 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal Driven Discovery of Distributional Differences via Language Descriptions
Paper and Code

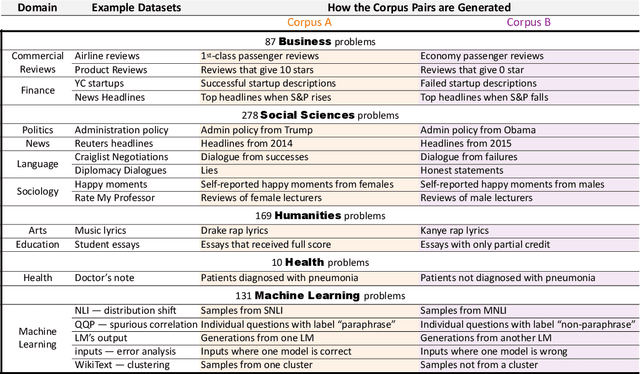


Mining large corpora can generate useful discoveries but is time-consuming for humans. We formulate a new task, D5, that automatically discovers differences between two large corpora in a goal-driven way. The task input is a problem comprising a research goal "$\textit{comparing the side effects of drug A and drug B}$" and a corpus pair (two large collections of patients' self-reported reactions after taking each drug). The output is a language description (discovery) of how these corpora differ (patients taking drug A "$\textit{mention feelings of paranoia}$" more often). We build a D5 system, and to quantitatively measure its performance, we 1) contribute a meta-dataset, OpenD5, aggregating 675 open-ended problems ranging across business, social sciences, humanities, machine learning, and health, and 2) propose a set of unified evaluation metrics: validity, relevance, novelty, and significance. With the dataset and the unified metrics, we confirm that language models can use the goals to propose more relevant, novel, and significant candidate discoveries. Finally, our system produces discoveries previously unknown to the authors on a wide range of applications in OpenD5, including temporal and demographic differences in discussion topics, political stances and stereotypes in speech, insights in commercial reviews, and error patterns in NLP models.