 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Coding Gain Due to In-Loop Reshaping
Dec 07, 2023Reshaping, a point operation that alters the characteristics of signals, has been shown capable of improving the compression ratio in video coding practices. Out-of-loop reshaping that directly modifies the input video signal was first adopted as the supplemental enhancement information~(SEI) for the HEVC/H.265 without the need of altering the core design of the video codec. VVC/H.266 further improves the coding efficiency by adopting in-loop reshaping that modifies the residual signal being processed in the hybrid coding loop. In this paper, we theoretically analyze the rate-distortion performance of the in-loop reshaping and use experiments to verify the theoretical result. We prove that the in-loop reshaping can improve coding efficiency when the entropy coder adopted in the coding pipeline is suboptimal, which is in line with the practical scenarios that video codecs operate in. We derive the PSNR gain in a closed form and show that the theoretically predicted gain is consistent with that measured from experiments using standard testing video sequences.
Complementary Labels Learning with Augmented Classes
Nov 19, 2022



Complementary Labels Learning (CLL) arises in many real-world tasks such as private questions classification and online learning, which aims to alleviate the annotation cost compared with standard supervised learning. Unfortunately, most previous CLL algorithms were in a stable environment rather than an open and dynamic scenarios, where data collected from unseen augmented classes in the training process might emerge in the testing phase. In this paper, we propose a novel problem setting called Complementary Labels Learning with Augmented Classes (CLLAC), which brings the challenge that classifiers trained by complementary labels should not only be able to classify the instances from observed classes accurately, but also recognize the instance from the Augmented Classes in the testing phase. Specifically, by using unlabeled data, we propose an unbiased estimator of classification risk for CLLAC, which is guaranteed to be provably consistent. Moreover, we provide generalization error bound for proposed method which shows that the optimal parametric convergence rate is achieved for estimation error. Finally, the experimental results on several benchmark datasets verify the effectiveness of the proposed method.
InfoAT: Improving Adversarial Training Using the Information Bottleneck Principle
Jun 23, 2022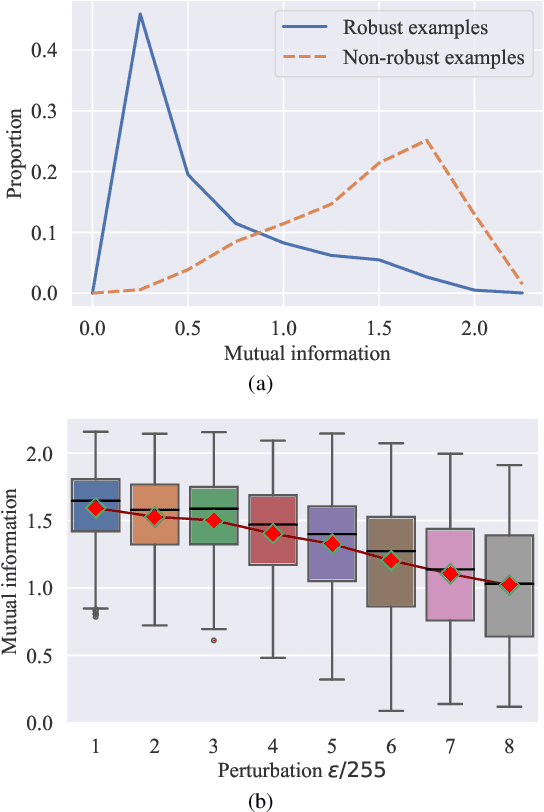
