 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRcAE: Recursive Reconstruction Framework for Unsupervised Industrial Anomaly Detection
Dec 12, 2025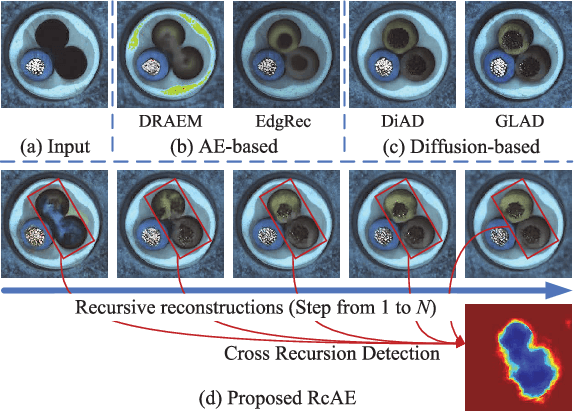
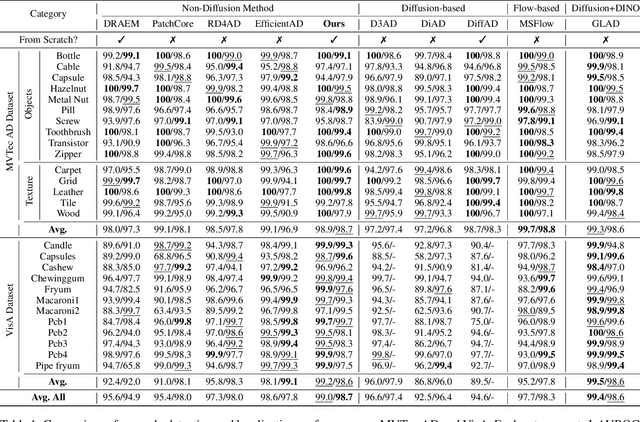
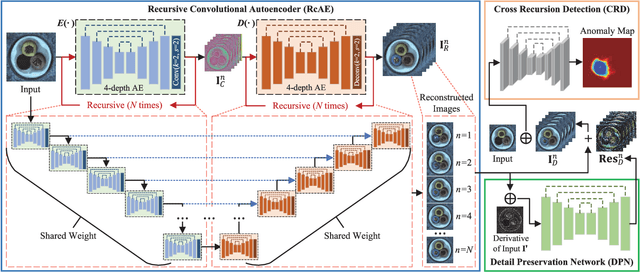
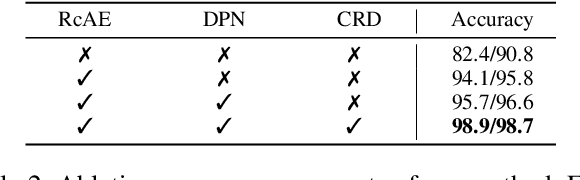
Unsupervised industrial anomaly detection requires accurately identifying defects without labeled data. Traditional autoencoder-based methods often struggle with incomplete anomaly suppression and loss of fine details, as their single-pass decoding fails to effectively handle anomalies with varying severity and scale. We propose a recursive architecture for autoencoder (RcAE), which performs reconstruction iteratively to progressively suppress anomalies while refining normal structures. Unlike traditional single-pass models, this recursive design naturally produces a sequence of reconstructions, progressively exposing suppressed abnormal patterns. To leverage this reconstruction dynamics, we introduce a Cross Recursion Detection (CRD) module that tracks inconsistencies across recursion steps, enhancing detection of both subtle and large-scale anomalies. Additionally, we incorporate a Detail Preservation Network (DPN) to recover high-frequency textures typically lost during reconstruction. Extensive experiments demonstrate that our method significantly outperforms existing non-diffusion methods, and achieves performance on par with recent diffusion models with only 10% of their parameters and offering substantially faster inference. These results highlight the practicality and efficiency of our approach for real-world applications.
