 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Experts Speak: Improving Survival Prediction & Calibration via Mixture-of-Experts Heads
Nov 11, 2025Deep mixture-of-experts models have attracted a lot of attention for survival analysis problems, particularly for their ability to cluster similar patients together. In practice, grouping often comes at the expense of key metrics such calibration error and predictive accuracy. This is due to the restrictive inductive bias that mixture-of-experts imposes, that predictions for individual patients must look like predictions for the group they're assigned to. Might we be able to discover patient group structure, where it exists, while improving calibration and predictive accuracy? In this work, we introduce several discrete-time deep mixture-of-experts (MoE) based architectures for survival analysis problems, one of which achieves all desiderata: clustering, calibration, and predictive accuracy. We show that a key differentiator between this array of MoEs is how expressive their experts are. We find that more expressive experts that tailor predictions per patient outperform experts that rely on fixed group prototypes.
Causal Decomposition Analysis with Synergistic Interventions: A Triply-Robust Machine Learning Approach to Addressing Multiple Dimensions of Social Disparities
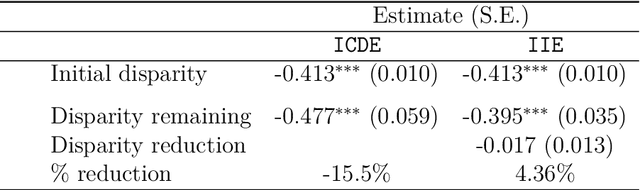
Jun 23, 2025Educational disparities are rooted in and perpetuate social inequalities across multiple dimensions such as race, socioeconomic status, and geography. To reduce disparities, most intervention strategies focus on a single domain and frequently evaluate their effectiveness by using causal decomposition analysis. However, a growing body of research suggests that single-domain interventions may be insufficient for individuals marginalized on multiple fronts. While interventions across multiple domains are increasingly proposed, there is limited guidance on appropriate methods for evaluating their effectiveness. To address this gap, we develop an extended causal decomposition analysis that simultaneously targets multiple causally ordered intervening factors, allowing for the assessment of their synergistic effects. These scenarios often involve challenges related to model misspecification due to complex interactions among group categories, intervening factors, and their confounders with the outcome. To mitigate these challenges, we introduce a triply robust estimator that leverages machine learning techniques to address potential model misspecification. We apply our method to a cohort of students from the High School Longitudinal Study, focusing on math achievement disparities between Black, Hispanic, and White high schoolers. Specifically, we examine how two sequential interventions - equalizing the proportion of students who attend high-performing schools and equalizing enrollment in Algebra I by 9th grade across racial groups - may reduce these disparities.
Simulation-Based Sensitivity Analysis in Optimal Treatment Regimes and Causal Decomposition with Individualized Interventions
Jun 23, 2025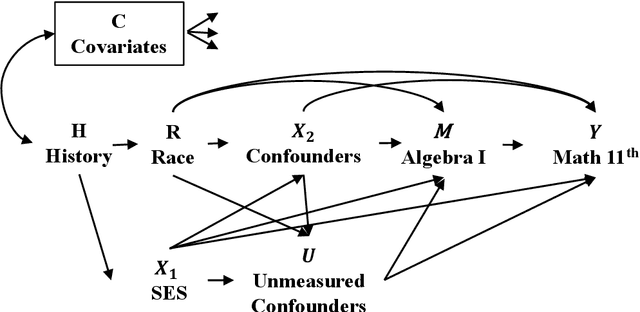
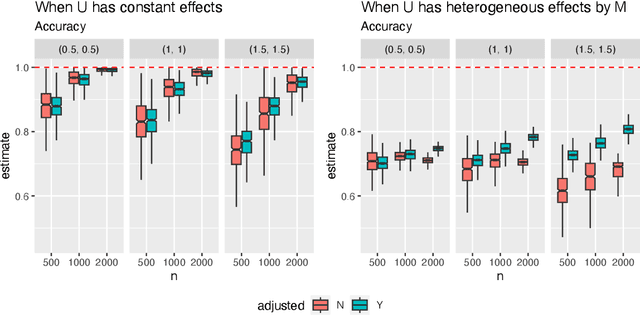
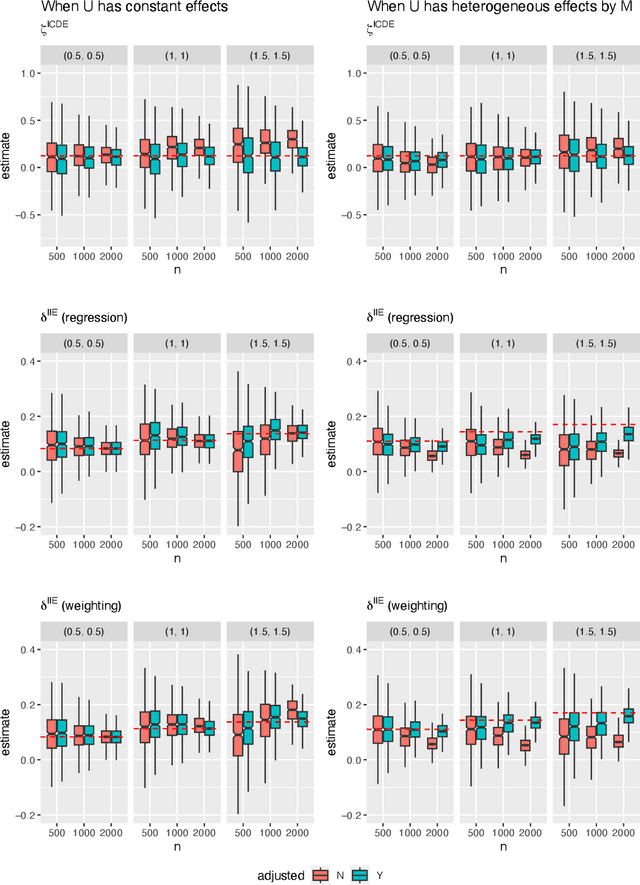
Causal decomposition analysis aims to assess the effect of modifying risk factors on reducing social disparities in outcomes. Recently, this analysis has incorporated individual characteristics when modifying risk factors by utilizing optimal treatment regimes (OTRs). Since the newly defined individualized effects rely on the no omitted confounding assumption, developing sensitivity analyses to account for potential omitted confounding is essential. Moreover, OTRs and individualized effects are primarily based on binary risk factors, and no formal approach currently exists to benchmark the strength of omitted confounding using observed covariates for binary risk factors. To address this gap, we extend a simulation-based sensitivity analysis that simulates unmeasured confounders, addressing two sources of bias emerging from deriving OTRs and estimating individualized effects. Additionally, we propose a formal bounding strategy that benchmarks the strength of omitted confounding for binary risk factors. Using the High School Longitudinal Study 2009 (HSLS:09), we demonstrate this sensitivity analysis and benchmarking method.
