 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProteus: A Self-Designing Range Filter
Jun 30, 2022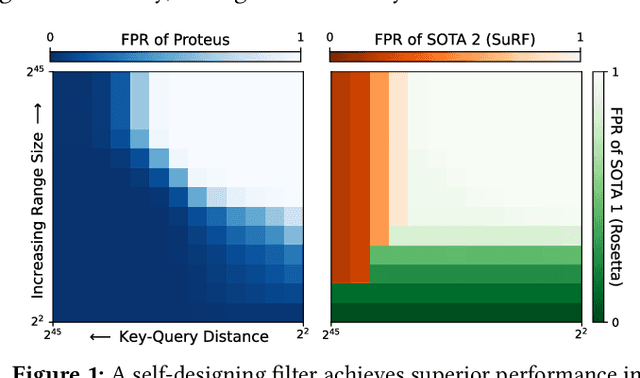

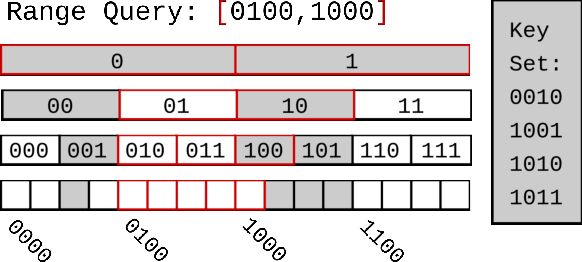
We introduce Proteus, a novel self-designing approximate range filter, which configures itself based on sampled data in order to optimize its false positive rate (FPR) for a given space requirement. Proteus unifies the probabilistic and deterministic design spaces of state-of-the-art range filters to achieve robust performance across a larger variety of use cases. At the core of Proteus lies our Contextual Prefix FPR (CPFPR) model - a formal framework for the FPR of prefix-based filters across their design spaces. We empirically demonstrate the accuracy of our model and Proteus' ability to optimize over both synthetic workloads and real-world datasets. We further evaluate Proteus in RocksDB and show that it is able to improve end-to-end performance by as much as 5.3x over more brittle state-of-the-art methods such as SuRF and Rosetta. Our experiments also indicate that the cost of modeling is not significant compared to the end-to-end performance gains and that Proteus is robust to workload shifts.
* 14 pages, 9 figures, originally published in the Proceedings of the 2022 International Conference on Management of Data (SIGMOD'22), ISBN: 9781450392495
Heterogeneous Attentions for Solving Pickup and Delivery Problem via Deep Reinforcement Learning
Oct 06, 2021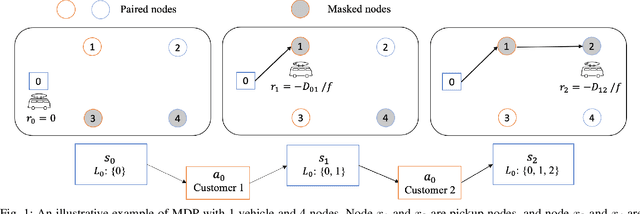
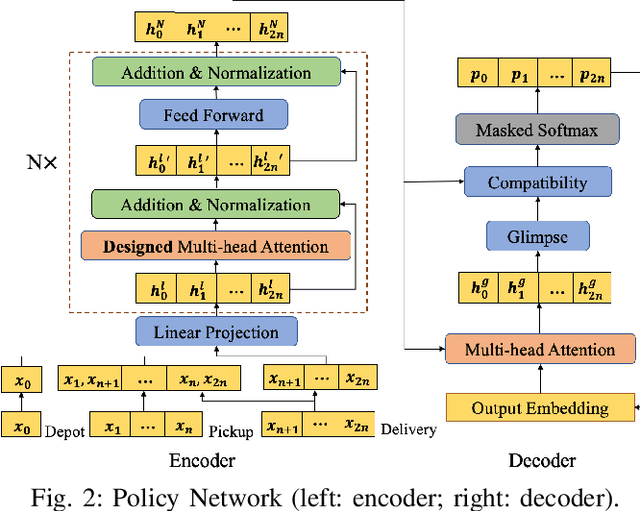
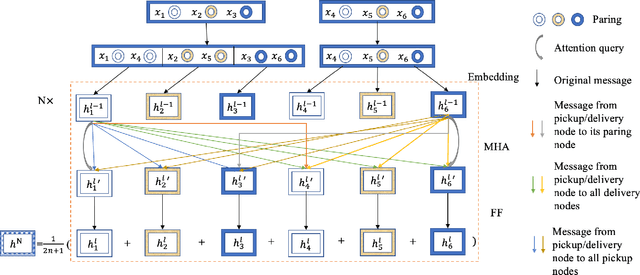
Recently, there is an emerging trend to apply deep reinforcement learning to solve the vehicle routing problem (VRP), where a learnt policy governs the selection of next node for visiting. However, existing methods could not handle well the pairing and precedence relationships in the pickup and delivery problem (PDP), which is a representative variant of VRP. To address this challenging issue, we leverage a novel neural network integrated with a heterogeneous attention mechanism to empower