 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Object Recognition under Extreme Occlusion in Humans and Computational Models
Paper and Code

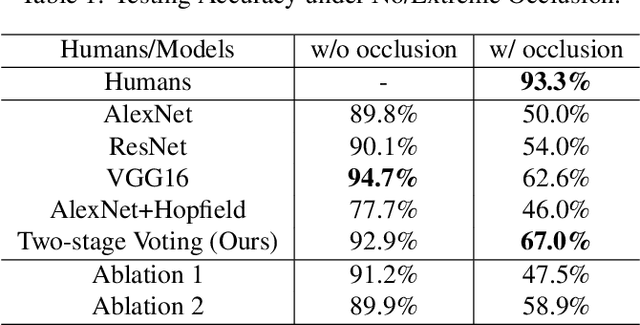
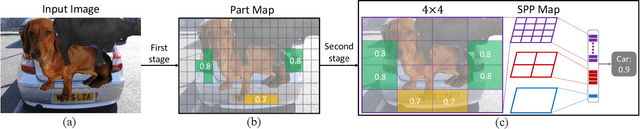
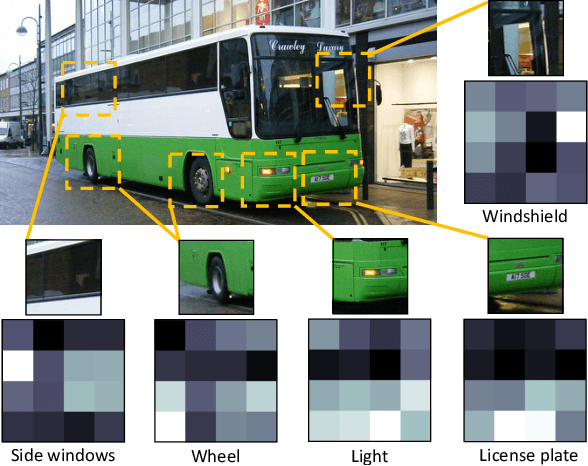
Most objects in the visual world are partially occluded, but humans can recognize them without difficulty. However, it remains unknown whether object recognition models like convolutional neural networks (CNNs) can handle real-world occlusion. It is also a question whether efforts to make these models robust to constant mask occlusion are effective for real-world occlusion. We test both humans and the above-mentioned computational models in a challenging task of object recognition under extreme occlusion, where target objects are heavily occluded by irrelevant real objects in real backgrounds. Our results show that human vision is very robust to extreme occlusion while CNNs are not, even with modifications to handle constant mask occlusion. This implies that the ability to handle constant mask occlusion does not entail robustness to real-world occlusion. As a comparison, we propose another computational model that utilizes object parts/subparts in a compositional manner to build robustness to occlusion. This performs significantly better than CNN-based models on our task with error patterns similar to humans. These findings suggest that testing under extreme occlusion can better reveal the robustness of visual recognition, and that the principle of composition can encourage such robustness.