 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
Mar 11, 2026Transformer-based large language models (LLMs) rely on key-value (KV) caching to avoid redundant computation during autoregressive inference. While this mechanism greatly improves efficiency, the cache size grows linearly with the input sequence length, quickly becoming a bottleneck for long-context tasks. Existing solutions mitigate this problem by evicting prompt KV that are deemed unimportant, guided by estimated importance scores. Notably, a recent line of work proposes to improve eviction quality by "glimpsing into the future", in which a draft generator produces a surrogate future response approximating the target model's true response, and this surrogate is subsequently used to estimate the importance of cached KV more accurately. However, these approaches rely on computationally expensive draft generation, which introduces substantial prefilling overhead and limits their practicality in real-world deployment. To address this challenge, we propose LookaheadKV, a lightweight eviction framework that leverages the strength of surrogate future response without requiring explicit draft generation. LookaheadKV augments transformer layers with parameter-efficient modules trained to predict true importance scores with high accuracy. Our design ensures negligible runtime overhead comparable to existing inexpensive heuristics, while achieving accuracy superior to more costly approximation methods. Extensive experiments on long-context understanding benchmarks, across a wide range of models, demonstrate that our method not only outperforms recent competitive baselines in various long-context understanding tasks, but also reduces the eviction cost by up to 14.5x, leading to significantly faster time-to-first-token. Our code is available at https://github.com/SamsungLabs/LookaheadKV.
Fine-Grained Open-Vocabulary Object Recognition via User-Guided Segmentation
Nov 23, 2024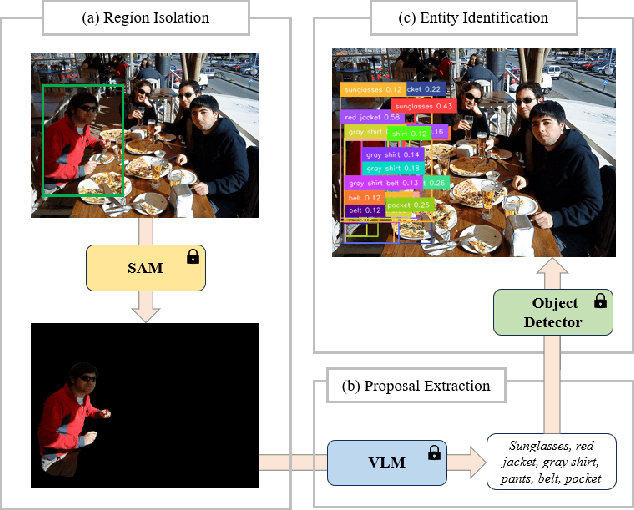



Recent advent of vision-based foundation models has enabled efficient and high-quality object detection at ease. Despite the success of previous studies, object detection models face limitations on capturing small components from holistic objects and taking user intention into account. To address these challenges, we propose a novel foundation model-based detection method called FOCUS: Fine-grained Open-Vocabulary Object ReCognition via User-Guided Segmentation. FOCUS merges the capabilities of vision foundation models to automate open-vocabulary object detection at flexible granularity and allow users to directly guide the detection process via natural language. It not only excels at identifying and locating granular constituent elements but also minimizes unnecessary user intervention yet grants them significant control. With FOCUS, users can make explainable requests to actively guide the detection process in the intended direction. Our results show that FOCUS effectively enhances the detection capabilities of baseline models and shows consistent performance across varying object types.
Visual Contexts Clarify Ambiguous Expressions: A Benchmark Dataset
Nov 21, 2024



The ability to perform complex reasoning across multimodal inputs is essential for models to effectively interact with humans in real-world scenarios. Advancements in vision-language models have significantly improved performance on tasks that require processing explicit and direct textual inputs, such as Visual Question Answering (VQA) and Visual Grounding (VG). However, less attention has been given to improving the model capabilities to comprehend nuanced and ambiguous forms of communication. This presents a critical challenge, as human language in real-world interactions often convey hidden intentions that rely on context for accurate interpretation. To address this gap, we propose VAGUE, a multimodal benchmark comprising 3.9K indirect human utterances paired with corresponding scenes. Additionally, we contribute a model-based pipeline for generating prompt-solution pairs from input images. Our work aims to delve deeper into the ability of models to understand indirect communication and seek to contribute to the development of models capable of more refined and human-like interactions. Extensive evaluation on multiple VLMs reveals that mainstream models still struggle with indirect communication when required to perform complex linguistic and visual reasoning. We release our code and data at https://github.com/Hazel-Heejeong-Nam/VAGUE.git.
Solution for SMART-101 Challenge of CVPR Multi-modal Algorithmic Reasoning Task 2024
Jun 10, 2024



