 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speech Recognition with Decoder-Only Large Language Models and Latency Optimization
Jan 30, 2026Recent advances have demonstrated the potential of decoderonly large language models (LLMs) for automatic speech recognition (ASR). However, enabling streaming recognition within this framework remains a challenge. In this work, we propose a novel streaming ASR approach that integrates a read/write policy network with monotonic chunkwise attention (MoChA) to dynamically segment speech embeddings. These segments are interleaved with label sequences during training, enabling seamless integration with the LLM. During inference, the audio stream is buffered until the MoChA module triggers a read signal, at which point the buffered segment together with the previous token is fed into the LLM for the next token prediction. We also introduce a minimal-latency training objective to guide the policy network toward accurate segmentation boundaries. Furthermore, we adopt a joint training strategy in which a non-streaming LLM-ASR model and our streaming model share parameters. Experiments on the AISHELL-1 and AISHELL-2 Mandarin benchmarks demonstrate that our method consistently outperforms recent streaming ASR baselines, achieving character error rates of 5.1% and 5.5%, respectively. The latency optimization results in a 62.5% reduction in average token generation delay with negligible impact on recognition accuracy
Selective KV-Cache Sharing to Mitigate Timing Side-Channels in LLM Inference
Aug 11, 2025Global KV-cache sharing has emerged as a key optimization for accelerating large language model (LLM) inference. However, it exposes a new class of timing side-channel attacks, enabling adversaries to infer sensitive user inputs via shared cache entries. Existing defenses, such as per-user isolation, eliminate leakage but degrade performance by up to 38.9% in time-to-first-token (TTFT), making them impractical for high-throughput deployment. To address this gap, we introduce SafeKV (Secure and Flexible KV Cache Sharing), a privacy-aware KV-cache management framework that selectively shares non-sensitive entries while confining sensitive content to private caches. SafeKV comprises three components: (i) a hybrid, multi-tier detection pipeline that integrates rule-based pattern matching, a general-purpose privacy detector, and context-aware validation; (ii) a unified radix-tree index that manages public and private entries across heterogeneous memory tiers (HBM, DRAM, SSD); and (iii) entropy-based access monitoring to detect and mitigate residual information leakage. Our evaluation shows that SafeKV mitigates 94% - 97% of timing-based side-channel attacks. Compared to per-user isolation method, SafeKV improves TTFT by up to 40.58% and throughput by up to 2.66X across diverse LLMs and workloads. SafeKV reduces cache-induced TTFT overhead from 50.41% to 11.74% on Qwen3-235B. By combining fine-grained privacy control with high cache reuse efficiency, SafeKV reclaims the performance advantages of global sharing while providing robust runtime privacy guarantees for LLM inference.
Can Small Language Models Reliably Resist Jailbreak Attacks? A Comprehensive Evaluation
Mar 09, 2025



Small language models (SLMs) have emerged as promising alternatives to large language models (LLMs) due to their low computational demands, enhanced privacy guarantees and comparable performance in specific domains through light-weight fine-tuning. Deploying SLMs on edge devices, such as smartphones and smart vehicles, has become a growing trend. However, the security implications of SLMs have received less attention than LLMs, particularly regarding jailbreak attacks, which is recognized as one of the top threats of LLMs by the OWASP. In this paper, we conduct the first large-scale empirical study of SLMs' vulnerabilities to jailbreak attacks. Through systematically evaluation on 63 SLMs from 15 mainstream SLM families against 8 state-of-the-art jailbreak methods, we demonstrate that 47.6% of evaluated SLMs show high susceptibility to jailbreak attacks (ASR > 40%) and 38.1% of them can not even resist direct harmful query (ASR > 50%). We further analyze the reasons behind the vulnerabilities and identify four key factors: model size, model architecture, training datasets and training techniques. Moreover, we assess the effectiveness of three prompt-level defense methods and find that none of them achieve perfect performance, with detection accuracy varying across different SLMs and attack methods. Notably, we point out that the inherent security awareness play a critical role in SLM security, and models with strong security awareness could timely terminate unsafe response with little reminder. Building upon the findings, we highlight the urgent need for security-by-design approaches in SLM development and provide valuable insights for building more trustworthy SLM ecosystem.
