 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamMimic: Zero-Shot Image To Camera Motion Personalized Video Generation Using Diffusion Models
Apr 13, 2025We introduce CamMimic, an innovative algorithm tailored for dynamic video editing needs. It is designed to seamlessly transfer the camera motion observed in a given reference video onto any scene of the user's choice in a zero-shot manner without requiring any additional data. Our algorithm achieves this using a two-phase strategy by leveraging a text-to-video diffusion model. In the first phase, we develop a multi-concept learning method using a combination of LoRA layers and an orthogonality loss to capture and understand the underlying spatial-temporal characteristics of the reference video as well as the spatial features of the user's desired scene. The second phase proposes a unique homography-based refinement strategy to enhance the temporal and spatial alignment of the generated video. We demonstrate the efficacy of our method through experiments conducted on a dataset containing combinations of diverse scenes and reference videos containing a variety of camera motions. In the absence of an established metric for assessing camera motion transfer between unrelated scenes, we propose CameraScore, a novel metric that utilizes homography representations to measure camera motion similarity between the reference and generated videos. Extensive quantitative and qualitative evaluations demonstrate that our approach generates high-quality, motion-enhanced videos. Additionally, a user study reveals that 70.31% of participants preferred our method for scene preservation, while 90.45% favored it for motion transfer. We hope this work lays the foundation for future advancements in camera motion transfer across different scenes.
V-Trans4Style: Visual Transition Recommendation for Video Production Style Adaptation
Jan 14, 2025We introduce V-Trans4Style, an innovative algorithm tailored for dynamic video content editing needs. It is designed to adapt videos to different production styles like documentaries, dramas, feature films, or a specific YouTube channel's video-making technique. Our algorithm recommends optimal visual transitions to help achieve this flexibility using a more bottom-up approach. We first employ a transformer-based encoder-decoder network to learn recommending temporally consistent and visually seamless sequences of visual transitions using only the input videos. We then introduce a style conditioning module that leverages this model to iteratively adjust the visual transitions obtained from the decoder through activation maximization. We demonstrate the efficacy of our method through experiments conducted on our newly introduced AutoTransition++ dataset. It is a 6k video version of AutoTransition Dataset that additionally categorizes its videos into different production style categories. Our encoder-decoder model outperforms the state-of-the-art transition recommendation method, achieving improvements of 10% to 80% in Recall@K and mean rank values over baseline. Our style conditioning module results in visual transitions that improve the capture of the desired video production style characteristics by an average of around 12% in comparison to other methods when measured with similarity metrics. We hope that our work serves as a foundation for exploring and understanding video production styles further.
ABC-Net: Semi-Supervised Multimodal GAN-based Engagement Detection using an Affective, Behavioral and Cognitive Model
Nov 17, 2020
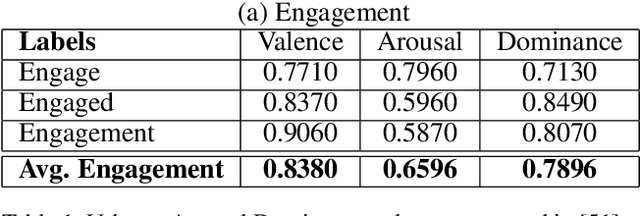
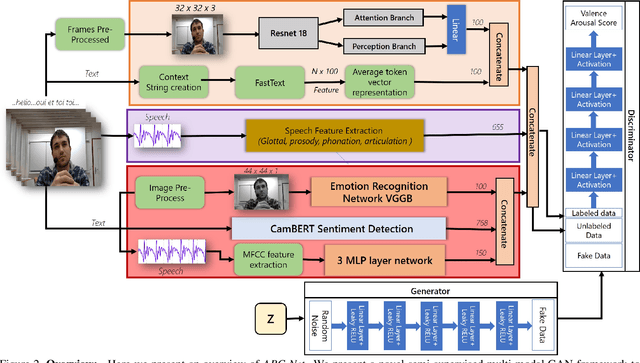
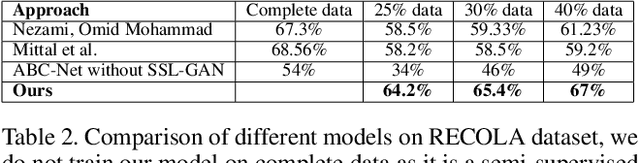
We present ABC-Net, a novel semi-supervised multimodal GAN framework to detect engagement levels in video conversations based on psychology literature. We use three constructs: behavioral, cognitive, and affective engagement, to extract various features that can effectively capture engagement levels. We feed these features to our semi-supervised GAN network that does regression using these latent representations to obtain the corresponding valence and arousal values, which are then categorized into different levels of engagements. We demonstrate the efficiency of our network through experiments on the RECOLA database. To evaluate our method, we analyze and compare our performance on RECOLA and report a relative performance improvement of more than 5% over the baseline methods. To the best of our knowledge, our approach is the first method to classify engagement based on a multimodal semi-supervised network.
