 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Environment Atlas for Object-Goal Navigation
Oct 05, 2024
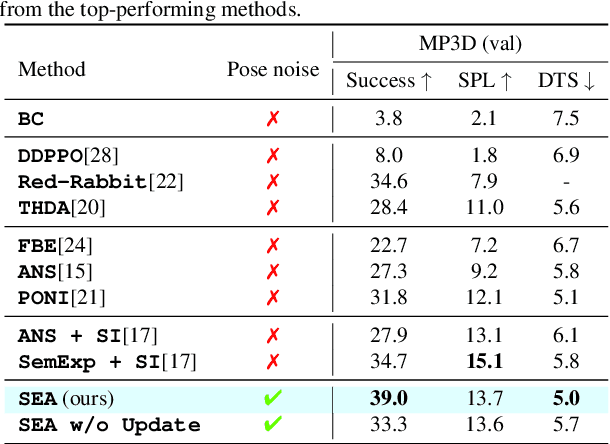
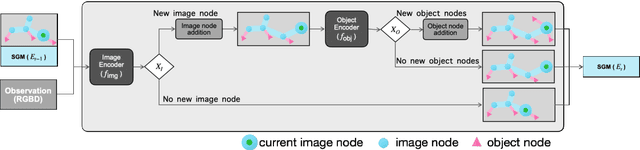
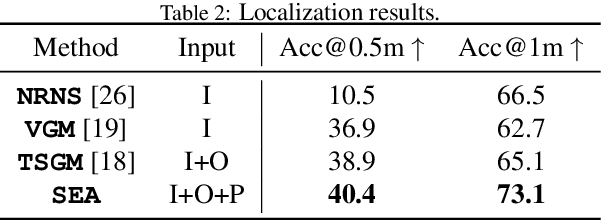
In this paper, we introduce the Semantic Environment Atlas (SEA), a novel mapping approach designed to enhance visual navigation capabilities of embodied agents. The SEA utilizes semantic graph maps that intricately delineate the relationships between places and objects, thereby enriching the navigational context. These maps are constructed from image observations and capture visual landmarks as sparsely encoded nodes within the environment. The SEA integrates multiple semantic maps from various environments, retaining a memory of place-object relationships, which proves invaluable for tasks such as visual localization and navigation. We developed navigation frameworks that effectively leverage the SEA, and we evaluated these frameworks through visual localization and object-goal navigation tasks. Our SEA-based localization framework significantly outperforms existing methods, accurately identifying locations from single query images. Experimental results in Habitat scenarios show that our method not only achieves a success rate of 39.0%, an improvement of 12.4% over the current state-of-the-art, but also maintains robustness under noisy odometry and actuation conditions, all while keeping computational costs low.
* 30 pages
Scale-Invariant Gradient Aggregation for Constrained Multi-Objective Reinforcement Learning
Mar 01, 2024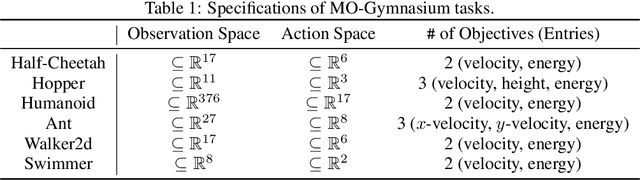
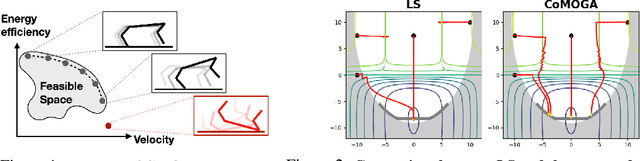
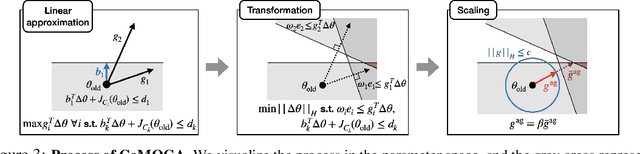

Multi-objective reinforcement learning (MORL) aims to find a set of Pareto optimal policies to cover various preferences. However, to apply MORL in real-world applications, it is important to find policies that are not only Pareto optimal but also satisfy pre-defined constraints for safety. To this end, we propose a constrained MORL (CMORL) algorithm called Constrained Multi-Objective Gradient Aggregator (CoMOGA). Recognizing the difficulty of handling multiple objectives and constraints concurrently, CoMOGA relaxes the original CMORL problem into a constrained optimization problem by transforming the objectives into additional constraints. This novel transformation process ensures that the converted constraints are invariant to the objective scales while having the same effect as the original objectives. We show that the proposed method converges to a local Pareto optimal policy while satisfying the predefined constraints. Empirical evaluations across various tasks show that the proposed method outperforms other baselines by consistently meeting constraints and demonstrating invariance to the objective scales.
Diffused Task-Agnostic Milestone Planner
Dec 06, 2023



Addressing decision-making problems using sequence modeling to predict future trajectories shows promising results in recent years. In this paper, we take a step further to leverage the sequence predictive method in wider areas such as long-term planning, vision-based control, and multi-task decision-making. To this end, we propose a method to utilize a diffusion-based generative sequence model to plan a series of milestones in a latent space and to have an agent to follow the milestones to accomplish a given task. The proposed method can learn control-relevant, low-dimensional latent representations of milestones, which makes it possible to efficiently perform long-term planning and vision-based control. Furthermore, our approach exploits generation flexibility of the diffusion model, which makes it possible to plan diverse trajectories for multi-task decision-making. We demonstrate the proposed method across offline reinforcement learning (RL) benchmarks and an visual manipulation environment. The results show that our approach outperforms offline RL methods in solving long-horizon, sparse-reward tasks and multi-task problems, while also achieving the state-of-the-art performance on the most challenging vision-based manipulation benchmark.