 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Environment Atlas for Object-Goal Navigation
Oct 05, 2024
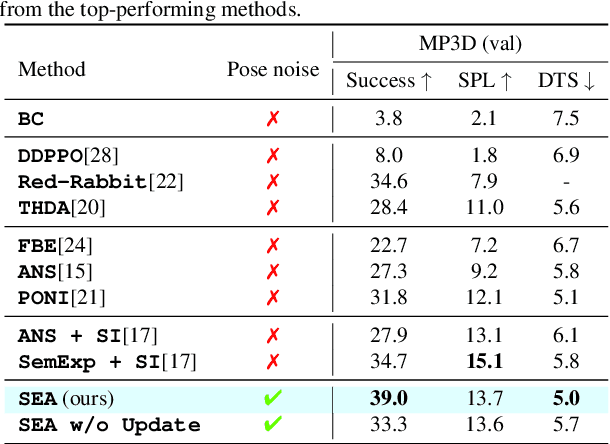
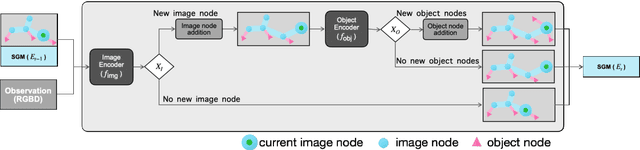
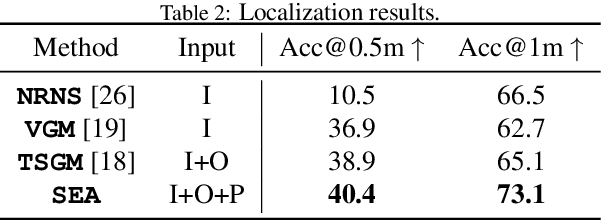
In this paper, we introduce the Semantic Environment Atlas (SEA), a novel mapping approach designed to enhance visual navigation capabilities of embodied agents. The SEA utilizes semantic graph maps that intricately delineate the relationships between places and objects, thereby enriching the navigational context. These maps are constructed from image observations and capture visual landmarks as sparsely encoded nodes within the environment. The SEA integrates multiple semantic maps from various environments, retaining a memory of place-object relationships, which proves invaluable for tasks such as visual localization and navigation. We developed navigation frameworks that effectively leverage the SEA, and we evaluated these frameworks through visual localization and object-goal navigation tasks. Our SEA-based localization framework significantly outperforms existing methods, accurately identifying locations from single query images. Experimental results in Habitat scenarios show that our method not only achieves a success rate of 39.0%, an improvement of 12.4% over the current state-of-the-art, but also maintains robustness under noisy odometry and actuation conditions, all while keeping computational costs low.
* 30 pages
Scale-Invariant Gradient Aggregation for Constrained Multi-Objective Reinforcement Learning
Mar 01, 2024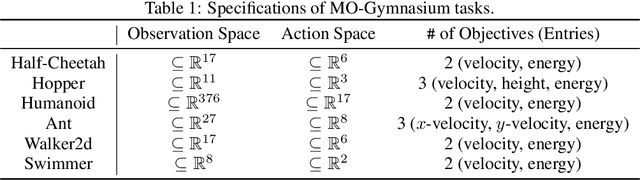
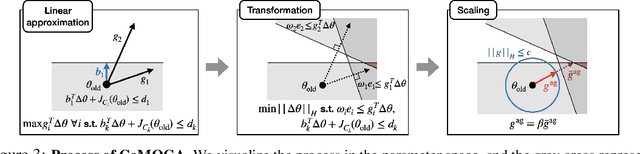

Multi-objective reinforcement learning (MORL) aims to find a set of Pareto optimal policies to cover various preferences. However, to apply MORL in real-world applications, it is important to find policies that are not only Pareto optimal but also satisfy pre-defined constraints for safety. To this end, we propose a constrained MORL (CMORL) algorithm called Constrained Multi-Objective Gradient Aggregator (CoMOGA). Recognizing the difficulty of handling multiple objectives and constraints concurrently, CoMOGA relaxes the original CMORL problem into a constrained optimization problem by transforming the objectives into additional constraints. This novel transformation process ensures that the converted constraints are invariant to the objective scales while having the same effect as the original objectives. We show that the proposed method converges to a local Pareto optimal policy while satisfying the predefined constraints. Empirical evaluations across various tasks show that the proposed method outperforms other baselines by consistently meeting constraints and demonstrating invariance to the objective scales.