EmotiCon: Context-Aware Multimodal Emotion Recognition using Frege's Principle
Mar 14, 2020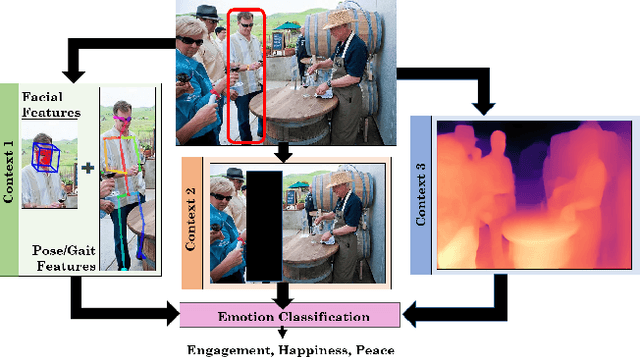
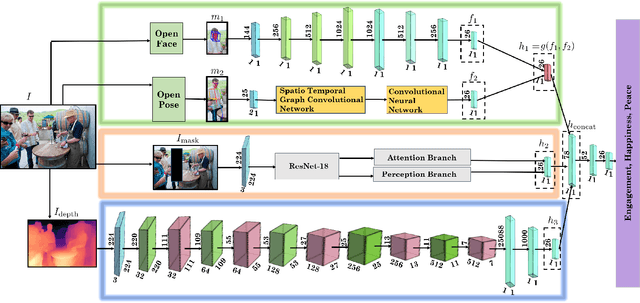
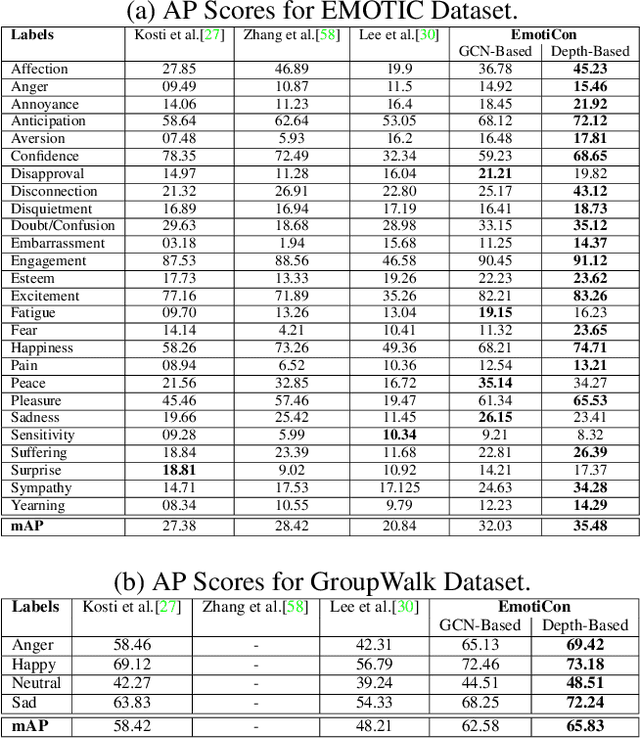
We present EmotiCon, a learning-based algorithm for context-aware perceived human emotion recognition from videos and images. Motivated by Frege's Context Principle from psychology, our approach combines three interpretations of context for emotion recognition. Our first interpretation is based on using multiple modalities(e.g. faces and gaits) for emotion recognition. For the second interpretation, we gather semantic context from the input image and use a self-attention-based CNN to encode this information. Finally, we use depth maps to model the third interpretation related to socio-dynamic interactions and proximity among agents. We demonstrate the efficiency of our network through experiments on EMOTIC, a benchmark dataset. We report an Average Precision (AP) score of 35.48 across 26 classes, which is an improvement of 7-8 over prior methods. We also introduce a new dataset, GroupWalk, which is a collection of videos captured in multiple real-world settings of people walking. We report an AP of 65.83 across 4 categories on GroupWalk, which is also an improvement over prior methods.
