 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotiCon: Context-Aware Multimodal Emotion Recognition using Frege's Principle
Paper and Code
Mar 14, 2020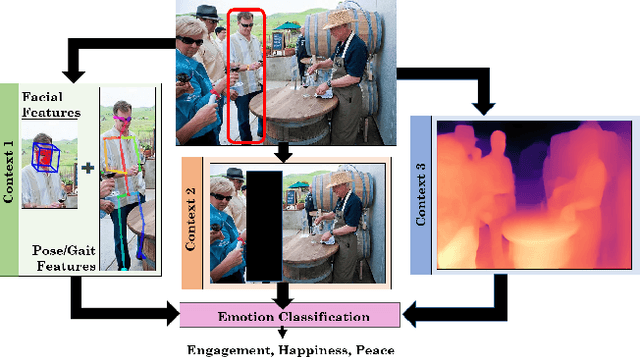
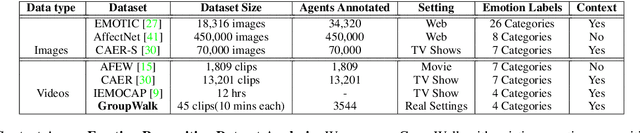
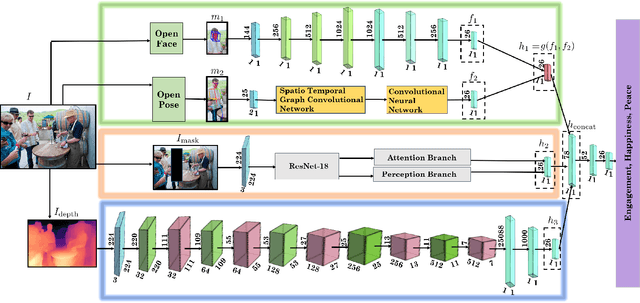
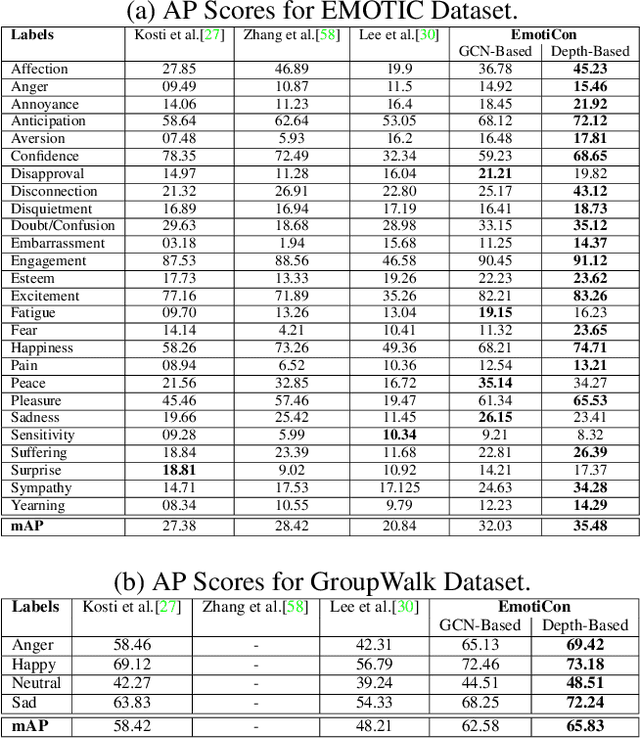
We present EmotiCon, a learning-based algorithm for context-aware perceived human emotion recognition from videos and images. Motivated by Frege's Context Principle from psychology, our approach combines three interpretations of context for emotion recognition. Our first interpretation is based on using multiple modalities(e.g. faces and gaits) for emotion recognition. For the second interpretation, we gather semantic context from the input image and use a self-attention-based CNN to encode this information. Finally, we use depth maps to model the third interpretation related to socio-dynamic interactions and proximity among agents. We demonstrate the efficiency of our network through experiments on EMOTIC, a benchmark dataset. We report an Average Precision (AP) score of 35.48 across 26 classes, which is an improvement of 7-8 over prior methods. We also introduce a new dataset, GroupWalk, which is a collection of videos captured in multiple real-world settings of people walking. We report an AP of 65.83 across 4 categories on GroupWalk, which is also an improvement over prior methods.