 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regret Minimization Framework on Preference Learning in Large Language Models
Jun 08, 2026Reinforcement learning with verifiable rewards (RLVR) has enabled progress on reasoning-intensive tasks by relying on task-specific verifiers that provide automated correctness signals. However, many realistic language tasks are difficult to equip with reliable verifiers, motivating a growing reliance on reinforcement learning from human feedback (RLHF). In this setting, we argue that a closer examination of how human feedback should be interpreted is essential. We introduce Regret-based Preference Optimization $(\textbf{RePO})$, which reframes RLHF through $\textit{regret minimization}$ rather than reward maximization. Human preferences are often shaped by $\textit{prospective}$ anticipation of outcomes and $\textit{counterfactual}$ comparisons to alternative behaviors, rather than by immediate, outcome-independent utility. $\textbf{RePO}$ captures this structure by modeling preferences as behavior-conditioned assessments of relative suboptimality. Experiments on mathematical reasoning benchmarks and human preference datasets demonstrate consistent performance gains, indicating that $\textbf{RePO}$ is an effective and human-aligned approach for training large language models.
Probabilistic Smoothing with Ratio-Monotone Transforms for Global Optimization
May 26, 2026Probabilistic smoothing is a standard tool for global optimization, but existing methods rely on Gaussian kernels and specific transforms, often resulting in strong hyperparameter sensitivity and limited robustness. We propose a general smoothing framework that combines flexible symmetric unimodal kernels with monotonic ratio-based transformations. Under mild conditions, we show that the smoothed objective preserves the global maximizer and that all stationary points concentrate near the true optimum for sufficiently large amplification, without requiring a decreasing smoothing schedule. We further provide explicit complexity bounds for stochastic gradient ascent and show that a leave-one-out baseline provably reduces variance. Experiments on high-dimensional benchmarks and black-box adversarial attacks demonstrate improved robustness and competitive performance.
MVP-LAM: Learning Action-Centric Latent Action via Cross-Viewpoint Reconstruction
Feb 03, 2026Learning \emph{latent actions} from diverse human videos enables scaling robot learning beyond embodiment-specific robot datasets, and these latent actions have recently been used as pseudo-action labels for vision-language-action (VLA) model pretraining. To make VLA pretraining effective, latent actions should contain information about the underlying agent's actions despite the absence of ground-truth labels. We propose \textbf{M}ulti-\textbf{V}iew\textbf{P}oint \textbf{L}atent \textbf{A}ction \textbf{M}odel (\textbf{MVP-LAM}), which learns discrete latent actions that are highly informative about ground-truth actions from time-synchronized multi-view videos. MVP-LAM trains latent actions with a \emph{cross-viewpoint reconstruction} objective, so that a latent action inferred from one view must explain the future in another view, reducing reliance on viewpoint-specific cues. On Bridge V2, MVP-LAM produces more action-centric latent actions, achieving higher mutual information with ground-truth actions and improved action prediction, including under out-of-distribution evaluation. Finally, pretraining VLAs with MVP-LAM latent actions improves downstream manipulation performance on the SIMPLER and LIBERO-Long benchmarks.
Policy-labeled Preference Learning: Is Preference Enough for RLHF?
May 13, 2025To design rewards that align with human goals, Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent technique for learning reward functions from human preferences and optimizing policies via reinforcement learning algorithms. However, existing RLHF methods often misinterpret trajectories as being generated by an optimal policy, causing inaccurate likelihood estimation and suboptimal learning. Inspired by Direct Preference Optimization framework which directly learns optimal policy without explicit reward, we propose policy-labeled preference learning (PPL), to resolve likelihood mismatch issues by modeling human preferences with regret, which reflects behavior policy information. We also provide a contrastive KL regularization, derived from regret-based principles, to enhance RLHF in sequential decision making. Experiments in high-dimensional continuous control tasks demonstrate PPL's significant improvements in offline RLHF performance and its effectiveness in online settings.
Tractable and Provably Efficient Distributional Reinforcement Learning with General Value Function Approximation
Jul 31, 2024Distributional reinforcement learning improves performance by effectively capturing environmental stochasticity, but a comprehensive theoretical understanding of its effectiveness remains elusive. In this paper, we present a regret analysis for distributional reinforcement learning with general value function approximation in a finite episodic Markov decision process setting. We first introduce a key notion of Bellman unbiasedness for a tractable and exactly learnable update via statistical functional dynamic programming. Our theoretical results show that approximating the infinite-dimensional return distribution with a finite number of moment functionals is the only method to learn the statistical information unbiasedly, including nonlinear statistical functionals. Second, we propose a provably efficient algorithm, $\texttt{SF-LSVI}$, achieving a regret bound of $\tilde{O}(d_E H^{\frac{3}{2}}\sqrt{K})$ where $H$ is the horizon, $K$ is the number of episodes, and $d_E$ is the eluder dimension of a function class.
