 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
May 07, 2025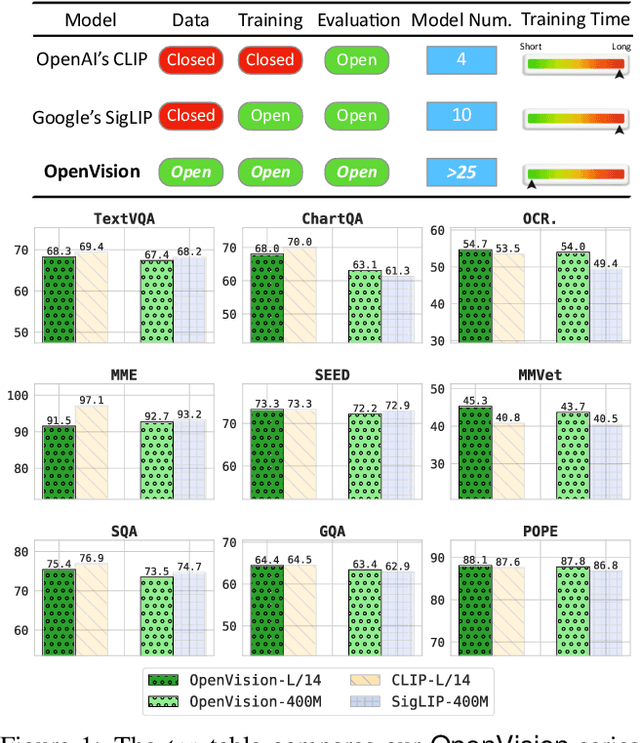
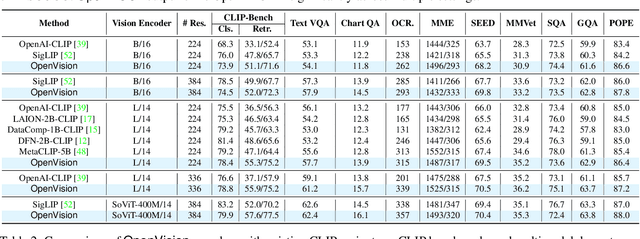
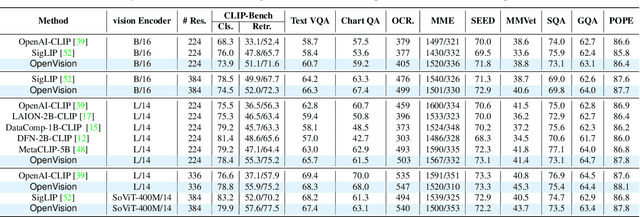
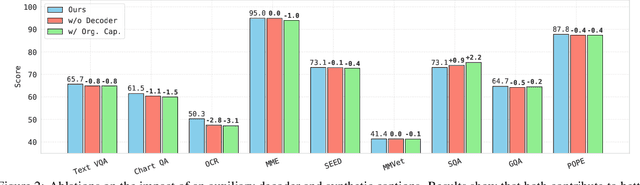
OpenAI's CLIP, released in early 2021, have long been the go-to choice of vision encoder for building multimodal foundation models. Although recent alternatives such as SigLIP have begun to challenge this status quo, to our knowledge none are fully open: their training data remains proprietary and/or their training recipes are not released. This paper fills this gap with OpenVision, a fully-open, cost-effective family of vision encoders that match or surpass the performance of OpenAI's CLIP when integrated into multimodal frameworks like LLaVA. OpenVision builds on existing works -- e.g., CLIPS for training framework and Recap-DataComp-1B for training data -- while revealing multiple key insights in enhancing encoder quality and showcasing practical benefits in advancing multimodal models. By releasing vision encoders spanning from 5.9M to 632.1M parameters, OpenVision offers practitioners a flexible trade-off between capacity and efficiency in building multimodal models: larger models deliver enhanced multimodal performance, while smaller versions enable lightweight, edge-ready multimodal deployments.