the policy in deep reinforcement learning to automatically select the nodes. In particular, the heterogeneous attention mechanism specifically prescribes attentions for each role of the nodes while taking into account the precedence constraint, i.e., the pickup node must precede the pairing delivery node. Further integrated with a masking scheme, the learnt policy is expected to find higher-quality solutions for solving PDP. Extensive experimental results show that our method outperforms the state-of-the-art heuristic and deep learning model, respectively, and generalizes well to different distributions and problem sizes.
Deep Reinforcement Learning for Solving the Heterogeneous Capacitated Vehicle Routing Problem
Oct 06, 2021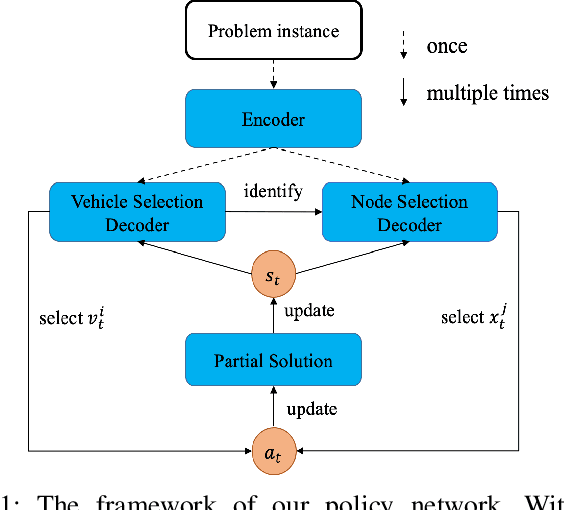
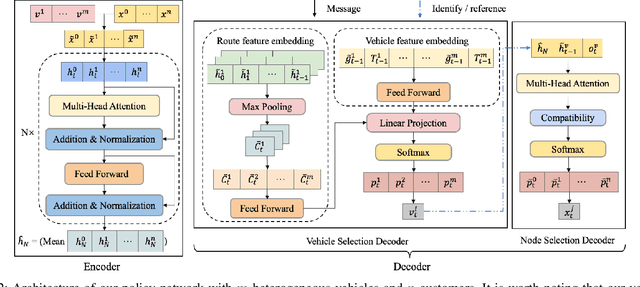
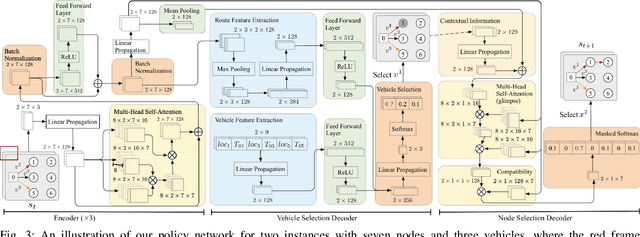
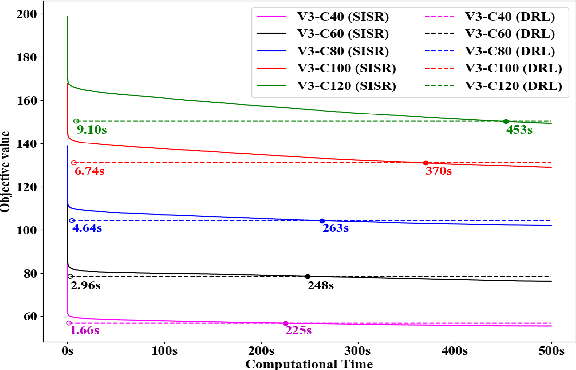
Existing deep reinforcement learning (DRL) based methods for solving the capacitated vehicle routing problem (CVRP) intrinsically cope with homogeneous vehicle fleet, in which the fleet is assumed as repetitions of a single vehicle. Hence, their key to construct a solution solely lies in the selection of the next node (customer) to visit excluding the selection of vehicle. However, vehicles in real-world scenarios are likely to be heterogeneous with different characteristics that affect their capacity (or travel speed), rendering existing DRL methods less effective. In this paper, we tackle heterogeneous CVRP (HCVRP), where vehicles are mainly characterized by different capacities. We consider both min-max and min-sum objectives for HCVRP, which aim to minimize the longest or total travel time of the vehicle(s) in the fleet. To solve those problems, we propose a DRL method based on the attention mechanism with a vehicle selection decoder accounting for the heterogeneous fleet constraint and a node selection decoder accounting for the route construction, which learns to construct a solution by automatically selecting both a vehicle and a node for this vehicle at