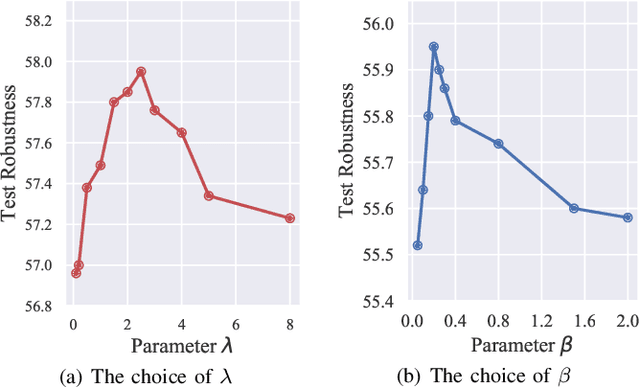
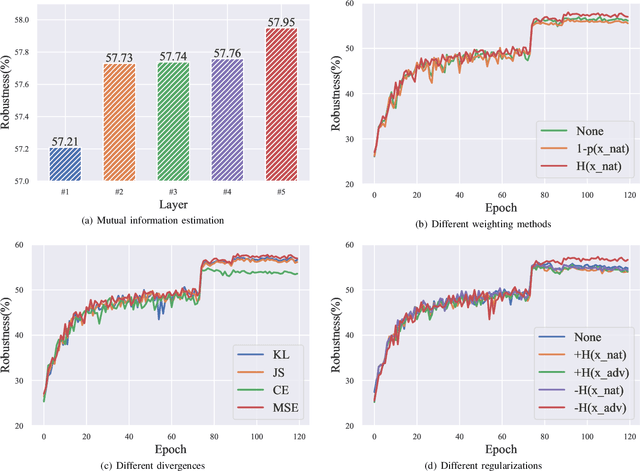
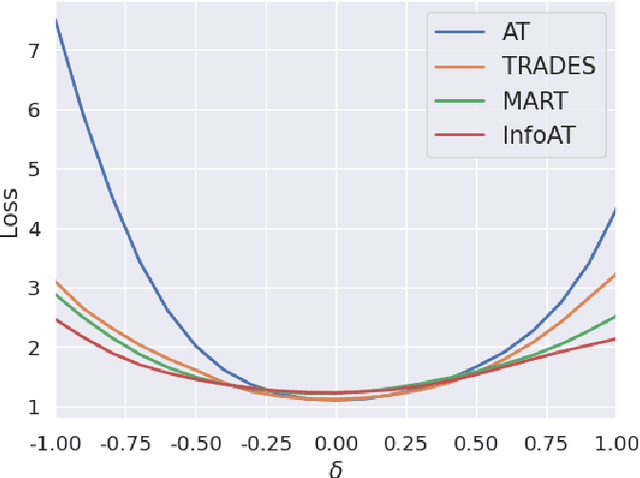
Adversarial training (AT) has shown excellent high performance in defending against adversarial examples. Recent studies demonstrate that examples are not equally important to the final robustness of models during AT, that is, the so-called hard examples that can be attacked easily exhibit more influence than robust examples on the final robustness. Therefore, guaranteeing the robustness of hard examples is crucial for improving the final robustness of the model. However, defining effective heuristics to search for hard examples is still difficult. In this article, inspired by the information bottleneck (IB) principle, we uncover that an example with high mutual information of the input and its associated latent representation is more likely to be attacked. Based on this observation, we propose a novel and effective adversarial training method (InfoAT). InfoAT is encouraged to find examples with high mutual information and exploit them efficiently to improve the final robustness of models. Experimental results show that InfoAT achieves the best robustness among different datasets and models in comparison with several state-of-the-art methods.
Scale-Invariant Adversarial Attack for Evaluating and Enhancing Adversarial Defenses
Jan 29, 2022Efficient and effective attacks are crucial for reliable evaluation of defenses, and also for developing robust models. Projected Gradient Descent (PGD) attack has been demonstrated to be one of the most successful adversarial attacks. However, the effect of the standard PGD attack can be easily weakened by rescaling the logits, while the original decision of every input will not be changed. To mitigate this issue, in this paper, we propose Scale-Invariant Adversarial Attack (SI-PGD), which utilizes the angle between the features in the penultimate layer and the weights in the softmax layer to guide the generation of adversaries. The cosine angle matrix is used to learn angularly discriminative representation and will not be changed with the rescaling of logits, thus making SI-PGD attack to be stable and effective. We evaluate our attack against multiple defenses and show improved performance when compared with existing attacks. Further, we propose Scale-Invariant (SI) adversarial defense mechanism based on the cosine angle matrix, which can be embedded into the popular adversarial defenses. The experimental results show the defense method with our SI mechanism achieves state-of-the-art performance among multi-step and single-step defenses.
