 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamMimic: Zero-Shot Image To Camera Motion Personalized Video Generation Using Diffusion Models
Apr 13, 2025We introduce CamMimic, an innovative algorithm tailored for dynamic video editing needs. It is designed to seamlessly transfer the camera motion observed in a given reference video onto any scene of the user's choice in a zero-shot manner without requiring any additional data. Our algorithm achieves this using a two-phase strategy by leveraging a text-to-video diffusion model. In the first phase, we develop a multi-concept learning method using a combination of LoRA layers and an orthogonality loss to capture and understand the underlying spatial-temporal characteristics of the reference video as well as the spatial features of the user's desired scene. The second phase proposes a unique homography-based refinement strategy to enhance the temporal and spatial alignment of the generated video. We demonstrate the efficacy of our method through experiments conducted on a dataset containing combinations of diverse scenes and reference videos containing a variety of camera motions. In the absence of an established metric for assessing camera motion transfer between unrelated scenes, we propose CameraScore, a novel metric that utilizes homography representations to measure camera motion similarity between the reference and generated videos. Extensive quantitative and qualitative evaluations demonstrate that our approach generates high-quality, motion-enhanced videos. Additionally, a user study reveals that 70.31% of participants preferred our method for scene preservation, while 90.45% favored it for motion transfer. We hope this work lays the foundation for future advancements in camera motion transfer across different scenes.
Parametric Shadow Control for Portrait Generationin Text-to-Image Diffusion Models
Mar 27, 2025Text-to-image diffusion models excel at generating diverse portraits, but lack intuitive shadow control. Existing editing approaches, as post-processing, struggle to offer effective manipulation across diverse styles. Additionally, these methods either rely on expensive real-world light-stage data collection or require extensive computational resources for training. To address these limitations, we introduce Shadow Director, a method that extracts and manipulates hidden shadow attributes within well-trained diffusion models. Our approach uses a small estimation network that requires only a few thousand synthetic images and hours of training-no costly real-world light-stage data needed. Shadow Director enables parametric and intuitive control over shadow shape, placement, and intensity during portrait generation while preserving artistic integrity and identity across diverse styles. Despite training only on synthetic data built on real-world identities, it generalizes effectively to generated portraits with diverse styles, making it a more accessible and resource-friendly solution.
V-Trans4Style: Visual Transition Recommendation for Video Production Style Adaptation
Jan 14, 2025We introduce V-Trans4Style, an innovative algorithm tailored for dynamic video content editing needs. It is designed to adapt videos to different production styles like documentaries, dramas, feature films, or a specific YouTube channel's video-making technique. Our algorithm recommends optimal visual transitions to help achieve this flexibility using a more bottom-up approach. We first employ a transformer-based encoder-decoder network to learn recommending temporally consistent and visually seamless sequences of visual transitions using only the input videos. We then introduce a style conditioning module that leverages this model to iteratively adjust the visual transitions obtained from the decoder through activation maximization. We demonstrate the efficacy of our method through experiments conducted on our newly introduced AutoTransition++ dataset. It is a 6k video version of AutoTransition Dataset that additionally categorizes its videos into different production style categories. Our encoder-decoder model outperforms the state-of-the-art transition recommendation method, achieving improvements of 10% to 80% in Recall@K and mean rank values over baseline. Our style conditioning module results in visual transitions that improve the capture of the desired video production style characteristics by an average of around 12% in comparison to other methods when measured with similarity metrics. We hope that our work serves as a foundation for exploring and understanding video production styles further.