each step. Experimental results based on randomly generated instances show that, with desirable generalization to various problem sizes, our method outperforms the state-of-the-art DRL method and most of the conventional heuristics, and also delivers competitive performance against the state-of-the-art heuristic method, i.e., SISR. Additionally, the results of extended experiments demonstrate that our method is also able to solve CVRPLib instances with satisfactory performance.
PointBA: Towards Backdoor Attacks in 3D Point Cloud
Mar 30, 2021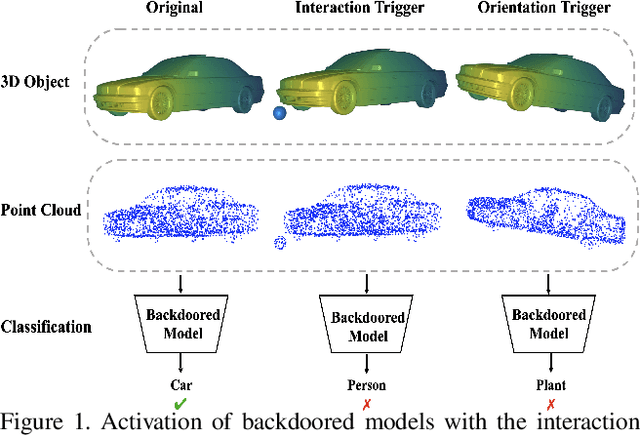

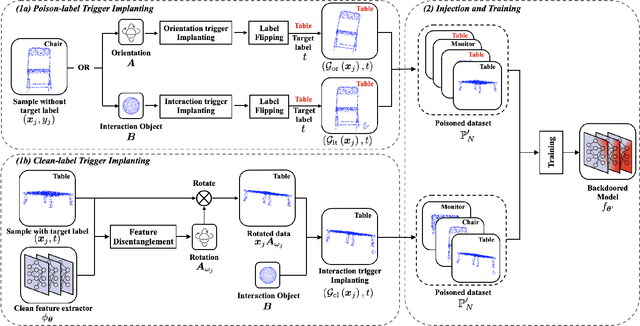

3D deep learning has been increasingly more popular for a variety of tasks including many safety-critical applications. However, recently several works raise the security issues of 3D deep nets. Although most of these works consider adversarial attacks, we identify that backdoor attack is indeed a more serious threat to 3D deep learning systems but remains unexplored. We present the backdoor attacks in 3D with a unified framework that exploits the unique properties of 3D data and networks. In particular, we design two attack approaches: the poison-label attack and the clean-label attack. The first one is straightforward and effective in practice, while the second one is more sophisticated assuming there are certain data inspections. The attack algorithms are mainly motivated and developed by 1) the recent discovery of 3D adversarial samples which demonstrate the vulnerability of 3D deep nets under spatial transformations; 2) the proposed feature disentanglement technique that manipulates the feature of the data through optimization methods and its potential to embed a new task. Extensive experiments show the efficacy of the poison-label attack with over 95% success rate across several 3D datasets and models, and the ability of clean-label attack against data filtering with around 50% success rate. Our proposed backdoor attack in 3D point cloud is expected to perform as a baseline for improving the robustness of 3D deep models.