ARVideo: Autoregressive Pretraining for Self-Supervised Video Representation Learning
May 24, 2024



This paper presents a new self-supervised video representation learning framework, ARVideo, which autoregressively predicts the next video token in a tailored sequence order. Two key designs are included. First, we organize autoregressive video tokens into clusters that span both spatially and temporally, thereby enabling a richer aggregation of contextual information compared to the standard spatial-only or temporal-only clusters. Second, we adopt a randomized spatiotemporal prediction order to facilitate learning from multi-dimensional data, addressing the limitations of a handcrafted spatial-first or temporal-first sequence order. Extensive experiments establish ARVideo as an effective paradigm for self-supervised video representation learning. For example, when trained with the ViT-B backbone, ARVideo competitively attains 81.2% on Kinetics-400 and 70.9% on Something-Something V2, which are on par with the strong benchmark set by VideoMAE. Importantly, ARVideo also demonstrates higher training efficiency, i.e., it trains 14% faster and requires 58% less GPU memory compared to VideoMAE.
Unleashing the Potential of SAM for Medical Adaptation via Hierarchical Decoding
Mar 27, 2024The Segment Anything Model (SAM) has garnered significant attention for its versatile segmentation abilities and intuitive prompt-based interface. However, its application in medical imaging presents challenges, requiring either substantial training costs and extensive medical datasets for full model fine-tuning or high-quality prompts for optimal performance. This paper introduces H-SAM: a prompt-free adaptation of SAM tailored for efficient fine-tuning of medical images via a two-stage hierarchical decoding procedure. In the initial stage, H-SAM employs SAM's original decoder to generate a prior probabilistic mask, guiding a more intricate decoding process in the second stage. Specifically, we propose two key designs: 1) A class-balanced, mask-guided self-attention mechanism addressing the unbalanced label distribution, enhancing image embedding; 2) A learnable mask cross-attention mechanism spatially modulating the interplay among different image regions based on the prior mask. Moreover, the inclusion of a hierarchical pixel decoder in H-SAM enhances its proficiency in capturing fine-grained and localized details. This approach enables SAM to effectively integrate learned medical priors, facilitating enhanced adaptation for medical image segmentation with limited samples. Our H-SAM demonstrates a 4.78% improvement in average Dice compared to existing prompt-free SAM variants for multi-organ segmentation using only 10% of 2D slices. Notably, without using any unlabeled data, H-SAM even outperforms state-of-the-art semi-supervised models relying on extensive unlabeled training data across various medical datasets. Our code is available at https://github.com/Cccccczh404/H-SAM.
MicroDiffusion: Implicit Representation-Guided Diffusion for 3D Reconstruction from Limited 2D Microscopy Projections
Mar 16, 2024Volumetric optical microscopy using non-diffracting beams enables rapid imaging of 3D volumes by projecting them axially to 2D images but lacks crucial depth information. Addressing this, we introduce MicroDiffusion, a pioneering tool facilitating high-quality, depth-resolved 3D volume reconstruction from limited 2D projections. While existing Implicit Neural Representation (INR) models often yield incomplete outputs and Denoising Diffusion Probabilistic Models (DDPM) excel at capturing details, our method integrates INR's structural coherence with DDPM's fine-detail enhancement capabilities. We pretrain an INR model to transform 2D axially-projected images into a preliminary 3D volume. This pretrained INR acts as a global prior guiding DDPM's generative process through a linear interpolation between INR outputs and noise inputs. This strategy enriches the diffusion process with structured 3D information, enhancing detail and reducing noise in localized 2D images. By conditioning the diffusion model on the closest 2D projection, MicroDiffusion substantially enhances fidelity in resulting 3D reconstructions, surpassing INR and standard DDPM outputs with unparalleled image quality and structural fidelity. Our code and dataset are available at https://github.com/UCSC-VLAA/MicroDiffusion.
