 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Off-Policy Safe Reinforcement Learning Using Trust Region Conditional Value at Risk
Paper and Code
Dec 01, 2023
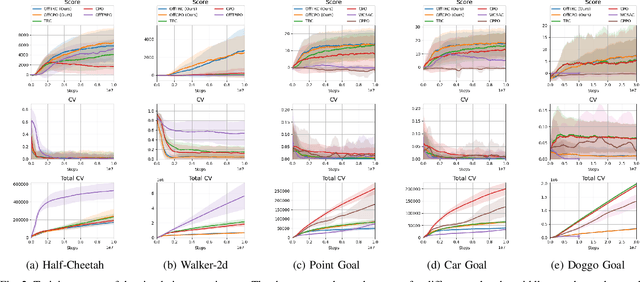
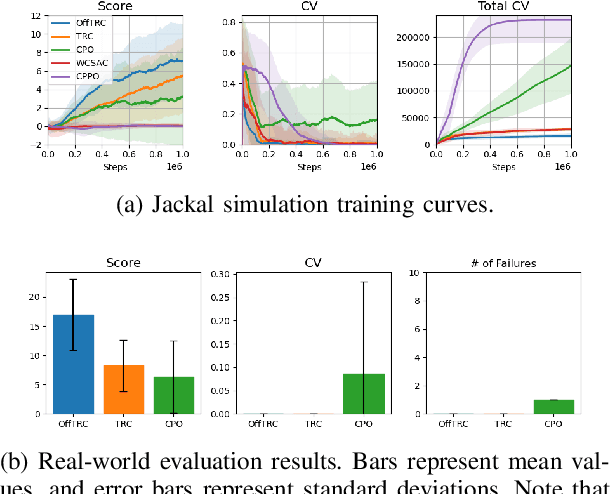
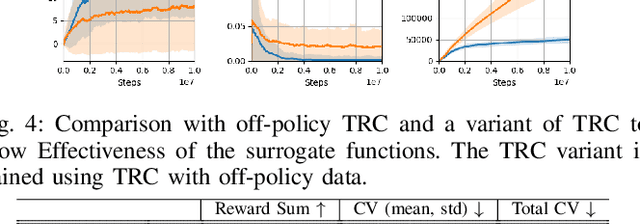
This paper aims to solve a safe reinforcement learning (RL) problem with risk measure-based constraints. As risk measures, such as conditional value at risk (CVaR), focus on the tail distribution of cost signals, constraining risk measures can effectively prevent a failure in the worst case. An on-policy safe RL method, called TRC, deals with a CVaR-constrained RL problem using a trust region method and can generate policies with almost zero constraint violations with high returns. However, to achieve outstanding performance in complex environments and satisfy safety constraints quickly, RL methods are required to be sample efficient. To this end, we propose an off-policy safe RL method with CVaR constraints, called off-policy TRC. If off-policy data from replay buffers is directly used to train TRC, the estimation error caused by the distributional shift results in performance degradation. To resolve this issue, we propose novel surrogate functions, in which the effect of the distributional shift can be reduced, and introduce an adaptive trust-region constraint to ensure a policy not to deviate far from replay buffers. The proposed method has been evaluated in simulation and real-world environments and satisfied safety constraints within a few steps while achieving high returns even in complex robotic tasks.