MedRDF: A Robust and Retrain-Less Diagnostic Framework for Medical Pretrained Models Against Adversarial Attack
Nov 29, 2021
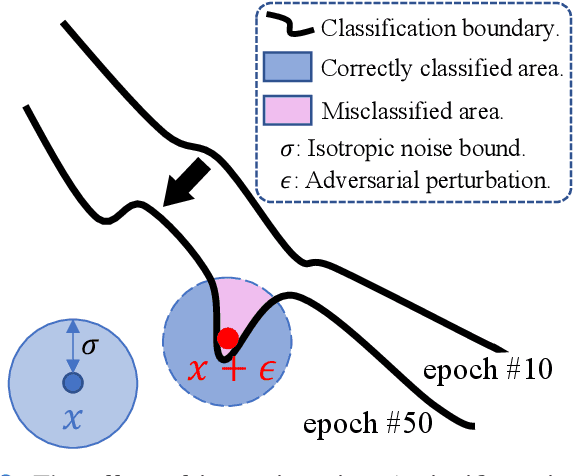

Deep neural networks are discovered to be non-robust when attacked by imperceptible adversarial examples, which is dangerous for it applied into medical diagnostic system that requires high reliability. However, the defense methods that have good effect in natural images may not be suitable for medical diagnostic tasks. The preprocessing methods (e.g., random resizing, compression) may lead to the loss of the small lesions feature in the medical image. Retraining the network on the augmented data set is also not practical for medical models that have already been deployed online. Accordingly, it is necessary to design an easy-to-deploy and effective defense framework for medical diagnostic tasks. In this paper, we propose a Robust and Retrain-Less Diagnostic Framework for Medical pretrained models against adversarial attack (i.e., MedRDF). It acts on the inference time of the pertained medical model. Specifically, for each test image, MedRDF firstly creates a large number of noisy copies of it, and obtains the output labels of these copies from the pretrained medical diagnostic model. Then, based on the labels of these copies, MedRDF outputs the final robust diagnostic result by majority voting. In addition to the diagnostic result, MedRDF produces the Robust Metric (RM) as the confidence of the result. Therefore, it is convenient and reliable to utilize MedRDF to convert pre-trained non-robust diagnostic models into robust ones. The experimental results on COVID-19 and DermaMNIST datasets verify the effectiveness of our MedRDF in improving the robustness of medical diagnostic models.
Towards Evaluating the Robustness of Deep Diagnostic Models by Adversarial Attack
Mar 05, 2021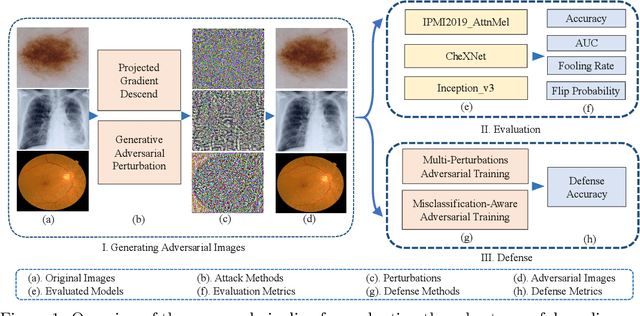
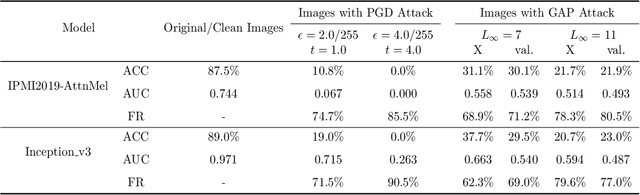

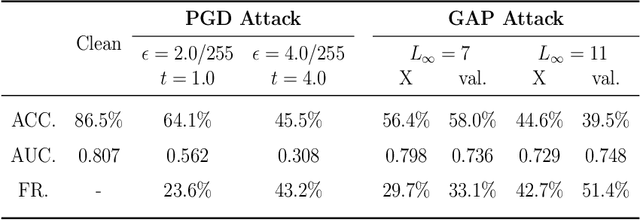
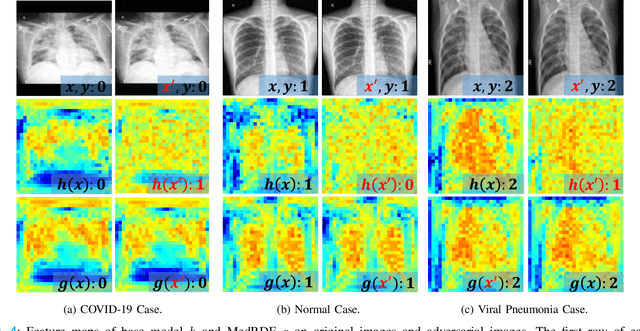
Deep learning models (with neural networks) have been widely used in challenging tasks such as computer-aided disease diagnosis based on medical images. Recent studies have shown deep diagnostic models may not be robust in the inference process and may pose severe security concerns in clinical practice. Among all the factors that make the model not robust, the most serious one is adversarial examples. The so-called "adversarial example" is a well-designed perturbation that is not easily perceived by humans but results in a false output of deep diagnostic models with high confidence. In this paper, we evaluate the robustness of deep diagnostic models by adversarial attack. Specifically, we have performed two types of adversarial attacks to three deep diagnostic models in both single-label and multi-label classification tasks, and found that these models are not reliable when attacked by adversarial example. We have further explored how adversarial examples attack the models, by analyzing their quantitative classification results, intermediate features, discriminability of features and correlation of estimated labels for both original/clean images and those adversarial ones. We have also designed two new defense methods to handle adversarial examples in deep diagnostic models, i.e., Multi-Perturbations Adversarial Training (MPAdvT) and Misclassification-Aware Adversarial Training (MAAdvT). The experimental results have shown that the use of defense methods can significantly improve the robustness of deep diagnostic models against adversarial attacks.