Revisiting Adversarial Training at Scale
Jan 09, 2024The machine learning community has witnessed a drastic change in the training pipeline, pivoted by those ''foundation models'' with unprecedented scales. However, the field of adversarial training is lagging behind, predominantly centered around small model sizes like ResNet-50, and tiny and low-resolution datasets like CIFAR-10. To bridge this transformation gap, this paper provides a modern re-examination with adversarial training, investigating its potential benefits when applied at scale. Additionally, we introduce an efficient and effective training strategy to enable adversarial training with giant models and web-scale data at an affordable computing cost. We denote this newly introduced framework as AdvXL. Empirical results demonstrate that AdvXL establishes new state-of-the-art robust accuracy records under AutoAttack on ImageNet-1K. For example, by training on DataComp-1B dataset, our AdvXL empowers a vanilla ViT-g model to substantially surpass the previous records of $l_{\infty}$-, $l_{2}$-, and $l_{1}$-robust accuracy by margins of 11.4%, 14.2% and 12.9%, respectively. This achievement posits AdvXL as a pioneering approach, charting a new trajectory for the efficient training of robust visual representations at significantly larger scales. Our code is available at https://github.com/UCSC-VLAA/AdvXL.
Rejuvenating image-GPT as Strong Visual Representation Learners
Dec 04, 2023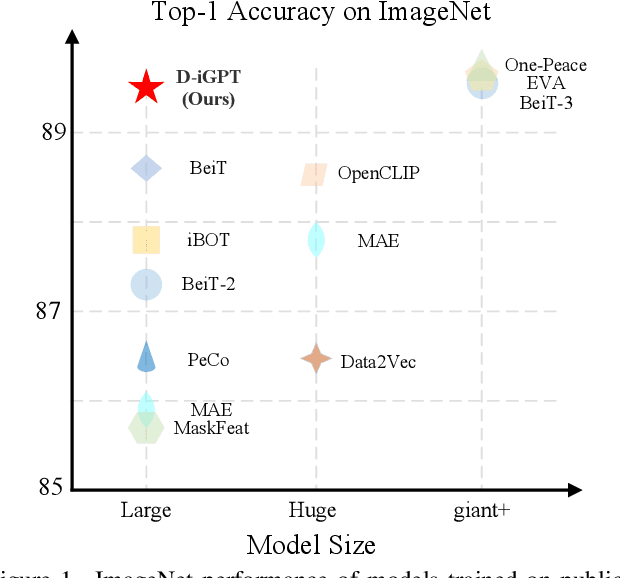
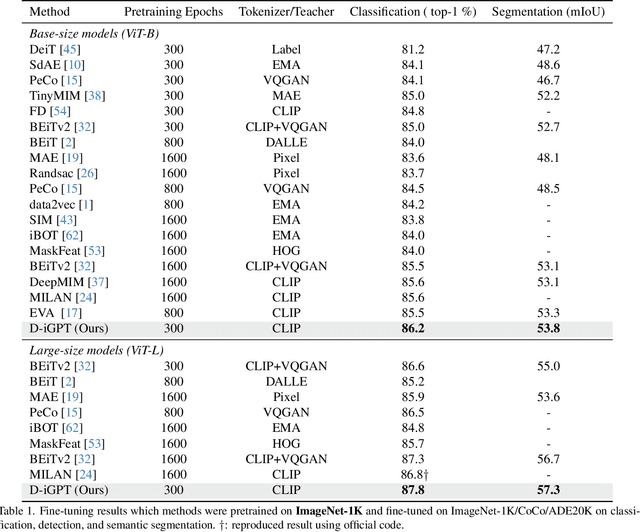
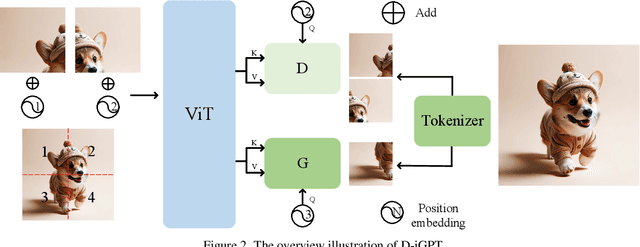
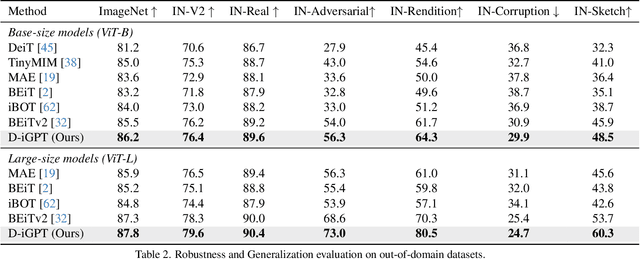
This paper enhances image-GPT (iGPT), one of the pioneering works that introduce autoregressive pretraining to predict next pixels for visual representation learning. Two simple yet essential changes are made. First, we shift the prediction target from raw pixels to semantic tokens, enabling a higher-level understanding of visual content. Second, we supplement the autoregressive modeling by instructing the model to predict not only the next tokens but also the visible tokens. This pipeline is particularly effective when semantic tokens are encoded by discriminatively trained models, such as CLIP. We introduce this novel approach as D-iGPT. Extensive experiments