 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Open-Vocabulary Object Recognition via User-Guided Segmentation
Paper and Code
Nov 23, 2024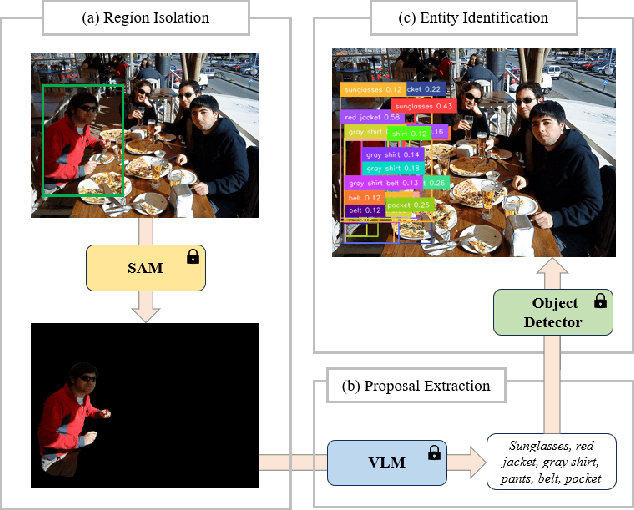



Recent advent of vision-based foundation models has enabled efficient and high-quality object detection at ease. Despite the success of previous studies, object detection models face limitations on capturing small components from holistic objects and taking user intention into account. To address these challenges, we propose a novel foundation model-based detection method called FOCUS: Fine-grained Open-Vocabulary Object ReCognition via User-Guided Segmentation. FOCUS merges the capabilities of vision foundation models to automate open-vocabulary object detection at flexible granularity and allow users to directly guide the detection process via natural language. It not only excels at identifying and locating granular constituent elements but also minimizes unnecessary user intervention yet grants them significant control. With FOCUS, users can make explainable requests to actively guide the detection process in the intended direction. Our results show that FOCUS effectively enhances the detection capabilities of baseline models and shows consistent performance across varying object types.