Spectral-Risk Safe Reinforcement Learning with Convergence Guarantees
May 29, 2024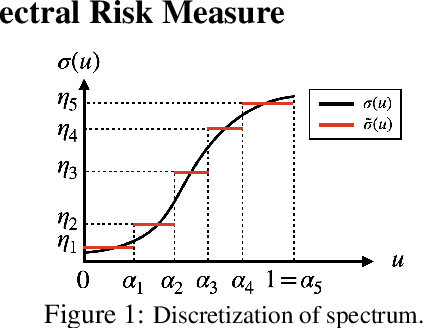
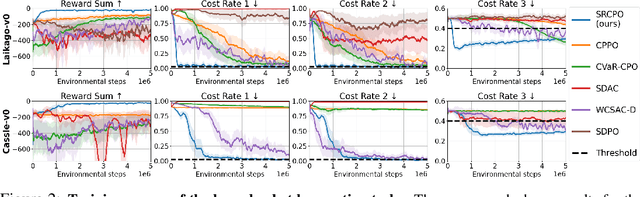
The field of risk-constrained reinforcement learning (RCRL) has been developed to effectively reduce the likelihood of worst-case scenarios by explicitly handling risk-measure-based constraints. However, the nonlinearity of risk measures makes it challenging to achieve convergence and optimality. To overcome the difficulties posed by the nonlinearity, we propose a spectral risk measure-constrained RL algorithm, spectral-risk-constrained policy optimization (SRCPO), a bilevel optimization approach that utilizes the duality of spectral risk measures. In the bilevel optimization structure, the outer problem involves optimizing dual variables derived from the risk measures, while the inner problem involves finding an optimal policy given these dual variables. The proposed method, to the best of our knowledge, is the first to guarantee convergence to an optimum in the tabular setting. Furthermore, the proposed method has been evaluated on continuous control tasks and showed the best performance among other RCRL algorithms satisfying the constraints.
On the Convergence of Continual Learning with Adaptive Methods
Apr 15, 2024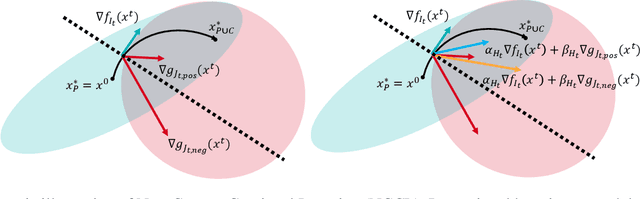
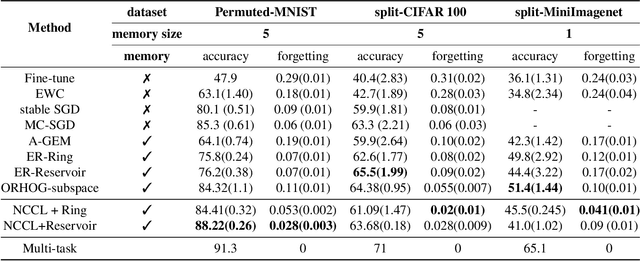
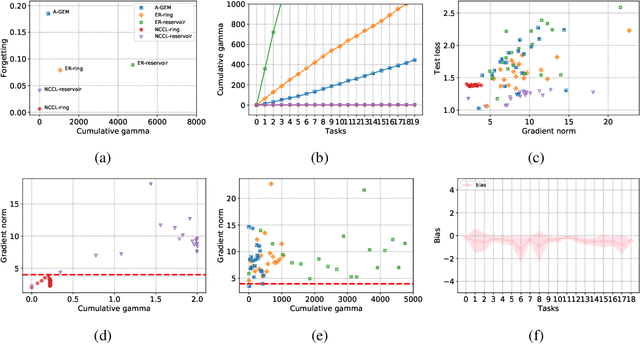
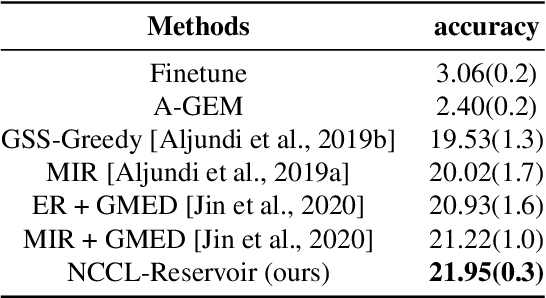
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
* Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI 2023), see https://proceedings.mlr.press/v216/han23a.html
SPQR: Controlling Q-ensemble Independence with Spiked Random Model for Reinforcement Learning
Jan 06, 2024Alleviating overestimation bias is a critical challenge for deep reinforcement learning to achieve successful performance on more complex tasks or offline datasets containing out-of-distribution data. In order to overcome overestimation bias, ensemble methods for Q-learning have been investigated to exploit the diversity of multiple Q-functions. Since network initialization has been the predominant approach to promote diversity in Q-functions, heuristically designed diversity injection methods have been studied in the literature. However, previous studies have not attempted to approach guaranteed independence over an ensemble from a theoretical perspective. By introducing a novel regularization loss for Q-ensemble independence based on random matrix theory, we propose spiked Wishart Q-ensemble independence regularization (SPQR) for reinforcement learning. Specifically, we modify the intractable hypothesis testing criterion for the Q-ensemble independence into a tractable KL divergence between the spectral distribution of the Q-ensemble and the target Wigner's semicircle distribution. We implement SPQR in several online and offline ensemble Q-learning algorithms. In the experiments, SPQR outperforms the baseline algorithms in both online and offline RL benchmarks.
Pitfall of Optimism: Distributional Reinforcement Learning by Randomizing Risk Criterion
Oct 27, 2023Distributional reinforcement learning algorithms have attempted to utilize estimated uncertainty for exploration, such as optimism in the face of uncertainty. However, using the estimated variance for optimistic exploration may cause biased data collection and hinder convergence or performance. In this paper, we present a novel distributional reinforcement learning algorithm that selects actions by randomizing risk criterion to avoid one-sided tendency on risk. We provide a perturbed distributional Bellman optimality operator by distorting the risk measure and prove the convergence and optimality of the proposed method with the weaker contraction property. Our theoretical results support that the proposed method does not fall into biased exploration and is guaranteed to converge to an optimal return. Finally, we empirically show that our method outperforms other existing distribution-based algorithms in various environments including Atari 55 games.