 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIgnoring Directionality Leads to Compromised Graph Neural Network Explanations
Jun 05, 2025Graph Neural Networks (GNNs) are increasingly used in critical domains, where reliable explanations are vital for supporting human decision-making. However, the common practice of graph symmetrization discards directional information, leading to significant information loss and misleading explanations. Our analysis demonstrates how this practice compromises explanation fidelity. Through theoretical and empirical studies, we show that preserving directional semantics significantly improves explanation quality, ensuring more faithful insights for human decision-makers. These findings highlight the need for direction-aware GNN explainability in security-critical applications.
Generalizing Neural Networks by Reflecting Deviating Data in Production
Oct 06, 2021
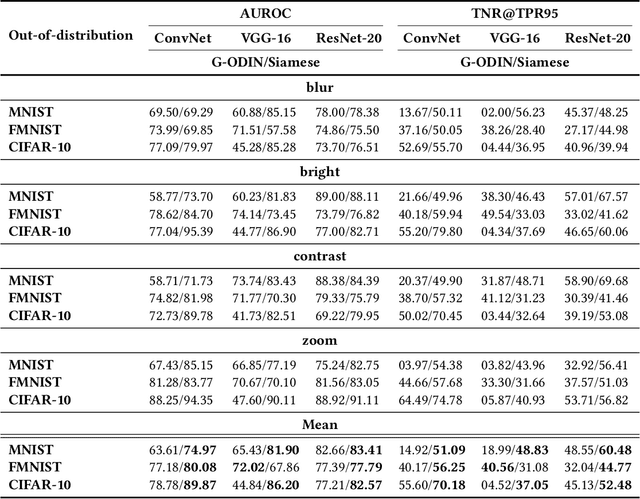
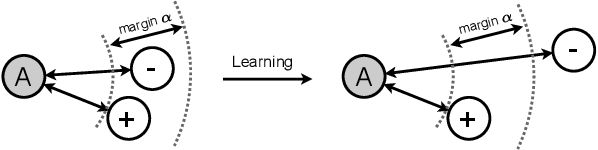
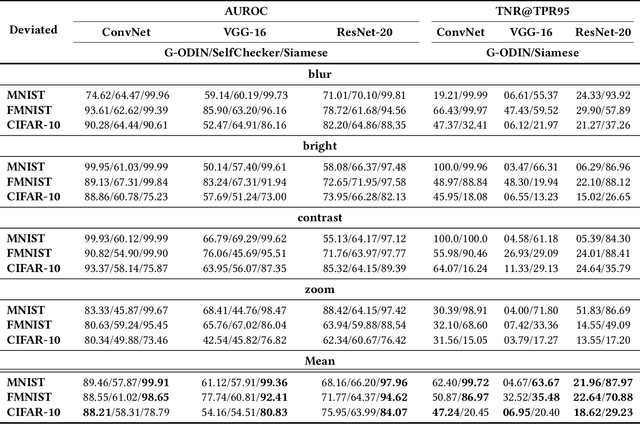
Trained with a sufficiently large training and testing dataset, Deep Neural Networks (DNNs) are expected to generalize. However, inputs may deviate from the training dataset distribution in real deployments. This is a fundamental issue with using a finite dataset. Even worse, real inputs may change over time from the expected distribution. Taken together, these issues may lead deployed DNNs to mis-predict in production. In this work, we present a runtime approach that mitigates DNN mis-predictions caused by the unexpected runtime inputs to the DNN. In contrast to previous work that considers the structure and parameters of the DNN itself, our approach treats the DNN as a blackbox and focuses on the inputs to the DNN. Our approach has two steps. First, it recognizes and distinguishes "unseen" semantically-preserving inputs. For this we use a distribution analyzer based on the distance metric learned by a Siamese network. Second, our approach transforms those unexpected inputs into inputs from the training set that are identified as having similar semantics. We call this process input reflection and formulate it as a search problem over the embedding space on the training set. This embedding space is learned by a Quadruplet network as an auxiliary model for the subject model to improve the generalization. We implemented a tool called InputReflector based on the above two-step approach and evaluated it with experiments on three DNN models trained on CIFAR-10, MNIST, and FMINST image datasets. The results show that InputReflector can effectively distinguish inputs that retain semantics of the distribution (e.g., blurred, brightened, contrasted, and zoomed images) and out-of-distribution inputs from normal inputs.
