 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dexterous Grasping from Sparse Taxonomy Guidance
Apr 05, 2026Dexterous manipulation requires planning a grasp configuration suited to the object and task, which is then executed through coordinated multi-finger control. However, specifying grasp plans with dense pose or contact targets for every object and task is impractical. Meanwhile, end-to-end reinforcement learning from task rewards alone lacks controllability, making it difficult for users to intervene when failures occur. To this end, we present GRIT, a two-stage framework that learns dexterous control from sparse taxonomy guidance. GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Our result shows that certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9%. Moreover, real-world experiments demonstrate controllability, enabling grasp strategies to be adjusted through high-level taxonomy selection based on object geometry and task intent.
Learning Generalizable Visuomotor Policy through Dynamics-Alignment
Oct 31, 2025Behavior cloning methods for robot learning suffer from poor generalization due to limited data support beyond expert demonstrations. Recent approaches leveraging video prediction models have shown promising results by learning rich spatiotemporal representations from large-scale datasets. However, these models learn action-agnostic dynamics that cannot distinguish between different control inputs, limiting their utility for precise manipulation tasks and requiring large pretraining datasets. We propose a Dynamics-Aligned Flow Matching Policy (DAP) that integrates dynamics prediction into policy learning. Our method introduces a novel architecture where policy and dynamics models provide mutual corrective feedback during action generation, enabling self-correction and improved generalization. Empirical validation demonstrates generalization performance superior to baseline methods on real-world robotic manipulation tasks, showing particular robustness in OOD scenarios including visual distractions and lighting variations.
Policy-labeled Preference Learning: Is Preference Enough for RLHF?
May 13, 2025To design rewards that align with human goals, Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent technique for learning reward functions from human preferences and optimizing policies via reinforcement learning algorithms. However, existing RLHF methods often misinterpret trajectories as being generated by an optimal policy, causing inaccurate likelihood estimation and suboptimal learning. Inspired by Direct Preference Optimization framework which directly learns optimal policy without explicit reward, we propose policy-labeled preference learning (PPL), to resolve likelihood mismatch issues by modeling human preferences with regret, which reflects behavior policy information. We also provide a contrastive KL regularization, derived from regret-based principles, to enhance RLHF in sequential decision making. Experiments in high-dimensional continuous control tasks demonstrate PPL's significant improvements in offline RLHF performance and its effectiveness in online settings.
Adversarial Environment Design via Regret-Guided Diffusion Models
Oct 25, 2024


Training agents that are robust to environmental changes remains a significant challenge in deep reinforcement learning (RL). Unsupervised environment design (UED) has recently emerged to address this issue by generating a set of training environments tailored to the agent's capabilities. While prior works demonstrate that UED has the potential to learn a robust policy, their performance is constrained by the capabilities of the environment generation. To this end, we propose a novel UED algorithm, adversarial environment design via regret-guided diffusion models (ADD). The proposed method guides the diffusion-based environment generator with the regret of the agent to produce environments that the agent finds challenging but conducive to further improvement. By exploiting the representation power of diffusion models, ADD can directly generate adversarial environments while maintaining the diversity of training environments, enabling the agent to effectively learn a robust policy. Our experimental results demonstrate that the proposed method successfully generates an instructive curriculum of environments, outperforming UED baselines in zero-shot generalization across novel, out-of-distribution environments. Project page: https://github.com/rllab-snu.github.io/projects/ADD
Tractable and Provably Efficient Distributional Reinforcement Learning with General Value Function Approximation
Jul 31, 2024Distributional reinforcement learning improves performance by effectively capturing environmental stochasticity, but a comprehensive theoretical understanding of its effectiveness remains elusive. In this paper, we present a regret analysis for distributional reinforcement learning with general value function approximation in a finite episodic Markov decision process setting. We first introduce a key notion of Bellman unbiasedness for a tractable and exactly learnable update via statistical functional dynamic programming. Our theoretical results show that approximating the infinite-dimensional return distribution with a finite number of moment functionals is the only method to learn the statistical information unbiasedly, including nonlinear statistical functionals. Second, we propose a provably efficient algorithm, $\texttt{SF-LSVI}$, achieving a regret bound of $\tilde{O}(d_E H^{\frac{3}{2}}\sqrt{K})$ where $H$ is the horizon, $K$ is the number of episodes, and $d_E$ is the eluder dimension of a function class.
