 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Open-Vocabulary Object Recognition via User-Guided Segmentation
Nov 23, 2024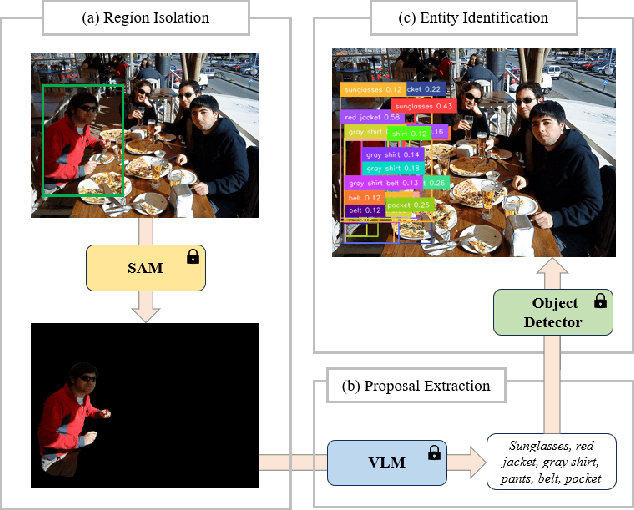



Recent advent of vision-based foundation models has enabled efficient and high-quality object detection at ease. Despite the success of previous studies, object detection models face limitations on capturing small components from holistic objects and taking user intention into account. To address these challenges, we propose a novel foundation model-based detection method called FOCUS: Fine-grained Open-Vocabulary Object ReCognition via User-Guided Segmentation. FOCUS merges the capabilities of vision foundation models to automate open-vocabulary object detection at flexible granularity and allow users to directly guide the detection process via natural language. It not only excels at identifying and locating granular constituent elements but also minimizes unnecessary user intervention yet grants them significant control. With FOCUS, users can make explainable requests to actively guide the detection process in the intended direction. Our results show that FOCUS effectively enhances the detection capabilities of baseline models and shows consistent performance across varying object types.
Topological Semantic Graph Memory for Image-Goal Navigation
Sep 17, 2022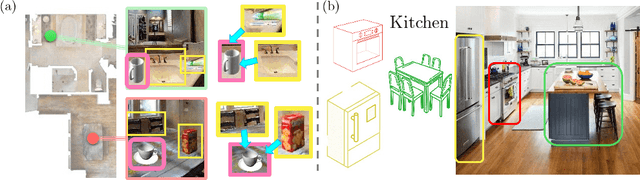
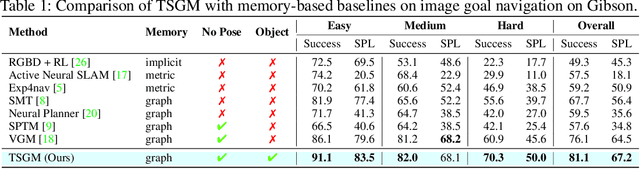
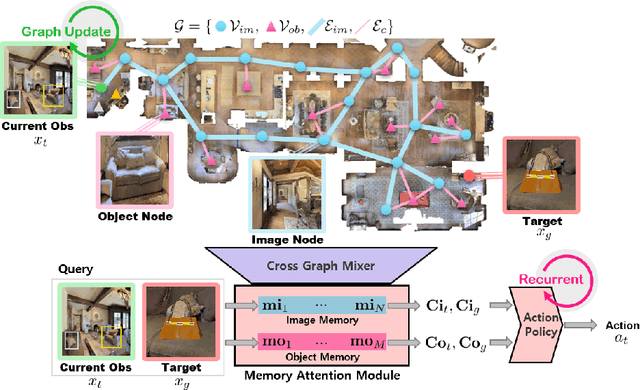
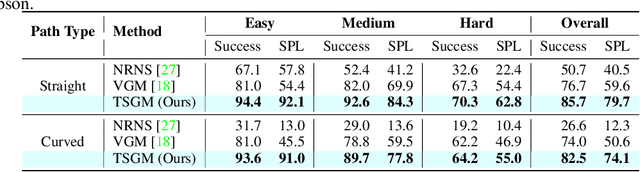
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. % The semantic graph memory is collected from a panoramic observation of an RGB-D camera without knowing the robot's pose. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
Text2Action: Generative Adversarial Synthesis from Language to Action
Oct 24, 2017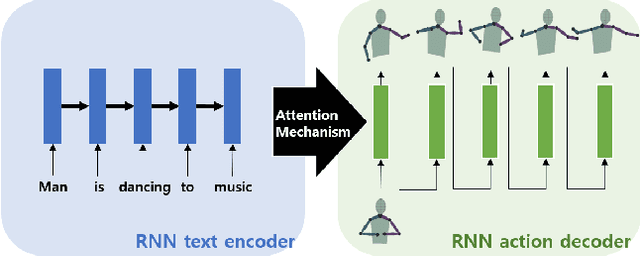



In this paper, we propose a generative model which learns the relationship between language and human action in order to generate a human action sequence given a sentence describing human behavior. The proposed generative model is a generative adversarial network (GAN), which is based on the sequence to sequence (SEQ2SEQ) model. Using the proposed generative network, we can synthesize various actions for a robot or a virtual agent using a text encoder recurrent neural network (RNN) and an action decoder RNN. The proposed generative network is trained from 29,770 pairs of actions and sentence annotations extracted from MSR-Video-to-Text (MSR-VTT), a large-scale video dataset. We demonstrate that the network can generate human-like actions which can be transferred to a Baxter robot, such that the robot performs an action based on a provided sentence. Results show that the proposed generative network correctly models the relationship between language and action and can generate a diverse set of actions from the same sentence.
Unsupervised Holistic Image Generation from Key Local Patches
Apr 03, 2017



We introduce a new problem of generating an image based on a small number of key local patches without any geometric prior. In this work, key local patches are defined as informative regions of the target object or scene. This is a challenging problem since it requires generating realistic images and predicting locations of parts at the same time. We construct adversarial networks to tackle this problem. A generator network generates a fake image as well as a mask based on the encoder-decoder framework. On the other hand, a discriminator network aims to detect fake images. The network is trained with three losses to consider spatial, appearance, and adversarial information. The spatial loss determines whether the locations of predicted parts are correct. Input patches are restored in the output image without much modification due to the appearance loss. The adversarial loss ensures output images are realistic. The proposed network is trained without supervisory signals since no labels of key parts are required. Experimental results on six datasets demonstrate that the proposed algorithm performs favorably on challenging objects and scenes.