RedAgent: Red Teaming Large Language Models with Context-aware Autonomous Language Agent
Jul 23, 2024



Recently, advanced Large Language Models (LLMs) such as GPT-4 have been integrated into many real-world applications like Code Copilot. These applications have significantly expanded the attack surface of LLMs, exposing them to a variety of threats. Among them, jailbreak attacks that induce toxic responses through jailbreak prompts have raised critical safety concerns. To identify these threats, a growing number of red teaming approaches simulate potential adversarial scenarios by crafting jailbreak prompts to test the target LLM. However, existing red teaming methods do not consider the unique vulnerabilities of LLM in different scenarios, making it difficult to adjust the jailbreak prompts to find context-specific vulnerabilities. Meanwhile, these methods are limited to refining jailbreak templates using a few mutation operations, lacking the automation and scalability to adapt to different scenarios. To enable context-aware and efficient red teaming, we abstract and model existing attacks into a coherent concept called "jailbreak strategy" and propose a multi-agent LLM system named RedAgent that leverages these strategies to generate context-aware jailbreak prompts. By self-reflecting on contextual feedback in an additional memory buffer, RedAgent continuously learns how to leverage these strategies to achieve effective jailbreaks in specific contexts. Extensive experiments demonstrate that our system can jailbreak most black-box LLMs in just five queries, improving the efficiency of existing red teaming methods by two times. Additionally, RedAgent can jailbreak customized LLM applications more efficiently. By generating context-aware jailbreak prompts towards applications on GPTs, we discover 60 severe vulnerabilities of these real-world applications with only two queries per vulnerability. We have reported all found issues and communicated with OpenAI and Meta for bug fixes.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Evaluation of General Large Language Models in Contextually Assessing Semantic Concepts Extracted from Adult Critical Care Electronic Health Record Notes
Jan 24, 2024The field of healthcare has increasingly turned its focus towards Large Language Models (LLMs) due to their remarkable performance. However, their performance in actual clinical applications has been underexplored. Traditional evaluations based on question-answering tasks don't fully capture the nuanced contexts. This gap highlights the need for more in-depth and practical assessments of LLMs in real-world healthcare settings. Objective: We sought to evaluate the performance of LLMs in the complex clinical context of adult critical care medicine using systematic and comprehensible analytic methods, including clinician annotation and adjudication. Methods: We investigated the performance of three general LLMs in understanding and processing real-world clinical notes. Concepts from 150 clinical notes were identified by MetaMap and then labeled by 9 clinicians. Each LLM's proficiency was evaluated by identifying the temporality and negation of these concepts using different prompts for an in-depth analysis. Results: GPT-4 showed overall superior performance compared to other LLMs. In contrast, both GPT-3.5 and text-davinci-003 exhibit enhanced performance when the appropriate prompting strategies are employed. The GPT family models have demonstrated considerable efficiency, evidenced by their cost-effectiveness and time-saving capabilities. Conclusion: A comprehensive qualitative performance evaluation framework for LLMs is developed and operationalized. This framework goes beyond singular performance aspects. With expert annotations, this methodology not only validates LLMs' capabilities in processing complex medical data but also establishes a benchmark for future LLM evaluations across specialized domains.
Self-guided Few-shot Semantic Segmentation for Remote Sensing Imagery Based on Large Vision Models
Nov 22, 2023

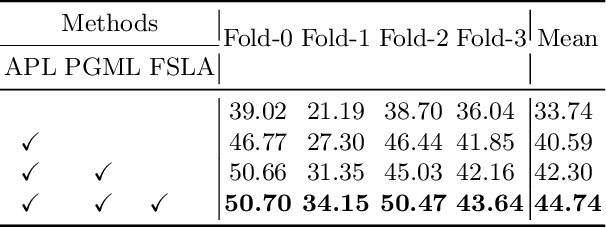
The Segment Anything Model (SAM) exhibits remarkable versatility and zero-shot learning abilities, owing largely to its extensive training data (SA-1B). Recognizing SAM's dependency on manual guidance given its category-agnostic nature, we identified unexplored potential within few-shot semantic segmentation tasks for remote sensing imagery. This research introduces a structured framework designed for the automation of few-shot semantic segmentation. It utilizes the SAM model and facilitates a more efficient generation of semantically discernible segmentation outcomes. Central to our methodology is a novel automatic prompt learning approach, leveraging prior guided masks to produce coarse pixel-wise prompts for SAM. Extensive experiments on the DLRSD datasets underline the superiority of our approach, outperforming other available few-shot methodologies.