An Exponential Factorization Machine with Percentage Error Minimization to Retail Sales Forecasting
Sep 22, 2020
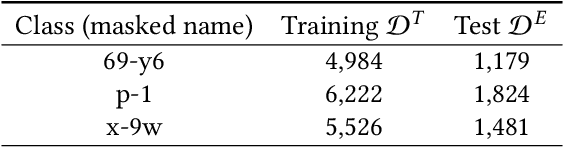

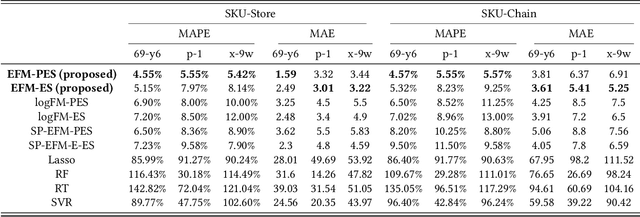
This paper proposes a new approach to sales forecasting for new products with long lead time but short product life cycle. These SKUs are usually sold for one season only, without any replenishments. An exponential factorization machine (EFM) sales forecast model is developed to solve this problem which not only considers SKU attributes, but also pairwise interactions. The EFM model is significantly different from the original Factorization Machines (FM) from two-fold: (1) the attribute-level formulation for explanatory variables and (2) exponential formulation for the positive response variable. The attribute-level formation excludes infeasible intra-attribute interactions and results in more efficient feature engineering comparing with the conventional one-hot encoding, while the exponential formulation is demonstrated more effective than the log-transformation for the positive but not skewed distributed responses. In order to estimate the parameters, percentage error squares (PES) and error squares (ES) are minimized by a proposed adaptive batch gradient descent method over the training set. Real-world data provided by a footwear retailer in Singapore is used for testing the proposed approach. The forecasting performance in terms of both mean absolute percentage error (MAPE) and mean absolute error (MAE) compares favourably with not only off-the-shelf models but also results reported by extant sales and demand forecasting studies. The effectiveness of the proposed approach is also demonstrated by two external public datasets. Moreover, we prove the theoretical relationships between PES and ES minimization, and present an important property of the PES minimization for regression models; that it trains models to underestimate data. This property fits the situation of sales forecasting where unit-holding cost is much greater than the unit-shortage cost.
* Accepted by ACM Transactions on Knowledge Discovery from Data (ACM TKDD)
Revisiting Modified Greedy Algorithm for Monotone Submodular Maximization with a Knapsack Constraint
Aug 12, 2020

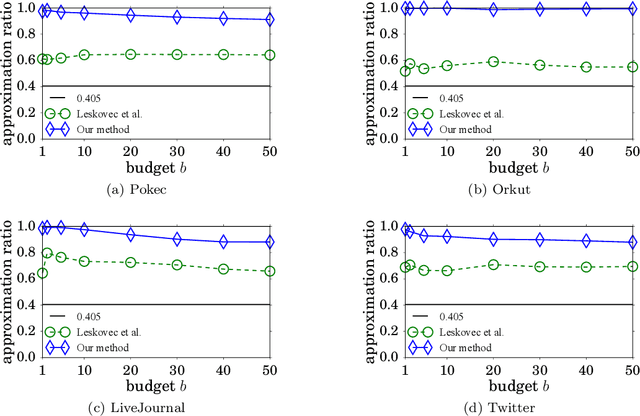
Monotone submodular maximization with a knapsack constraint is NP-hard. Various approximation algorithms have been devised to address this optimization problem. In this paper, we revisit the widely known modified greedy algorithm. First, we show that this algorithm can achieve an approximation factor of $0.405$, which significantly improves the known factor of $0.357$ given by Wolsey or $(1-1/\mathrm{e})/2\approx 0.316$ given by Khuller et al. More importantly, our analysis uncovers a gap in Khuller et al.'s proof for the extensively mentioned approximation factor of $(1-1/\sqrt{\mathrm{e}})\approx 0.393$ in the literature to clarify a long time of misunderstanding on this issue. Second, we enhance the modified greedy algorithm to derive a data-dependent upper bound on the optimum. We empirically demonstrate the tightness of our upper bound with a real-world application. The bound enables us to obtain a data-dependent ratio typically much higher than $0.405$ between the solution value of the modified greedy algorithm and the optimum. It can also be used to significantly improve the efficiency of algorithms such as branch and bound.