Renderable Neural Radiance Map for Visual Navigation
Mar 03, 2023



We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The navigation framework shows 65.7% success rate in curved scenarios of the NRNS dataset, which is an improvement of 18.6% over the current state-of-the-art.
Topological Semantic Graph Memory for Image-Goal Navigation
Sep 17, 2022
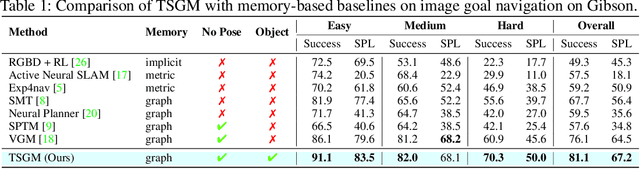
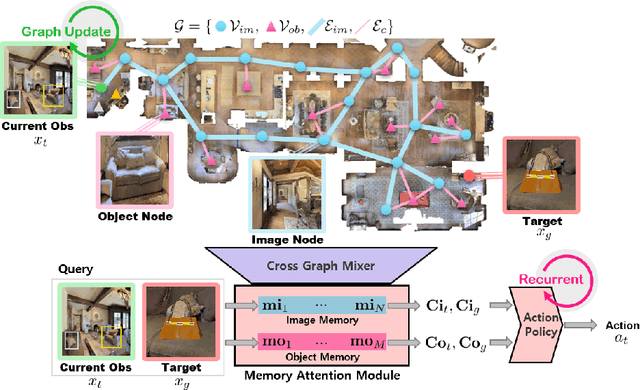
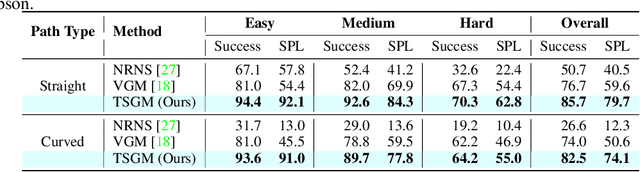
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. % The semantic graph memory is collected from a panoramic observation of an RGB-D camera without knowing the robot's pose. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
Robustness of Object Recognition under Extreme Occlusion in Humans and Computational Models
Jun 04, 2019
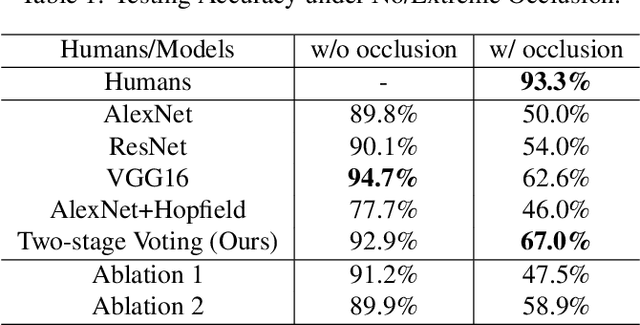
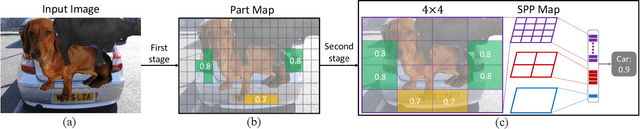
Most objects in the visual world are partially occluded, but humans can recognize them without difficulty. However, it remains unknown whether object recognition models like convolutional neural networks (CNNs) can handle real-world occlusion. It is also a question whether efforts to make these models robust to constant mask occlusion are effective for real-world occlusion. We test both humans and the above-mentioned computational models in a challenging task of object recognition under extreme occlusion, where target objects are heavily occluded by irrelevant real objects in real backgrounds. Our results show that human vision is very robust to extreme occlusion while CNNs are not, even with modifications to handle constant mask occlusion. This implies that the ability to handle constant mask occlusion does not entail robustness to real-world occlusion. As a comparison, we propose another computational model that utilizes object parts/subparts in a compositional manner to build robustness to occlusion. This performs significantly better than CNN-based models on our task with error patterns similar to humans. These findings suggest that testing under extreme occlusion can better reveal the robustness of visual recognition, and that the principle of composition can encourage such robustness.