Standardizing Generative Face Video Compression using Supplemental Enhancement Information
Oct 19, 2024This paper proposes a Generative Face Video Compression (GFVC) approach using Supplemental Enhancement Information (SEI), where a series of compact spatial and temporal representations of a face video signal (i.e., 2D/3D key-points, facial semantics and compact features) can be coded using SEI message and inserted into the coded video bitstream. At the time of writing, the proposed GFVC approach is an official "technology under consideration" (TuC) for standardization by the Joint Video Experts Team (JVET) of ISO/IEC JVT 1/SC 29 and ITU-T SG16. To the best of the authors' knowledge, the JVET work on the proposed SEI-based GFVC approach is the first standardization activity for generative video compression. The proposed SEI approach has not only advanced the reconstruction quality of early-day Model-Based Coding (MBC) via the state-of-the-art generative technique, but also established a new SEI definition for future GFVC applications and deployment. Experimental results illustrate that the proposed SEI-based GFVC approach can achieve remarkable rate-distortion performance compared with the latest Versatile Video Coding (VVC) standard, whilst also potentially enabling a wide variety of functionalities including user-specified animation/filtering and metaverse-related applications.
Analysis of Coding Gain Due to In-Loop Reshaping
Dec 07, 2023Reshaping, a point operation that alters the characteristics of signals, has been shown capable of improving the compression ratio in video coding practices. Out-of-loop reshaping that directly modifies the input video signal was first adopted as the supplemental enhancement information~(SEI) for the HEVC/H.265 without the need of altering the core design of the video codec. VVC/H.266 further improves the coding efficiency by adopting in-loop reshaping that modifies the residual signal being processed in the hybrid coding loop. In this paper, we theoretically analyze the rate-distortion performance of the in-loop reshaping and use experiments to verify the theoretical result. We prove that the in-loop reshaping can improve coding efficiency when the entropy coder adopted in the coding pipeline is suboptimal, which is in line with the practical scenarios that video codecs operate in. We derive the PSNR gain in a closed form and show that the theoretically predicted gain is consistent with that measured from experiments using standard testing video sequences.
Adaptive Dithering Using Curved Markov-Gaussian Noise in the Quantized Domain for Mapping SDR to HDR Image
Jan 20, 2020
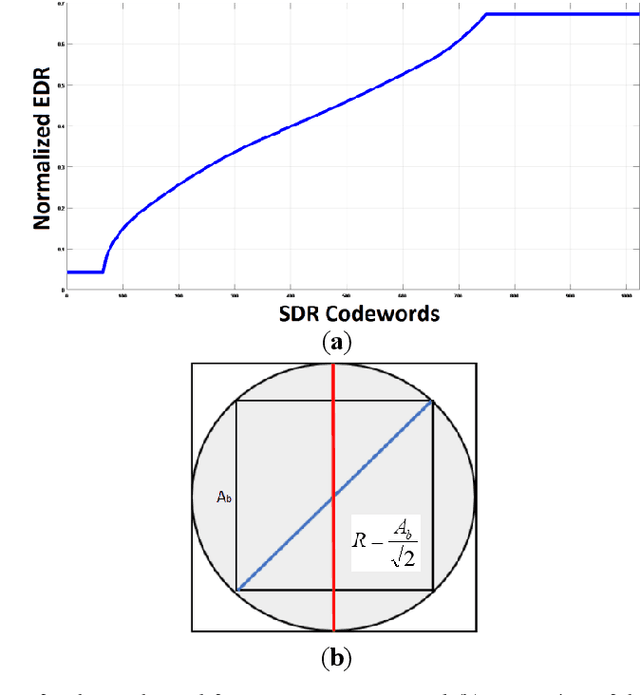

High Dynamic Range (HDR) imaging is gaining increased attention due to its realistic content, for not only regular displays but also smartphones. Before sufficient HDR content is distributed, HDR visualization still relies mostly on converting Standard Dynamic Range (SDR) content. SDR images are often quantized, or bit depth reduced, before SDR-to-HDR conversion, e.g. for video transmission. Quantization can easily lead to banding artefacts. In some computing and/or memory I/O limited environment, the traditional solution using spatial neighborhood information is not feasible. Our method includes noise generation (offline) and noise injection (online), and operates on pixels of the quantized image. We vary the magnitude and structure of the noise pattern adaptively based on the luma of the quantized pixel and the slope of the inverse-tone mapping function. Subjective user evaluations confirm the superior performance of our technique.