Evaluation of General Large Language Models in Contextually Assessing Semantic Concepts Extracted from Adult Critical Care Electronic Health Record Notes
Jan 24, 2024The field of healthcare has increasingly turned its focus towards Large Language Models (LLMs) due to their remarkable performance. However, their performance in actual clinical applications has been underexplored. Traditional evaluations based on question-answering tasks don't fully capture the nuanced contexts. This gap highlights the need for more in-depth and practical assessments of LLMs in real-world healthcare settings. Objective: We sought to evaluate the performance of LLMs in the complex clinical context of adult critical care medicine using systematic and comprehensible analytic methods, including clinician annotation and adjudication. Methods: We investigated the performance of three general LLMs in understanding and processing real-world clinical notes. Concepts from 150 clinical notes were identified by MetaMap and then labeled by 9 clinicians. Each LLM's proficiency was evaluated by identifying the temporality and negation of these concepts using different prompts for an in-depth analysis. Results: GPT-4 showed overall superior performance compared to other LLMs. In contrast, both GPT-3.5 and text-davinci-003 exhibit enhanced performance when the appropriate prompting strategies are employed. The GPT family models have demonstrated considerable efficiency, evidenced by their cost-effectiveness and time-saving capabilities. Conclusion: A comprehensive qualitative performance evaluation framework for LLMs is developed and operationalized. This framework goes beyond singular performance aspects. With expert annotations, this methodology not only validates LLMs' capabilities in processing complex medical data but also establishes a benchmark for future LLM evaluations across specialized domains.
Robustness of Object Recognition under Extreme Occlusion in Humans and Computational Models
Jun 04, 2019
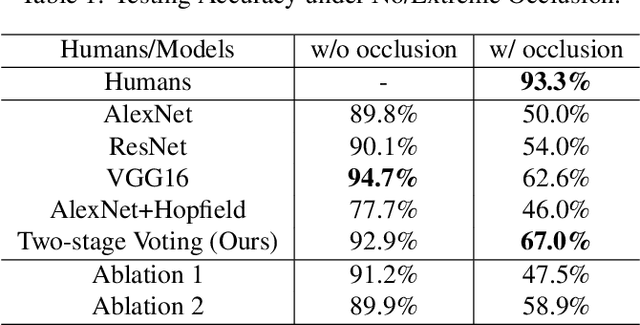
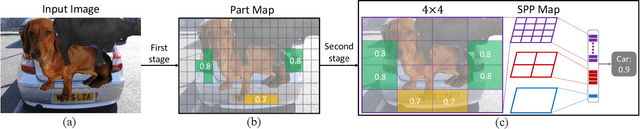
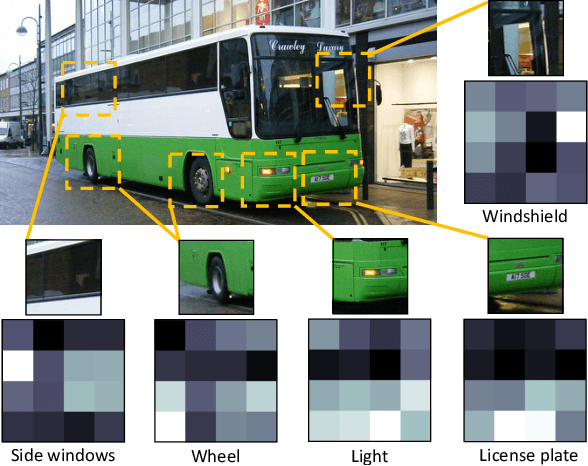
Most objects in the visual world are partially occluded, but humans can recognize them without difficulty. However, it remains unknown whether object recognition models like convolutional neural networks (CNNs) can handle real-world occlusion. It is also a question whether efforts to make these models robust to constant mask occlusion are effective for real-world occlusion. We test both humans and the above-mentioned computational models in a challenging task of object recognition under extreme occlusion, where target objects are heavily occluded by irrelevant real objects in real backgrounds. Our results show that human vision is very robust to extreme occlusion while CNNs are not, even with modifications to handle constant mask occlusion. This implies that the ability to handle constant mask occlusion does not entail robustness to real-world occlusion. As a comparison, we propose another computational model that utilizes object parts/subparts in a compositional manner to build robustness to occlusion. This performs significantly better than CNN-based models on our task with error patterns similar to humans. These findings suggest that testing under extreme occlusion can better reveal the robustness of visual recognition, and that the principle of composition can encourage such robustness.