 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTidiness Score-Guided Monte Carlo Tree Search for Visual Tabletop Rearrangement
Feb 24, 2025In this paper, we present the tidiness score-guided Monte Carlo tree search (TSMCTS), a novel framework designed to address the tabletop tidying up problem using only an RGB-D camera. We address two major problems for tabletop tidying up problem: (1) the lack of public datasets and benchmarks, and (2) the difficulty of specifying the goal configuration of unseen objects. We address the former by presenting the tabletop tidying up (TTU) dataset, a structured dataset collected in simulation. Using this dataset, we train a vision-based discriminator capable of predicting the tidiness score. This discriminator can consistently evaluate the degree of tidiness across unseen configurations, including real-world scenes. Addressing the second problem, we employ Monte Carlo tree search (MCTS) to find tidying trajectories without specifying explicit goals. Instead of providing specific goals, we demonstrate that our MCTS-based planner can find diverse tidied configurations using the tidiness score as a guidance. Consequently, we propose TSMCTS, which integrates a tidiness discriminator with an MCTS-based tidying planner to find optimal tidied arrangements. TSMCTS has successfully demonstrated its capability across various environments, including coffee tables, dining tables, office desks, and bathrooms. The TTU dataset is available at: https://github.com/rllab-snu/TTU-Dataset.
May the Dance be with You: Dance Generation Framework for Non-Humanoids
May 30, 2024We hypothesize dance as a motion that forms a visual rhythm from music, where the visual rhythm can be perceived from an optical flow. If an agent can recognize the relationship between visual rhythm and music, it will be able to dance by generating a motion to create a visual rhythm that matches the music. Based on this, we propose a framework for any kind of non-humanoid agents to learn how to dance from human videos. Our framework works in two processes: (1) training a reward model which perceives the relationship between optical flow (visual rhythm) and music from human dance videos, (2) training the non-humanoid dancer based on that reward model, and reinforcement learning. Our reward model consists of two feature encoders for optical flow and music. They are trained based on contrastive learning which makes the higher similarity between concurrent optical flow and music features. With this reward model, the agent learns dancing by getting a higher reward when its action creates an optical flow whose feature has a higher similarity with the given music feature. Experiment results show that generated dance motion can align with the music beat properly, and user study result indicates that our framework is more preferred by humans compared to the baselines. To the best of our knowledge, our work of non-humanoid agents which learn dance from human videos is unprecedented. An example video can be found at https://youtu.be/dOUPvo-O3QY.
Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
Apr 05, 2024In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis
Aug 14, 2023The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called UNIMASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our UNIMASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods. More information can be found on the project website https://sites.google.com/view/estevevallsmascaro/publications/unimask-m.
Human-Object Interaction Prediction in Videos through Gaze Following
Jun 06, 2023Understanding the human-object interactions (HOIs) from a video is essential to fully comprehend a visual scene. This line of research has been addressed by detecting HOIs from images and lately from videos. However, the video-based HOI anticipation task in the third-person view remains understudied. In this paper, we design a framework to detect current HOIs and anticipate future HOIs in videos. We propose to leverage human gaze information since people often fixate on an object before interacting with it. These gaze features together with the scene contexts and the visual appearances of human-object pairs are fused through a spatio-temporal transformer. To evaluate the model in the HOI anticipation task in a multi-person scenario, we propose a set of person-wise multi-label metrics. Our model is trained and validated on the VidHOI dataset, which contains videos capturing daily life and is currently the largest video HOI dataset. Experimental results in the HOI detection task show that our approach improves the baseline by a great margin of 36.3% relatively. Moreover, we conduct an extensive ablation study to demonstrate the effectiveness of our modifications and extensions to the spatio-temporal transformer. Our code is publicly available on https://github.com/nizhf/hoi-prediction-gaze-transformer.
Can We Use Diffusion Probabilistic Models for 3D Motion Prediction?
Feb 28, 2023After many researchers observed fruitfulness from the recent diffusion probabilistic model, its effectiveness in image generation is actively studied these days. In this paper, our objective is to evaluate the potential of diffusion probabilistic models for 3D human motion-related tasks. To this end, this paper presents a study of employing diffusion probabilistic models to predict future 3D human motion(s) from the previously observed motion. Based on the Human 3.6M and HumanEva-I datasets, our results show that diffusion probabilistic models are competitive for both single (deterministic) and multiple (stochastic) 3D motion prediction tasks, after finishing a single training process. In addition, we find out that diffusion probabilistic models can offer an attractive compromise, since they can strike the right balance between the likelihood and diversity of the predicted future motions. Our code is publicly available on the project website: https://sites.google.com/view/diffusion-motion-prediction.