Spectral-Risk Safe Reinforcement Learning with Convergence Guarantees
May 29, 2024
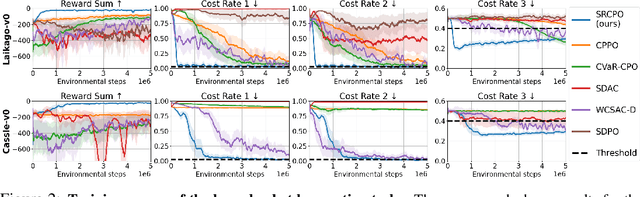
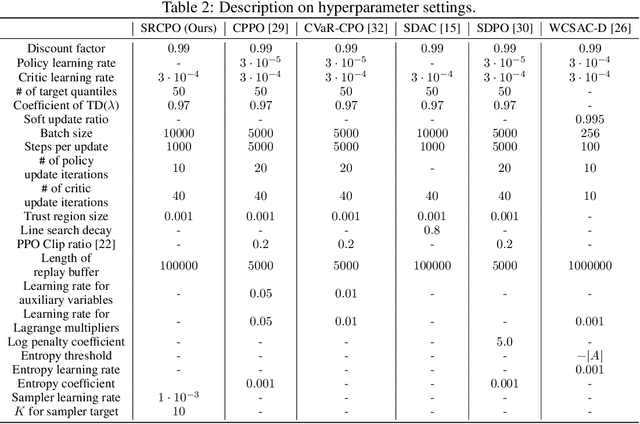
The field of risk-constrained reinforcement learning (RCRL) has been developed to effectively reduce the likelihood of worst-case scenarios by explicitly handling risk-measure-based constraints. However, the nonlinearity of risk measures makes it challenging to achieve convergence and optimality. To overcome the difficulties posed by the nonlinearity, we propose a spectral risk measure-constrained RL algorithm, spectral-risk-constrained policy optimization (SRCPO), a bilevel optimization approach that utilizes the duality of spectral risk measures. In the bilevel optimization structure, the outer problem involves optimizing dual variables derived from the risk measures, while the inner problem involves finding an optimal policy given these dual variables. The proposed method, to the best of our knowledge, is the first to guarantee convergence to an optimum in the tabular setting. Furthermore, the proposed method has been evaluated on continuous control tasks and showed the best performance among other RCRL algorithms satisfying the constraints.