Random Ensemble Reinforcement Learning for Traffic Signal Control
Mar 10, 2022
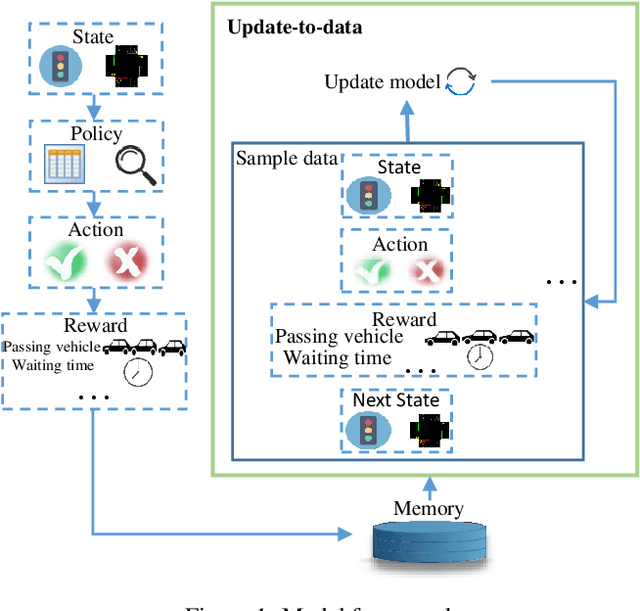
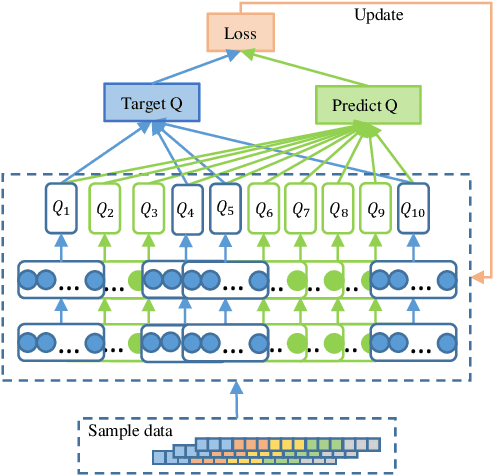
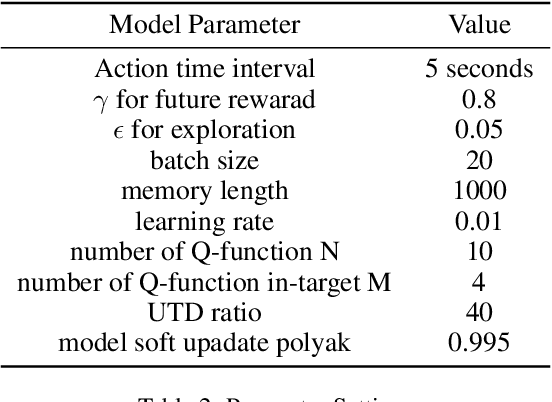
Traffic signal control is a significant part of the construction of intelligent transportation. An efficient traffic signal control strategy can reduce traffic congestion, improve urban road traffic efficiency and facilitate people's lives. Existing reinforcement learning approaches for traffic signal control mainly focus on learning through a separate neural network. Such an independent neural network may fall into the local optimum of the training results. Worse more, the collected data can only be sampled once, so the data utilization rate is low. Therefore, we propose the Random Ensemble Double DQN Light (RELight) model. It can dynamically learn traffic signal control strategies through reinforcement learning and combine random ensemble learning to avoid falling into the local optimum to reach the optimal strategy. Moreover, we introduce the Update-To-Data (UTD) ratio to control the number of data reuses to improve the problem of low data utilization. In addition, we have conducted sufficient experiments on synthetic data and real-world data to prove that our proposed method can achieve better traffic signal control effects than the existing optimal methods.
Defeating Catastrophic Forgetting via Enhanced Orthogonal Weights Modification
Nov 19, 2021
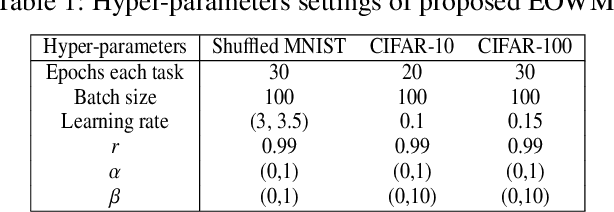
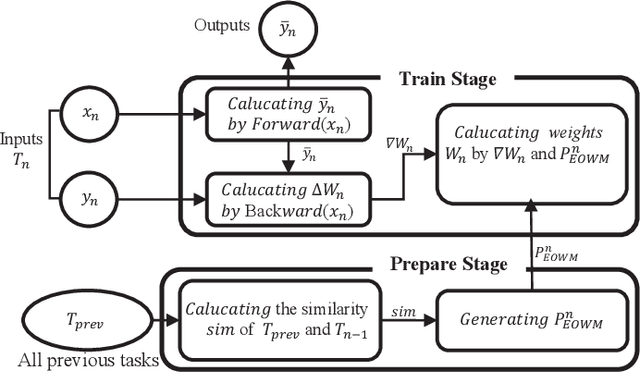
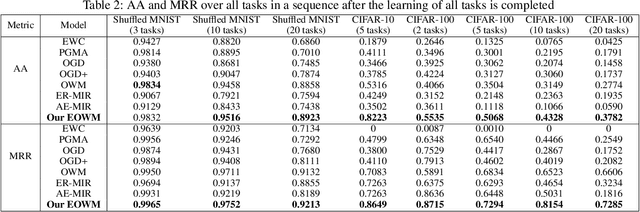
The ability of neural networks (NNs) to learn and remember multiple tasks sequentially is facing tough challenges in achieving general artificial intelligence due to their catastrophic forgetting (CF) issues. Fortunately, the latest OWM Orthogonal Weights Modification) and other several continual learning (CL) methods suggest some promising ways to overcome the CF issue. However, none of existing CL methods explores the following three crucial questions for effectively overcoming the CF issue: that is, what knowledge does it contribute to the effective weights modification of the NN during its sequential tasks learning? When the data distribution of a new learning task changes corresponding to the previous learned tasks, should a uniform/specific weight modification strategy be adopted or not? what is the upper bound of the learningable tasks sequentially for a given CL method? ect. To achieve this, in this paper, we first reveals the fact that of the weight gradient of a new learning task is determined by both the input space of the new task and the weight space of the previous learned tasks sequentially. On this observation and the recursive least square optimal method, we propose a new efficient and effective continual learning method EOWM via enhanced OWM. And we have theoretically and definitively given the upper bound of the learningable tasks sequentially of our EOWM. Extensive experiments conducted on the benchmarks demonstrate that our EOWM is effectiveness and outperform all of the state-of-the-art CL baselines.