Worst-case Design for RIS-aided Over-the-air Computation with Imperfect CSI
Jun 14, 2022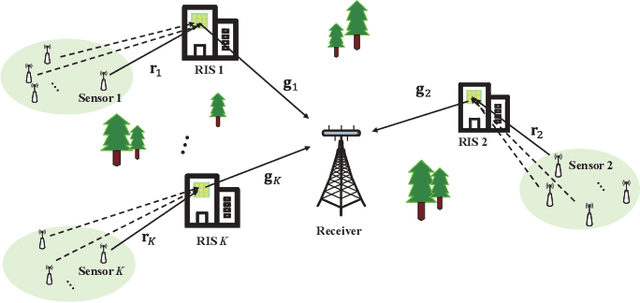
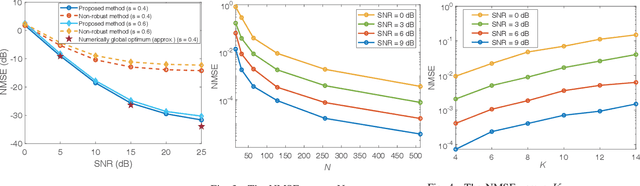
Over-the-air computation (AirComp) enables fast wireless data aggregation at the receiver through concurrent transmission by sensors in the application of Internet-of-Things (IoT). To further improve the performance of AirComp under unfavorable propagation channel conditions, we consider the problem of computation distortion minimization in a reconfigurable intelligent surface (RIS)-aided AirComp system. In particular, we take into account an additive bounded uncertainty of the channel state information (CSI) and the total power constraint, and jointly optimize the transceiver (Tx-Rx) and the RIS phase design from the perspective of worst-case robustness by minimizing the mean squared error (MSE) of the computation. To solve this intractable nonconvex problem, we develop an efficient alternating algorithm where both solutions to the robust sub-problem and to the joint design of Tx-Rx and RIS are obtained in closed forms. Simulation results demonstrate the effectiveness of the proposed method.
Enhanced countering adversarial attacks via input denoising and feature restoring
Nov 19, 2021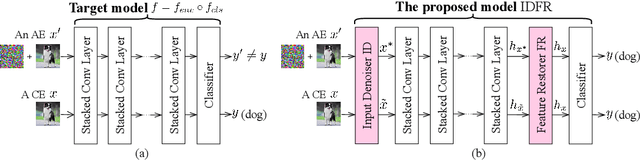
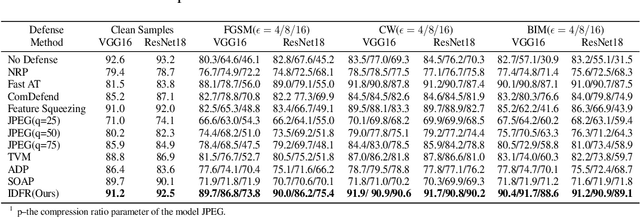
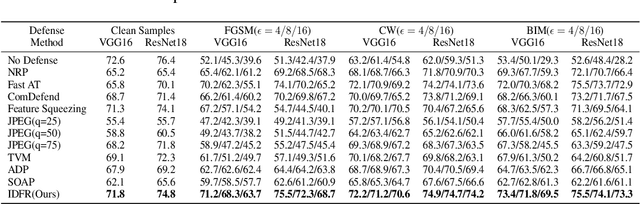
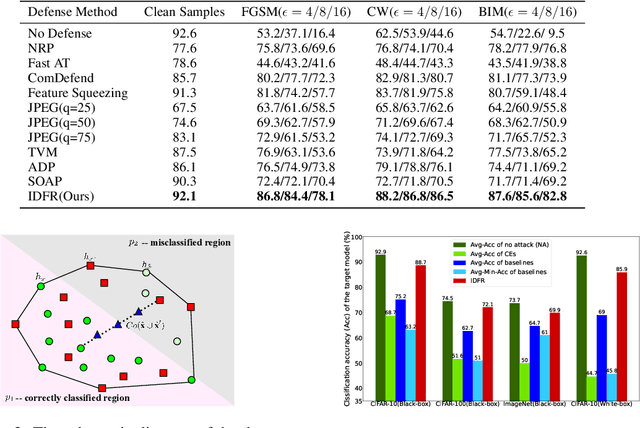
Despite the fact that deep neural networks (DNNs) have achieved prominent performance in various applications, it is well known that DNNs are vulnerable to adversarial examples/samples (AEs) with imperceptible perturbations in clean/original samples. To overcome the weakness of the existing defense methods against adversarial attacks, which damages the information on the original samples, leading to the decrease of the target classifier accuracy, this paper presents an enhanced