The Third Monocular Depth Estimation Challenge
Apr 27, 2024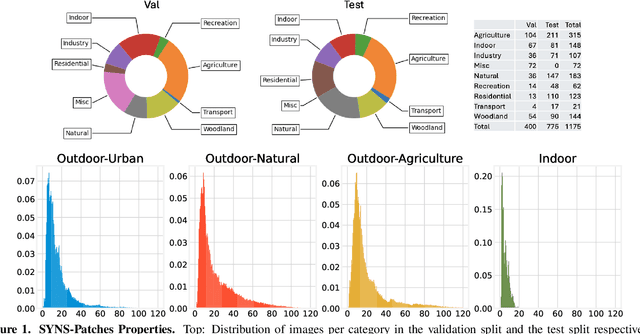

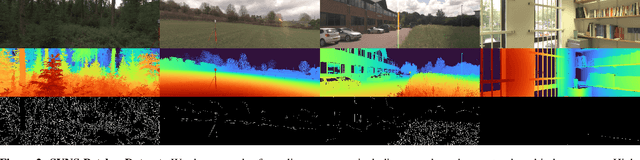
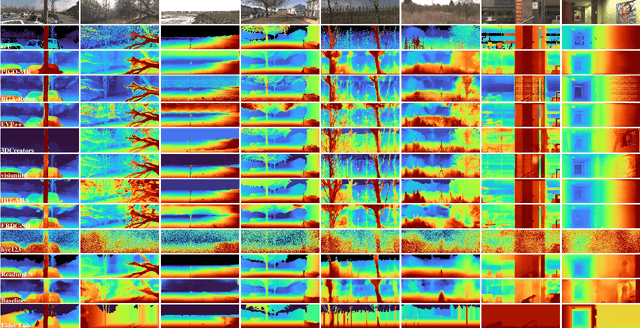
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
Scale-Invariant Gradient Aggregation for Constrained Multi-Objective Reinforcement Learning
Mar 01, 2024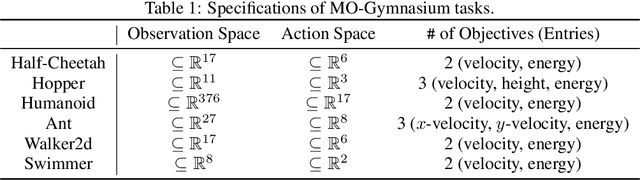
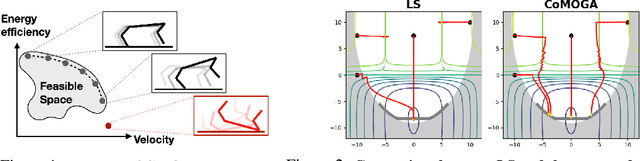
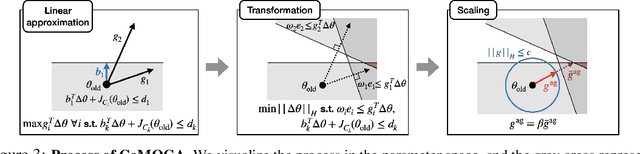

Multi-objective reinforcement learning (MORL) aims to find a set of Pareto optimal policies to cover various preferences. However, to apply MORL in real-world applications, it is important to find policies that are not only Pareto optimal but also satisfy pre-defined constraints for safety. To this end, we propose a constrained MORL (CMORL) algorithm called Constrained Multi-Objective Gradient Aggregator (CoMOGA). Recognizing the difficulty of handling multiple objectives and constraints concurrently, CoMOGA relaxes the original CMORL problem into a constrained optimization problem by transforming the objectives into additional constraints. This novel transformation process ensures that the converted constraints are invariant to the objective scales while having the same effect as the original objectives. We show that the proposed method converges to a local Pareto optimal policy while satisfying the predefined constraints. Empirical evaluations across various tasks show that the proposed method outperforms other baselines by consistently meeting constraints and demonstrating invariance to the objective scales.
TRC: Trust Region Conditional Value at Risk for Safe Reinforcement Learning
Dec 01, 2023As safety is of paramount importance in robotics, reinforcement learning that reflects safety, called safe RL, has been studied extensively. In safe RL, we aim to find a policy which maximizes the desired return while satisfying the defined safety constraints. There are various types of constraints, among which constraints on conditional value at risk (CVaR) effectively lower the probability of failures caused by high costs since CVaR is a conditional expectation obtained above a certain percentile. In this paper, we propose a trust region-based safe RL method with CVaR constraints, called TRC. We first derive the upper bound on CVaR and then approximate the upper bound in a differentiable form in a trust region. Using this approximation, a subproblem to get policy gradients is formulated, and policies are trained by iteratively solving the subproblem. TRC is evaluated through safe navigation tasks in simulations with various robots and a sim-to-real environment with a Jackal robot from Clearpath. Compared to other safe RL methods, the performance is improved by 1.93 times while the constraints are satisfied in all experiments.