Campus3D: A Photogrammetry Point Cloud Benchmark for Hierarchical Understanding of Outdoor Scene
Aug 11, 2020
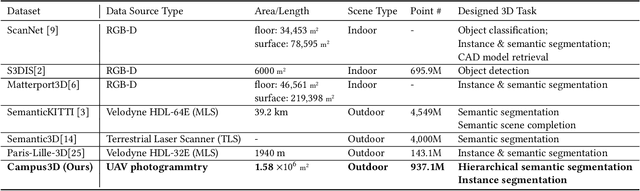

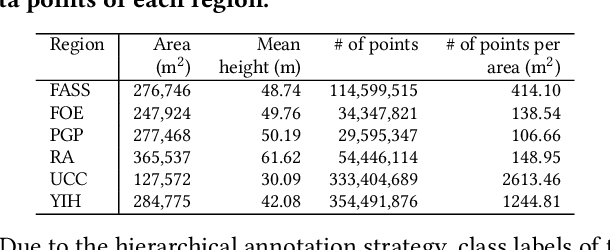
Learning on 3D scene-based point cloud has received extensive attention as its promising application in many fields, and well-annotated and multisource datasets can catalyze the development of those data-driven approaches. To facilitate the research of this area, we present a richly-annotated 3D point cloud dataset for multiple outdoor scene understanding tasks and also an effective learning framework for its hierarchical segmentation task. The dataset was generated via the photogrammetric processing on unmanned aerial vehicle (UAV) images of the National University of Singapore (NUS) campus, and has been point-wisely annotated with both hierarchical and instance-based labels. Based on it, we formulate a hierarchical learning problem for 3D point cloud segmentation and propose a measurement evaluating consistency across various hierarchies. To solve this problem, a two-stage method including multi-task (MT) learning and hierarchical ensemble (HE) with consistency consideration is proposed. Experimental results demonstrate the superiority of the proposed method and potential advantages of our hierarchical annotations. In addition, we benchmark results of semantic and instance segmentation, which is accessible online at https://3d.dataset.site with the dataset and all source codes.