* This version was accepted in the journal Medical Image Analysis (MedIA)
Improving the Certified Robustness of Neural Networks via Consistency Regularization
Jan 20, 2021



A range of defense methods have been proposed to improve the robustness of neural networks on adversarial examples, among which provable defense methods have been demonstrated to be effective to train neural networks that are certifiably robust to the attacker. However, most of these provable defense methods treat all examples equally during training process, which ignore the inconsistent constraint of certified robustness between correctly classified (natural) and misclassified examples. In this paper, we explore this inconsistency caused by misclassified examples and add a novel consistency regularization term to make better use of the misclassified examples. Specifically, we identified that the certified robustness of network can be significantly improved if the constraint of certified robustness on misclassified examples and correctly classified examples is consistent. Motivated by this discovery, we design a new defense regularization term called Misclassification Aware Adversarial Regularization (MAAR), which constrains the output probability distributions of all examples in the certified region of the misclassified example. Experimental results show that our proposed MAAR achieves the best certified robustness and comparable accuracy on CIFAR-10 and MNIST datasets in comparison with several state-of-the-art methods.
DISCO: Influence Maximization Meets Network Embedding and Deep Learning
Jun 18, 2019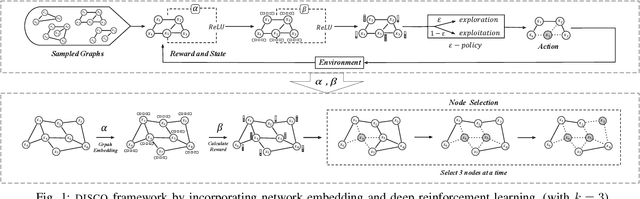
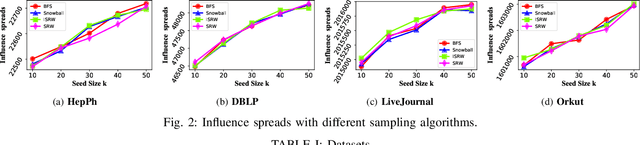
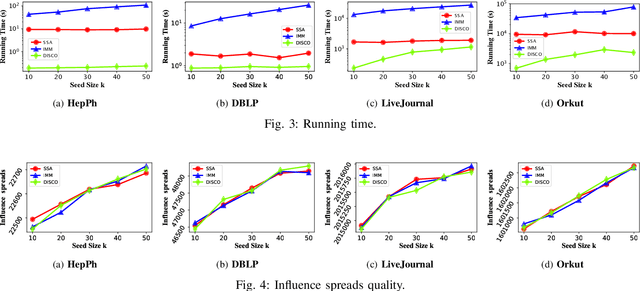
Since its introduction in 2003, the influence maximization (IM) problem has drawn significant research attention in the literature. The aim of IM is to select a set of k users who can influence the most individuals in the social network. The problem is proven to be NP-hard. A large number of approximate algorithms have been proposed to address this problem. The state-of-the-art algorithms estimate the expected influence of nodes based on sampled diffusion paths. As the number of required samples have been recently proven to be lower bounded by a particular threshold that presets tradeoff between the accuracy and efficiency, the result quality of these traditional solutions is hard to be further improved without sacrificing efficiency. In this paper, we present an orthogonal and novel paradigm to address the IM problem by leveraging deep learning models to estimate the expected influence. Specifically, we present a novel framework called DISCO that incorporates network embedding and deep reinforcement learning techniques to address this problem. Experimental study on real-world networks demonstrates that DISCO achieves the best performance w.r.t efficiency and influence spread quality compared to state-of-the-art classical solutions. Besides, we also show that the learning model exhibits good generality.