Directed Graph Convolutional Network
Apr 29, 2020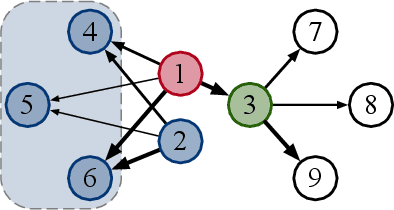
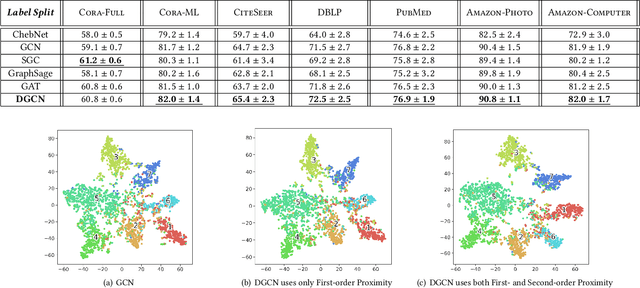
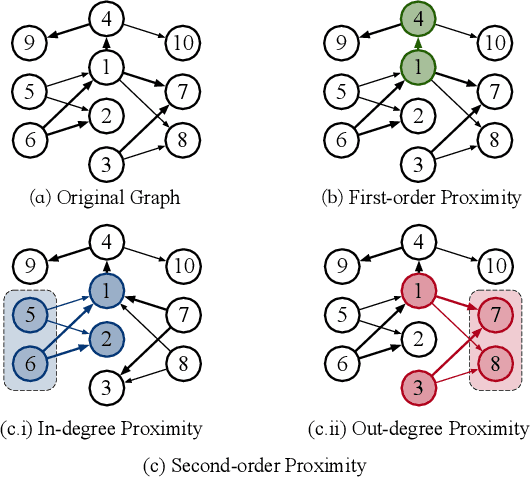
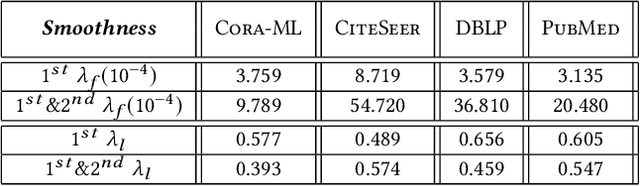
Graph Convolutional Networks (GCNs) have been widely used due to their outstanding performance in processing graph-structured data. However, the undirected graphs limit their application scope. In this paper, we extend spectral-based graph convolution to directed graphs by using first- and second-order proximity, which can not only retain the connection properties of the directed graph, but also expand the receptive field of the convolution operation. A new GCN model, called DGCN, is then designed to learn representations on the directed graph, leveraging both the first- and second-order proximity information. We empirically show the fact that GCNs working only with DGCNs can encode more useful information from graph and help achieve better performance when generalized to other models. Moreover, extensive experiments on citation networks and co-purchase datasets demonstrate the superiority of our model against the state-of-the-art methods.
DISCO: Influence Maximization Meets Network Embedding and Deep Learning
Jun 18, 2019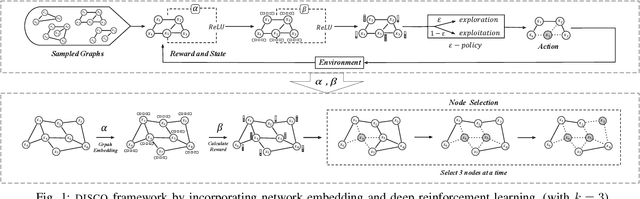
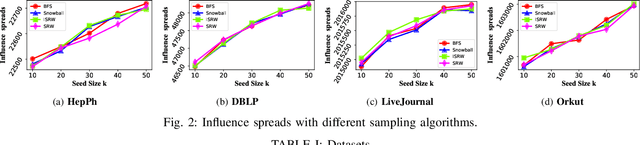
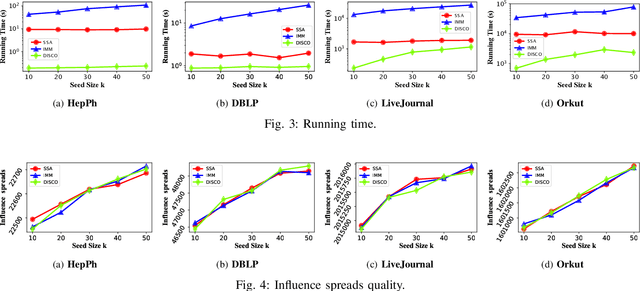
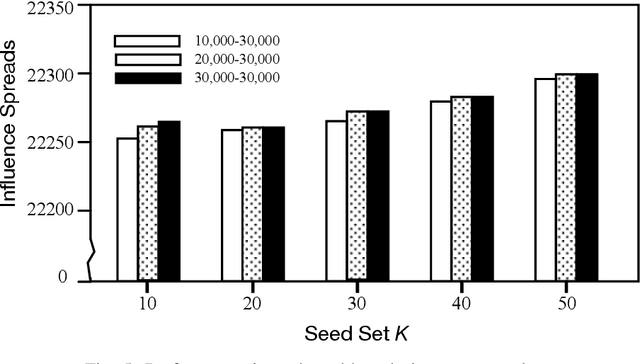
Since its introduction in 2003, the influence maximization (IM) problem has drawn significant research attention in the literature. The aim of IM is to select a set of k users who can influence the most individuals in the social network. The problem is proven to be NP-hard. A large number of approximate algorithms have been proposed to address this problem. The state-of-the-art algorithms estimate the expected influence of nodes based on sampled diffusion paths. As the number of required samples have been recently proven to be lower bounded by a particular threshold that presets tradeoff between the accuracy and efficiency, the result quality of these traditional solutions is hard to be further improved without sacrificing efficiency. In this paper, we present an orthogonal and novel paradigm to address the IM problem by leveraging deep learning models to estimate the expected influence. Specifically, we present a novel framework called DISCO that incorporates network embedding and deep reinforcement learning techniques to address this problem. Experimental study on real-world networks demonstrates that DISCO achieves the best performance w.r.t efficiency and influence spread quality compared to state-of-the-art classical solutions. Besides, we also show that the learning model exhibits good generality.