* Accepted by the 28th ACM International Conference on Multimedia (ACM MM 2020)
Directed Graph Convolutional Network
Apr 29, 2020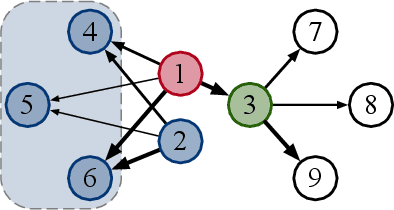
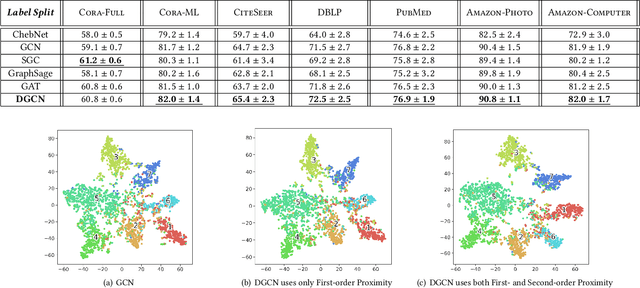
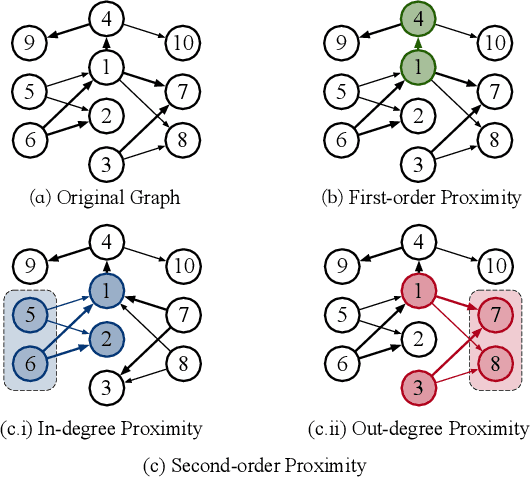
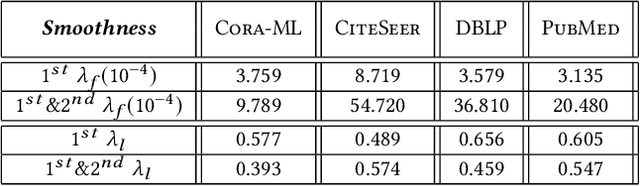
Graph Convolutional Networks (GCNs) have been widely used due to their outstanding performance in processing graph-structured data. However, the undirected graphs limit their application scope. In this paper, we extend spectral-based graph convolution to directed graphs by using first- and second-order proximity, which can not only retain the connection properties of the directed graph, but also expand the receptive field of the convolution operation. A new GCN model, called DGCN, is then designed to learn representations on the directed graph, leveraging both the first- and second-order proximity information. We empirically show the fact that GCNs working only with DGCNs can encode more useful information from graph and help achieve better performance when generalized to other models. Moreover, extensive experiments on citation networks and co-purchase datasets demonstrate the superiority of our model against the state-of-the-art methods.
On Isometry Robustness of Deep 3D Point Cloud Models under Adversarial Attacks
Mar 10, 2020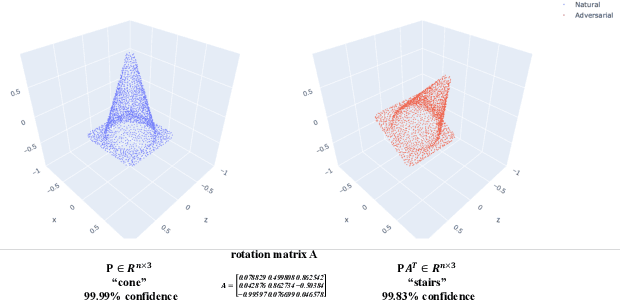
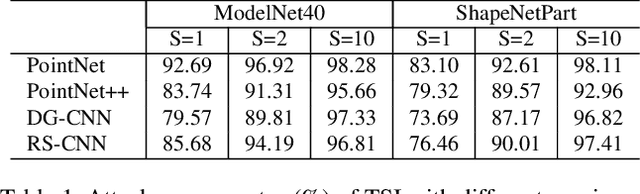
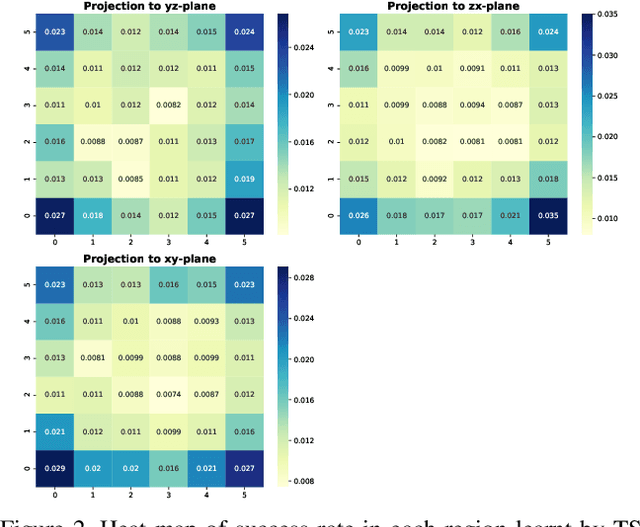
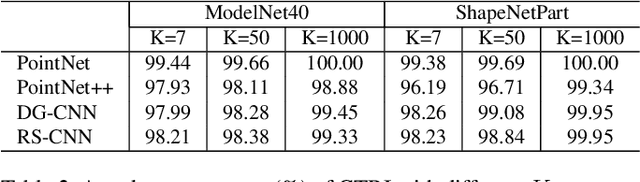
While deep learning in 3D domain has achieved revolutionary performance in many tasks, the robustness of these models has not been sufficiently studied or explored. Regarding the 3D adversarial samples, most existing works focus on manipulation of local points, which may fail to invoke the global geometry properties, like robustness under linear projection that preserves the Euclidean distance, i.e., isometry. In this work, we show that existing state-of-the-art deep 3D models are extremely