Enhanced countering adversarial attacks via input denoising and feature restoring
Nov 19, 2021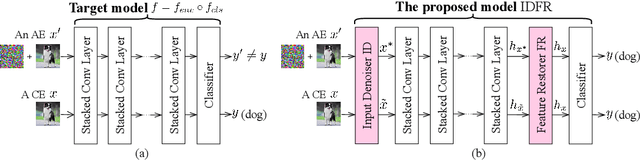
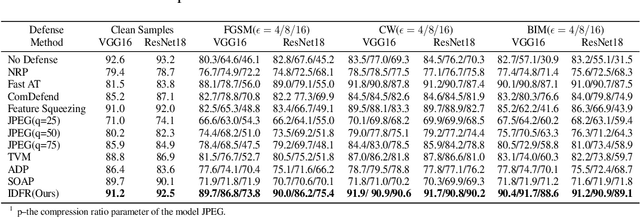
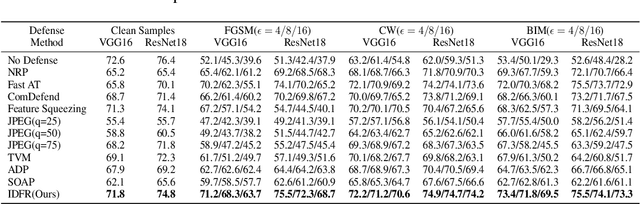
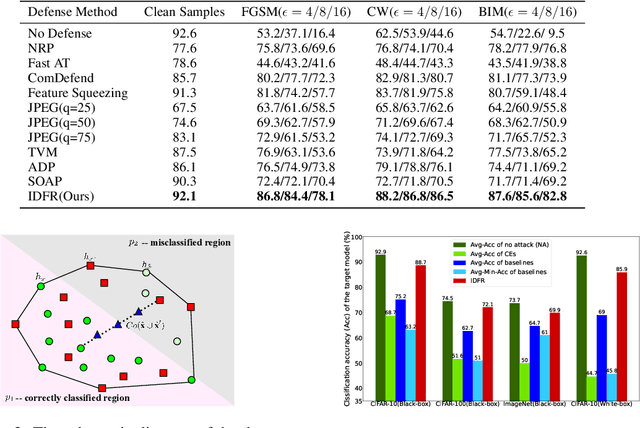
Despite the fact that deep neural networks (DNNs) have achieved prominent performance in various applications, it is well known that DNNs are vulnerable to adversarial examples/samples (AEs) with imperceptible perturbations in clean/original samples. To overcome the weakness of the existing defense methods against adversarial attacks, which damages the information on the original samples, leading to the decrease of the target classifier accuracy, this paper presents an enhanced countering adversarial attack method IDFR (via Input Denoising and Feature Restoring). The proposed IDFR is made up of an enhanced input denoiser (ID) and a hidden lossy feature restorer (FR) based on the convex hull optimization. Extensive experiments conducted on benchmark datasets show that the proposed IDFR outperforms the various state-of-the-art defense methods, and is highly effective for protecting target models against various adversarial black-box or white-box attacks. \footnote{Souce code is released at: \href{https://github.com/ID-FR/IDFR}{https://github.com/ID-FR/IDFR}}
Interpretable and Efficient Heterogeneous Graph Convolutional Network
Jun 23, 2020

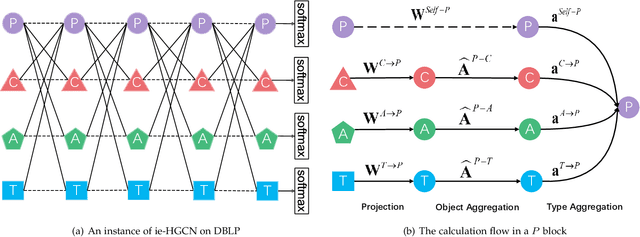

Graph Convolutional Network (GCN) has achieved extraordinary success in learning effective task-specific representations of nodes in graphs. However, regarding Heterogeneous Information Network (HIN), existing HIN-oriented GCN methods still suffer from two deficiencies: (1) they cannot flexibly explore all possible meta-paths and extract the most useful ones for a target object, which hinders both effectiveness and interpretability; (2) they often need to generate intermediate meta-path based dense graphs, which leads to high computational complexity. To address the above issues, we propose an interpretable and efficient Heterogeneous Graph Convolutional Network (ie-HGCN) to learn the representations of objects in HINs. It is designed as a hierarchical aggregation architecture, i.e., object-level