 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Coordinated Tasks using Reinforcement Learning in Humanoids
May 09, 2018

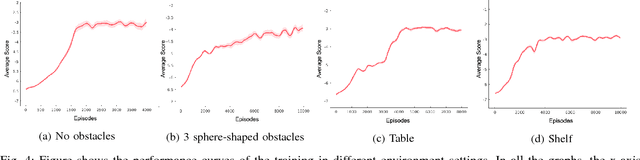
With the advent of artificial intelligence and machine learning, humanoid robots are made to learn a variety of skills which humans possess. One of fundamental skills which humans use in day-to-day activities is performing tasks with coordination between both the hands. In case of humanoids, learning such skills require optimal motion planning which includes avoiding collisions with the surroundings. In this paper, we propose a framework to learn coordinated tasks in cluttered environments based on DiGrad - A multi-task reinforcement learning algorithm for continuous action-spaces. Further, we propose an algorithm to smooth the joint space trajectories obtained by the proposed framework in order to reduce the noise instilled during training. The proposed framework was tested on a 27 degrees of freedom (DoF) humanoid with articulated torso for performing coordinated object-reaching task with both the hands in four different environments with varying levels of difficulty. It is observed that the humanoid is able to plan collision free trajectory in real-time. Simulation results also reveal the usefulness of the articulated torso for performing tasks which require coordination between both the arms.
DiGrad: Multi-Task Reinforcement Learning with Shared Actions
Feb 27, 2018

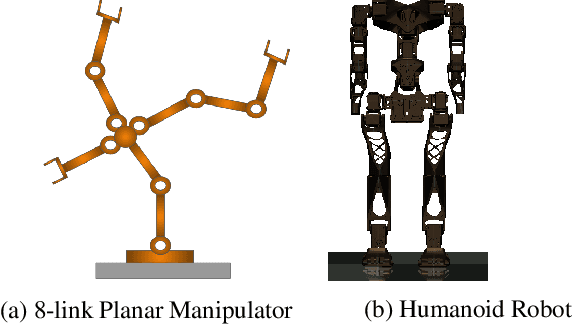
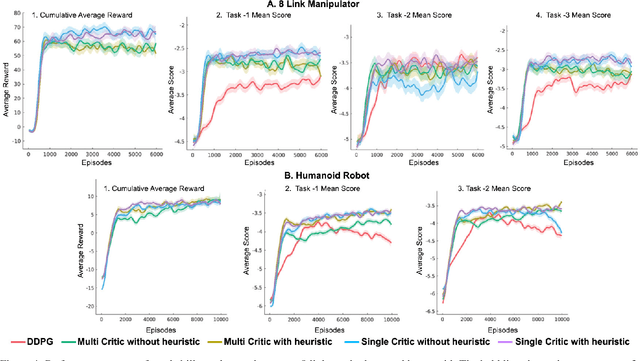
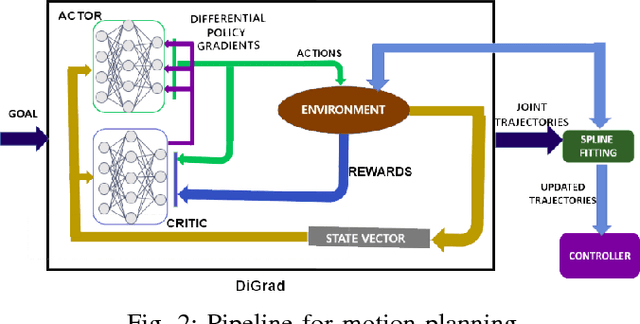
Most reinforcement learning algorithms are inefficient for learning multiple tasks in complex robotic systems, where different tasks share a set of actions. In such environments a compound policy may be learnt with shared neural network parameters, which performs multiple tasks concurrently. However such compound policy may get biased towards a task or the gradients from different tasks negate each other, making the learning unstable and sometimes less data efficient. In this paper, we propose a new approach for simultaneous training of multiple tasks sharing a set of common actions in continuous action spaces, which we call as DiGrad (Differential Policy Gradient). The proposed framework is based on differential policy gradients and can accommodate multi-task learning in a single actor-critic network. We also propose a simple heuristic in the differential policy gradient update to further improve the learning. The proposed architecture was tested on 8 link planar manipulator and 27 degrees of freedom(DoF) Humanoid for learning multi-goal reachability tasks for 3 and 2 end effectors respectively. We show that our approach supports efficient multi-task learning in complex robotic systems, outperforming related methods in continuous action spaces.
A Deep Reinforcement Learning Approach for Dynamically Stable Inverse Kinematics of Humanoid Robots
Jan 31, 2018
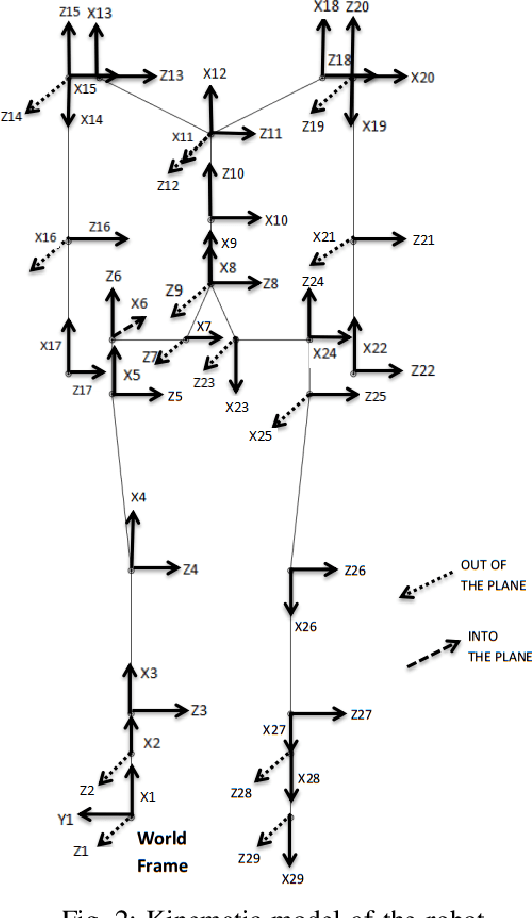


Real time calculation of inverse kinematics (IK) with dynamically stable configuration is of high necessity in humanoid robots as they are highly susceptible to lose balance. This paper proposes a methodology to generate joint-space trajectories of stable configurations for solving inverse kinematics using Deep Reinforcement Learning (RL). Our approach is based on the idea of exploring the entire configuration space of the robot and learning the best possible solutions using Deep Deterministic Policy Gradient (DDPG). The proposed strategy was evaluated on the highly articulated upper body of a humanoid model with 27 degree of freedom (DoF). The trained model was able to solve inverse kinematics for the end effectors with 90% accuracy while maintaining the balance in double support phase.