving combinatorial optimization problems. The deep neural network is used to characterize the input instance for constructing a feasible solution incrementally. Recently, an attention model is proposed to solve routing problems. In this model, the state of an instance is represented by node features that are fixed over time. However, the fact is, the state of an instance is changed according to the decision that the model made at different construction steps, and the node features should be updated correspondingly. Therefore, this paper presents a dynamic attention model with dynamic encoder-decoder architecture, which enables the model to explore node features dynamically and exploit hidden structure information effectively at different construction steps. This paper focuses on a challenging NP-hard problem, vehicle routing problem. The experiments indicate that our model outperforms the previous methods and also shows a good generalization performance.