showcase that D-iGPT excels as a strong learner of visual representations: A notable achievement of D-iGPT is its compelling performance on the ImageNet-1K dataset -- by training on publicly available datasets, D-iGPT achieves 89.5\% top-1 accuracy with a vanilla ViT-Large model. This model also shows strong generalization on the downstream task and robustness on out-of-distribution samples. Code is avaiable at \href{https://github.com/OliverRensu/D-iGPT}{https://github.com/OliverRensu/D-iGPT}.
Improving EEG Decoding via Clustering-based Multi-task Feature Learning
Dec 12, 2020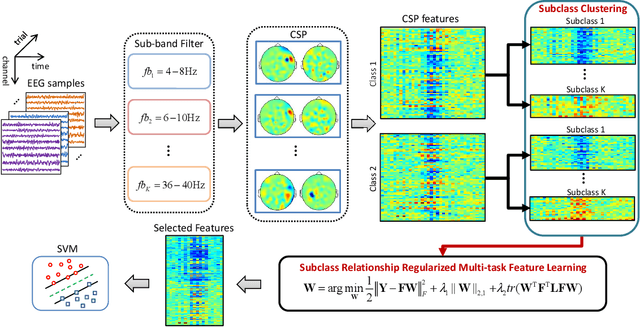
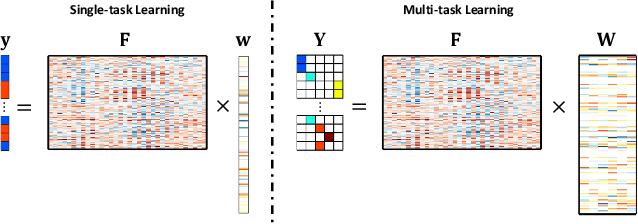
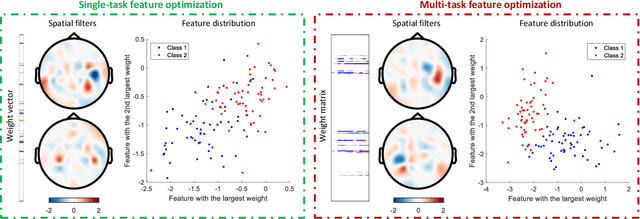
Accurate electroencephalogram (EEG) pattern decoding for specific mental tasks is one of the key steps for the development of brain-computer interface (BCI), which is quite challenging due to the considerably low signal-to-noise ratio of EEG collected at the brain scalp. Machine learning provides a promising technique to optimize EEG patterns toward better decoding accuracy. However, existing algorithms do not effectively explore the underlying data structure capturing the true EEG sample distribution, and hence can only yield a suboptimal decoding accuracy. To uncover the intrinsic distribution structure of EEG data, we propose a clustering-based multi-task feature learning algorithm for improved EEG pattern decoding. Specifically, we perform affinity propagation-based clustering to explore the subclasses (i.e., clusters) in each of the original classes, and then assign each subclass a unique label based on a one-versus-all encoding strategy. With the encoded label matrix, we devise a novel multi-task learning algorithm by exploiting the subclass relationship to jointly optimize the EEG pattern features from the uncovered subclasses. We then train a linear support vector machine with the optimized features for EEG pattern decoding. Extensive experimental studies are conducted on three EEG datasets to validate the effectiveness of our algorithm in comparison with other state-of-the-art approaches. The improved experimental results demonstrate the outstanding superiority of our algorithm, suggesting its prominent performance for EEG pattern decoding in BCI applications.
