 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOBEST: Korean Balanced Evaluation of Significant Tasks
Apr 09, 2022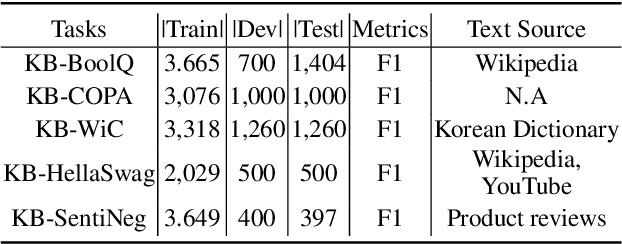



A well-formulated benchmark plays a critical role in spurring advancements in the natural language processing (NLP) field, as it allows objective and precise evaluation of diverse models. As modern language models (LMs) have become more elaborate and sophisticated, more difficult benchmarks that require linguistic knowledge and reasoning have been proposed. However, most of these benchmarks only support English, and great effort is necessary to construct benchmarks for other low resource languages. To this end, we propose a new benchmark named Korean balanced evaluation of significant tasks (KoBEST), which consists of five Korean-language downstream tasks. Professional Korean linguists designed the tasks that require advanced Korean linguistic knowledge. Moreover, our data is purely annotated by humans and thoroughly reviewed to guarantee high data quality. We also provide baseline models and human performance results. Our dataset is available on the Huggingface.
Understanding Dynamic Spatio-Temporal Contexts in Long Short-Term Memory for Road Traffic Speed Prediction
Dec 04, 2021



Reliable traffic flow prediction is crucial to creating intelligent transportation systems. Many big-data-based prediction approaches have been developed but they do not reflect complicated dynamic interactions between roads considering time and location. In this study, we propose a dynamically localised long short-term memory (LSTM) model that involves both spatial and temporal dependence between roads. To do so, we use a localised dynamic spatial weight matrix along with its dynamic variation. Moreover, the LSTM model can deal with sequential data with long dependency as well as complex non-linear features. Empirical results indicated superior prediction performances of the proposed model compared to two different baseline methods.
Accurate, yet inconsistent? Consistency Analysis on Language Understanding Models
Aug 15, 2021
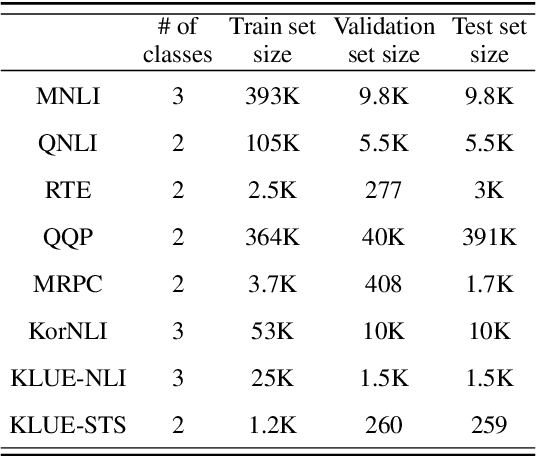
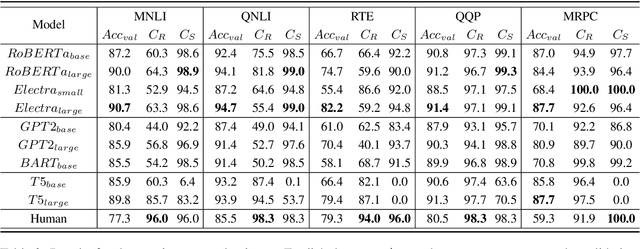
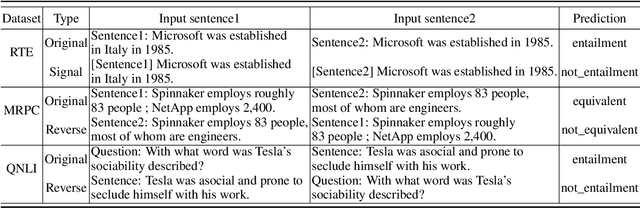
Consistency, which refers to the capability of generating the same predictions for semantically similar contexts, is a highly desirable property for a sound language understanding model. Although recent pretrained language models (PLMs) deliver outstanding performance in various downstream tasks, they should exhibit consistent behaviour provided the models truly understand language. In this paper, we propose a simple framework named consistency analysis on language understanding models (CALUM)} to evaluate the model's lower-bound consistency ability. Through experiments, we confirmed that current PLMs are prone to generate inconsistent predictions even for semantically identical inputs. We also observed that multi-task training with paraphrase identification tasks is of benefit to improve consistency, increasing the consistency by 13% on average.