Learning Coordinated Tasks using Reinforcement Learning in Humanoids
May 09, 2018
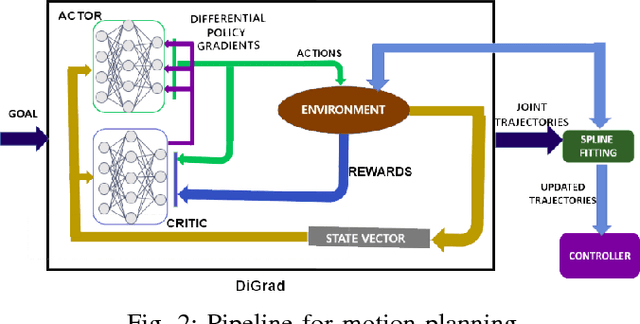

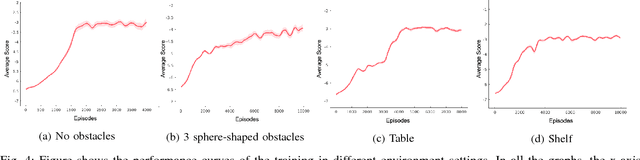
With the advent of artificial intelligence and machine learning, humanoid robots are made to learn a variety of skills which humans possess. One of fundamental skills which humans use in day-to-day activities is performing tasks with coordination between both the hands. In case of humanoids, learning such skills require optimal motion planning which includes avoiding collisions with the surroundings. In this paper, we propose a framework to learn coordinated tasks in cluttered environments based on DiGrad - A multi-task reinforcement learning algorithm for continuous action-spaces. Further, we propose an algorithm to smooth the joint space trajectories obtained by the proposed framework in order to reduce the noise instilled during training. The proposed framework was tested on a 27 degrees of freedom (DoF) humanoid with articulated torso for performing coordinated object-reaching task with both the hands in four different environments with varying levels of difficulty. It is observed that the humanoid is able to plan collision free trajectory in real-time. Simulation results also reveal the usefulness of the articulated torso for performing tasks which require coordination between both the arms.
A Deep Reinforcement Learning Approach for Dynamically Stable Inverse Kinematics of Humanoid Robots
Jan 31, 2018
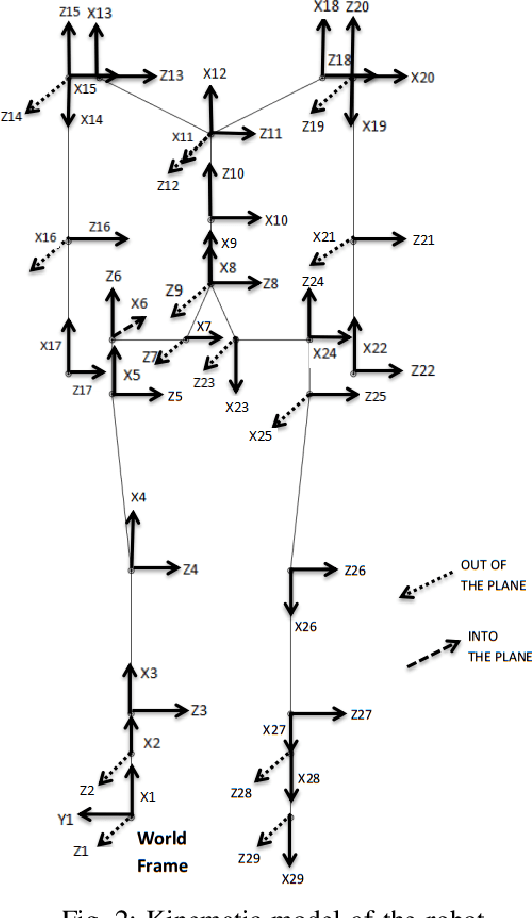


Real time calculation of inverse kinematics (IK) with dynamically stable configuration is of high necessity in humanoid robots as they are highly susceptible to lose balance. This paper proposes a methodology to generate joint-space trajectories of stable configurations for solving inverse kinematics using Deep Reinforcement Learning (RL). Our approach is based on the idea of exploring the entire configuration space of the robot and learning the best possible solutions using Deep Deterministic Policy Gradient (DDPG). The proposed strategy was evaluated on the highly articulated upper body of a humanoid model with 27 degree of freedom (DoF). The trained model was able to solve inverse kinematics for the end effectors with 90% accuracy while maintaining the balance in double support phase.