In this paper, the solution of HYU MLLAB KT Team to the Multimodal Algorithmic Reasoning Task: SMART-101 CVPR 2024 Challenge is presented. Beyond conventional visual question-answering problems, the SMART-101 challenge aims to achieve human-level multimodal understanding by tackling complex visio-linguistic puzzles designed for children in the 6-8 age group. To solve this problem, we suggest two main ideas. First, to utilize the reasoning ability of a large-scale language model (LLM), the given visual cues (images) are grounded in the text modality. For this purpose, we generate highly detailed text captions that describe the context of the image and use these captions as input for the LLM. Second, due to the nature of puzzle images, which often contain various geometric visual patterns, we utilize an object detection algorithm to ensure these patterns are not overlooked in the captioning process. We employed the SAM algorithm, which can detect various-size objects, to capture the visual features of these geometric patterns and used this information as input for the LLM. Under the puzzle split configuration, we achieved an option selection accuracy Oacc of 29.5 on the test set and a weighted option selection accuracy (WOSA) of 27.1 on the challenge set.
Chain-of-Feedback: Mitigating the Effects of Inconsistency in Responses
Feb 05, 2024Large Language Models (LLMs) frequently suffer from knowledge-intensive questions, often being inconsistent by providing different outputs despite given the same input. The response quality worsens when the user expresses a firm opposing stance which causes the LLMs to adjust its response despite the correct initial one. These behaviors decrease the reliability and validity of the responses provided by these models. In this paper, we attempt to 1) raise awareness of the inherent risks that follow from overly relying on AI agents like ChatGPT by showing how Chain-of-Feedback (CoF) triggers LLMs to deviate more from the actual answer and 2) suggest a novel prompting method, Recursive Chain of Feedback (R-CoF), that we are conducting further study. The CoF system takes in an open-ended multi-step question. Then, we repetitively provide meaningless feedback requesting another attempt. Our preliminary experiments show that such feedback only decreases the quality of the response. On the other hand, to mitigate the effects of the aforementioned inconsistencies, we present a novel method of recursively revising the initial incorrect reasoning provided by the LLM by repetitively breaking down each incorrect step into smaller individual problems.
Goal Driven Discovery of Distributional Differences via Language Descriptions
Feb 28, 2023
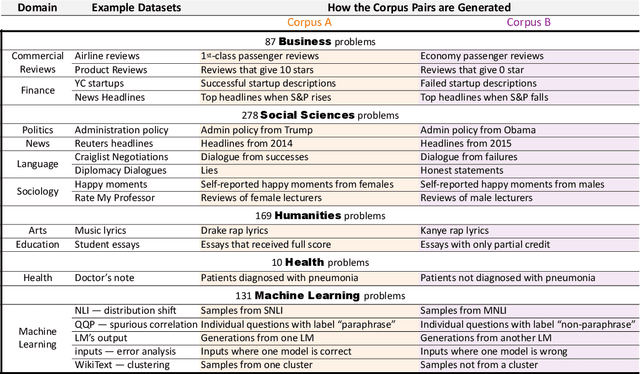


Mining large corpora can generate useful discoveries but is time-consuming for humans. We formulate a new task, D5, that automatically discovers differences between two large corpora in a goal-driven way. The task input is a problem comprising a research goal "$\textit{comparing the side effects of drug A and drug B}$" and a corpus pair (two large collections of patients' self-reported reactions after taking each drug). The output is a language description (discovery) of how these corpora differ (patients taking drug A "$\textit{mention feelings of paranoia}$" more often). We build a D5 system, and to quantitatively measure its performance, we 1) contribute a meta-dataset, OpenD5, aggregating 675 open-ended problems ranging across business, social sciences, humanities, machine learning, and health, and 2) propose a set of unified evaluation metrics: validity, relevance, novelty, and significance. With the dataset and the unified metrics, we confirm that language models can use the goals to propose more relevant, novel, and significant candidate discoveries. Finally, our system produces discoveries previously unknown to the authors on a wide range of applications in OpenD5, including temporal and demographic differences in discussion topics, political stances and stereotypes in speech, insights in commercial reviews, and error patterns in NLP models.