countering adversarial attack method IDFR (via Input Denoising and Feature Restoring). The proposed IDFR is made up of an enhanced input denoiser (ID) and a hidden lossy feature restorer (FR) based on the convex hull optimization. Extensive experiments conducted on benchmark datasets show that the proposed IDFR outperforms the various state-of-the-art defense methods, and is highly effective for protecting target models against various adversarial black-box or white-box attacks. \footnote{Souce code is released at: \href{https://github.com/ID-FR/IDFR}{https://github.com/ID-FR/IDFR}}
End to End Video Segmentation for Driving : Lane Detection For Autonomous Car
Dec 13, 2018
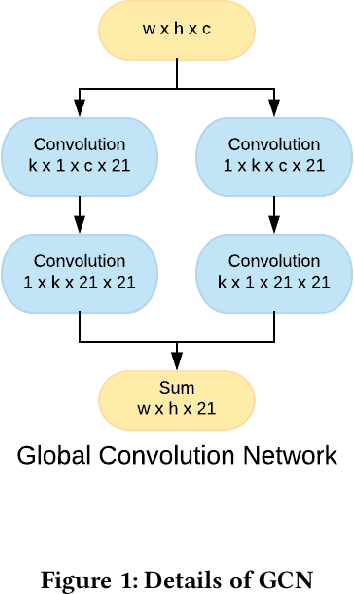
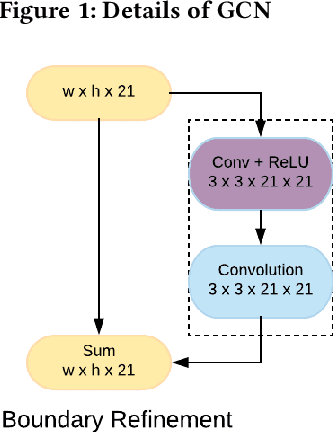
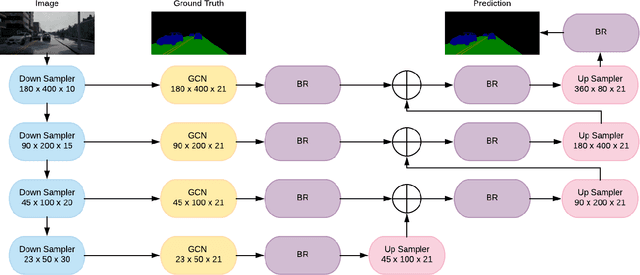
Safety and decline of road traffic accidents remain important issues of autonomous driving. Statistics show that unintended lane departure is a leading cause of worldwide motor vehicle collisions, making lane detection the most promising and challenge task for self-driving. Today, numerous groups are combining deep learning techniques with computer vision problems to solve self-driving problems. In this paper, a Global Convolution Networks (GCN) model is used to address both classification and localization issues for semantic segmentation of lane. We are using color-based segmentation is presented and the usability of the model is evaluated. A residual-based boundary refinement and Adam optimization is also used to achieve state-of-art performance. As normal cars could not afford GPUs on the car, and training session for a particular road could be shared by several cars. We propose a framework to get it work in real world. We build a real time video transfer system to get video from the car, get the model trained in edge server (which is equipped with GPUs), and send the trained model back to the car.