* RA-L and ICRA 2022
Efficient Off-Policy Safe Reinforcement Learning Using Trust Region Conditional Value at Risk
Dec 01, 2023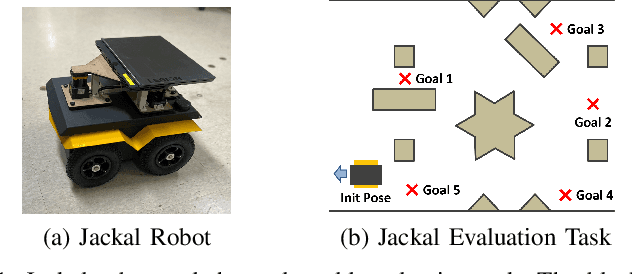
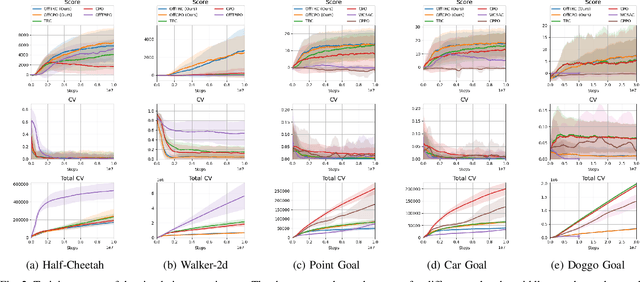
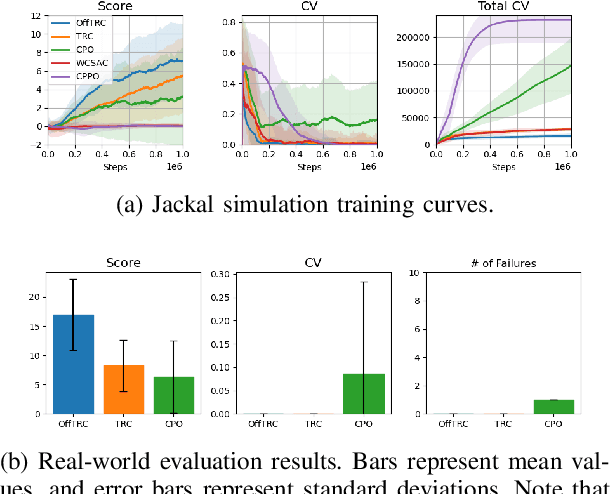
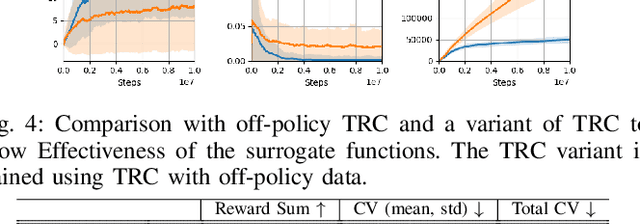
This paper aims to solve a safe reinforcement learning (RL) problem with risk measure-based constraints. As risk measures, such as conditional value at risk (CVaR), focus on the tail distribution of cost signals, constraining risk measures can effectively prevent a failure in the worst case. An on-policy safe RL method, called TRC, deals with a CVaR-constrained RL problem using a trust region method and can generate policies with almost zero constraint violations with high returns. However, to achieve outstanding performance in complex environments and satisfy safety constraints quickly, RL methods are required to be sample efficient. To this end, we propose an off-policy safe RL method with CVaR constraints, called off-policy TRC. If off-policy data from replay buffers is directly used to train TRC, the estimation error caused by the distributional shift results in performance degradation. To resolve this issue, we propose novel surrogate functions, in which the effect of the distributional shift can be reduced, and introduce an adaptive trust-region constraint to ensure a policy not to deviate far from replay buffers. The proposed method has been evaluated in simulation and real-world environments and satisfied safety constraints within a few steps while achieving high returns even in complex robotic tasks.
* RA-L and IROS 2022