vulnerable to isometry transformations. Armed with the Thompson Sampling, we develop a black-box attack with success rate over 95% on ModelNet40 data set. Incorporating with the Restricted Isometry Property, we propose a novel framework of white-box attack on top of spectral norm based perturbation. In contrast to previous works, our adversarial samples are experimentally shown to be strongly transferable. Evaluated on a sequence of prevailing 3D models, our white-box attack achieves success rates from 98.88% to 100%. It maintains a successful attack rate over 95% even within an imperceptible rotation range $[\pm 2.81^{\circ}]$.
Learning Variable Ordering Heuristics for Solving Constraint Satisfaction Problems
Dec 23, 2019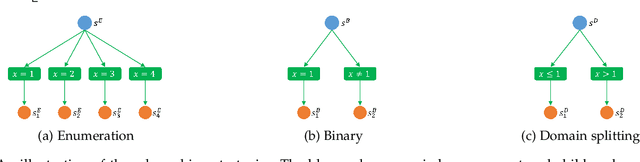
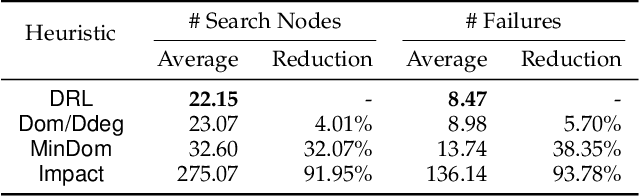
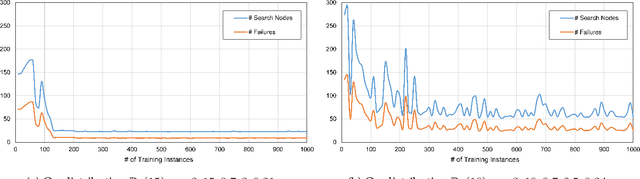
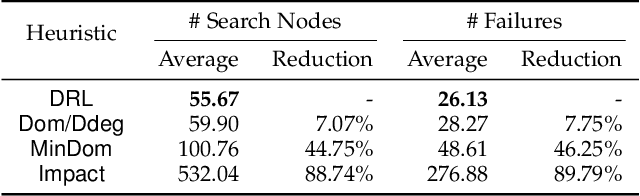
Backtracking search algorithms are often used to solve the Constraint Satisfaction Problem (CSP). The efficiency of backtracking search depends greatly on the variable ordering heuristics. Currently, the most commonly used heuristics are hand-crafted based on expert knowledge. In this paper, we propose a deep reinforcement learning based approach to automatically discover new variable ordering heuristics that are better adapted for a given class of CSP instances. We show that directly optimizing the search cost is hard for bootstrapping, and propose to optimize the expected cost of reaching a leaf node in the search tree. To capture the complex relations among the variables and constraints, we design a representation scheme based on Graph Neural Network that can process CSP instances with different sizes and constraint arities. Experimental results on random CSP instances show that the learned policies outperform classical hand-crafted heuristics in terms of minimizing the search tree size, and can effectively generalize to instances that are larger than those used in training.