aggregation first, followed by type-level aggregation. The novel architecture can automatically extract useful meta-paths for each object from all possible meta-paths (within a length limit), which brings good model interpretability. It can also reduce the computational cost by avoiding intermediate HIN transformation and neighborhood attention. We provide theoretical analysis about the proposed ie-HGCN in terms of evaluating the usefulness of all possible meta-paths, its connection to the spectral graph convolution on HINs, and its quasi-linear time complexity. Extensive experiments on three real network datasets demonstrate the superiority of ie-HGCN over the state-of-the-art methods.
DISCO: Influence Maximization Meets Network Embedding and Deep Learning
Jun 18, 2019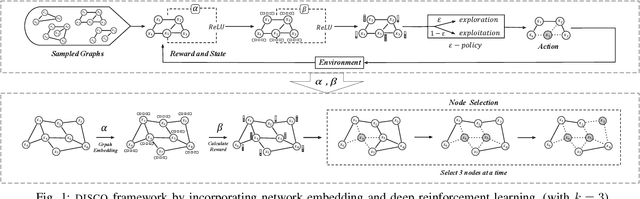
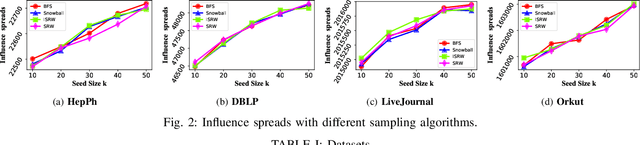
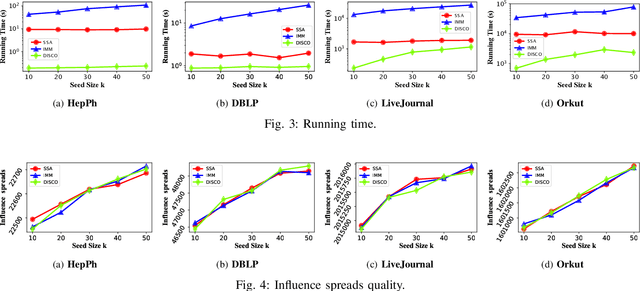
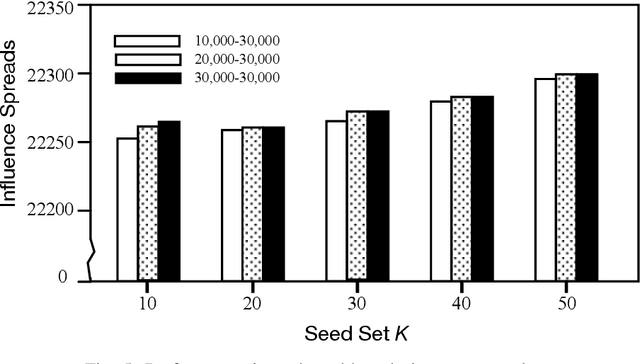
Since its introduction in 2003, the influence maximization (IM) problem has drawn significant research attention in the literature. The aim of IM is to select a set of k users who can influence the most individuals in the social network. The problem is proven to be NP-hard. A large number of approximate algorithms have been proposed to address this problem. The state-of-the-art algorithms estimate the expected influence of nodes based on sampled diffusion paths. As the number of required samples have been recently proven to be lower bounded by a particular threshold that presets tradeoff between the accuracy and efficiency, the result quality of these traditional solutions is hard to be further improved without sacrificing efficiency. In this paper, we present an orthogonal and novel paradigm to address the IM problem by leveraging deep learning models to estimate the expected influence. Specifically, we present a novel framework called DISCO that incorporates network embedding and deep reinforcement learning techniques to address this problem. Experimental study on real-world networks demonstrates that DISCO achieves the best performance w.r.t efficiency and influence spread quality compared to state-of-the-art classical solutions. Besides, we also show that the learning model exhibits good generality.