 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Trust Region-Based Safe Reinforcement Learning with Low-Bias Distributional Actor-Critic
Paper and Code
Jan 26, 2023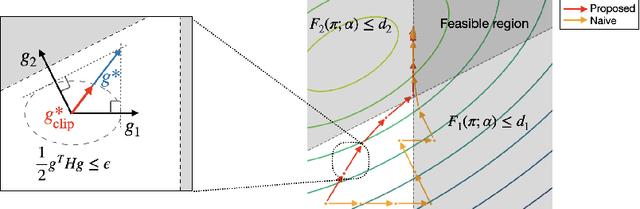


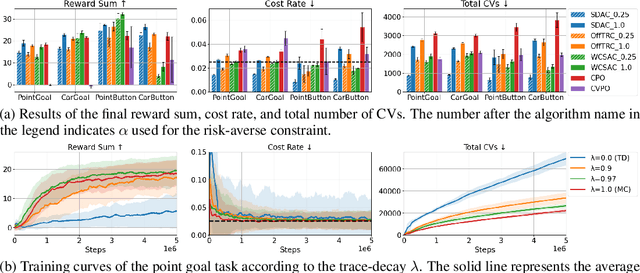
To apply reinforcement learning (RL) to real-world applications, agents are required to adhere to the safety guidelines of their respective domains. Safe RL can effectively handle the guidelines by converting them into constraints of the RL problem. In this paper, we develop a safe distributional RL method based on the trust region method, which can satisfy constraints consistently. However, policies may not meet the safety guidelines due to the estimation bias of distributional critics, and importance sampling required for the trust region method can hinder performance due to its significant variance. Hence, we enhance safety performance through the following approaches. First, we train distributional critics to have low estimation biases using proposed target distributions where bias-variance can be traded off. Second, we propose novel surrogates for the trust region method expressed with Q-functions using the reparameterization trick. Additionally, depending on initial policy settings, there can be no policy satisfying constraints within a trust region. To handle this infeasible issue, we propose a gradient integration method which guarantees to find a policy satisfying all constraints from an unsafe initial policy. From extensive experiments, the proposed method with risk-averse constraints shows minimal constraint violations while achieving high returns compared to existing safe RL methods.