Robustness of Object Recognition under Extreme Occlusion in Humans and Computational Models
Jun 04, 2019
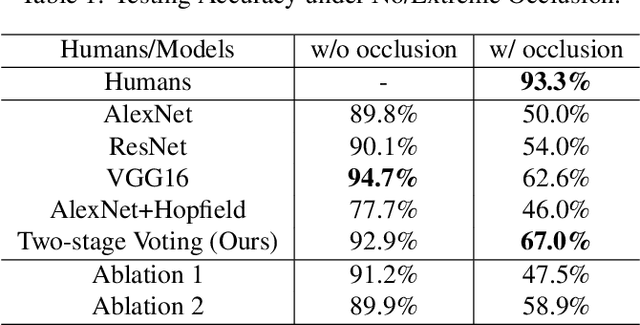
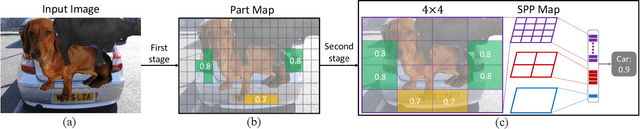
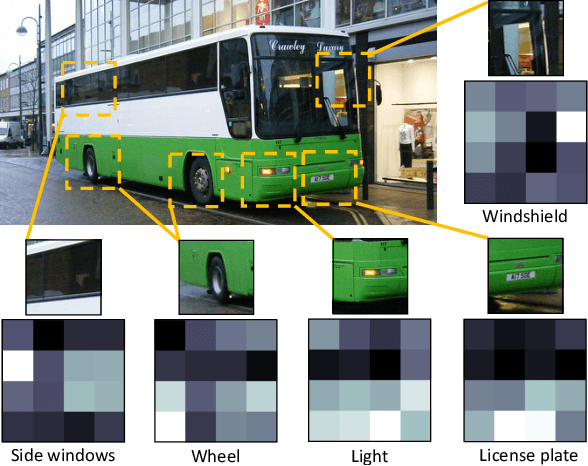
Most objects in the visual world are partially occluded, but humans can recognize them without difficulty. However, it remains unknown whether object recognition models like convolutional neural networks (CNNs) can handle real-world occlusion. It is also a question whether efforts to make these models robust to constant mask occlusion are effective for real-world occlusion. We test both humans and the above-mentioned computational models in a challenging task of object recognition under extreme occlusion, where target objects are heavily occluded by irrelevant real objects in real backgrounds. Our results show that human vision is very robust to extreme occlusion while CNNs are not, even with modifications to handle constant mask occlusion. This implies that the ability to handle constant mask occlusion does not entail robustness to real-world occlusion. As a comparison, we propose another computational model that utilizes object parts/subparts in a compositional manner to build robustness to occlusion. This performs significantly better than CNN-based models on our task with error patterns similar to humans. These findings suggest that testing under extreme occlusion can better reveal the robustness of visual recognition, and that the principle of composition can encourage such robustness.