Robust Human Motion Forecasting using Transformer-based Model
Feb 16, 2023Comprehending human motion is a fundamental challenge for developing Human-Robot Collaborative applications. Computer vision researchers have addressed this field by only focusing on reducing error in predictions, but not taking into account the requirements to facilitate its implementation in robots. In this paper, we propose a new model based on Transformer that simultaneously deals with the real time 3D human motion forecasting in the short and long term. Our 2-Channel Transformer (2CH-TR) is able to efficiently exploit the spatio-temporal information of a shortly observed sequence (400ms) and generates a competitive accuracy against the current state-of-the-art. 2CH-TR stands out for the efficient performance of the Transformer, being lighter and faster than its competitors. In addition, our model is tested in conditions where the human motion is severely occluded, demonstrating its robustness in reconstructing and predicting 3D human motion in a highly noisy environment. Our experiment results show that the proposed 2CH-TR outperforms the ST-Transformer, which is another state-of-the-art model based on the Transformer, in terms of reconstruction and prediction under the same conditions of input prefix. Our model reduces in 8.89% the mean squared error of ST-Transformer in short-term prediction, and 2.57% in long-term prediction in Human3.6M dataset with 400ms input prefix.
* This paper has been already accepted to the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2022)
Intention-Conditioned Long-Term Human Egocentric Action Forecasting @ EGO4D Challenge 2022
Jul 25, 2022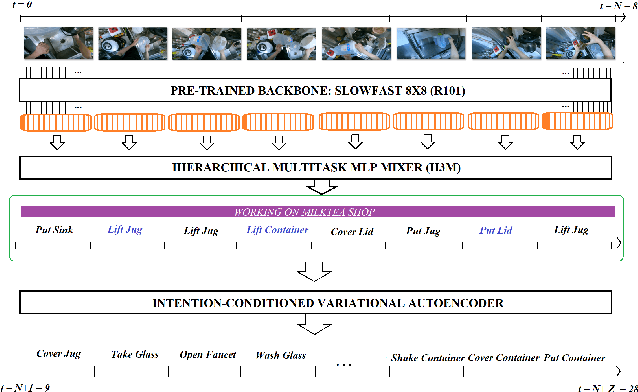
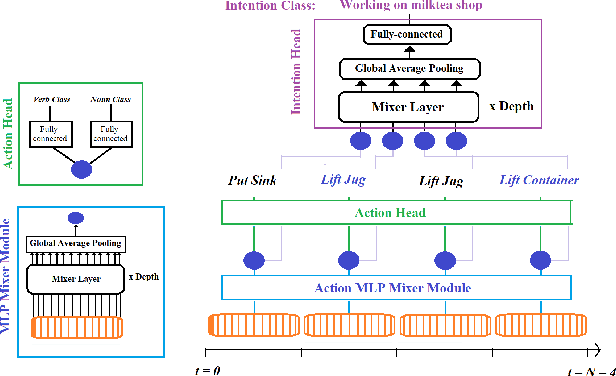
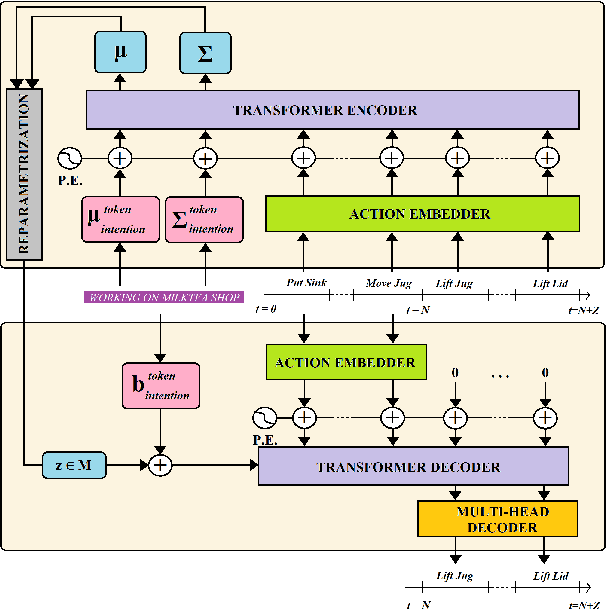
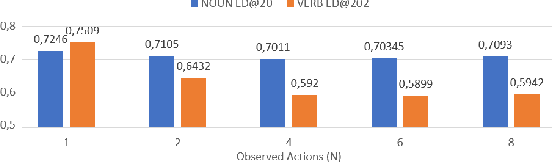
To anticipate how a human would act in the future, it is essential to understand the human intention since it guides the human towards a certain goal. In this paper, we propose a hierarchical architecture which assumes a sequence of human action (low-level) can be driven from the human intention (high-level). Based on this, we deal with Long-Term Action Anticipation task in egocentric videos. Our framework first extracts two level of human information over the N observed videos human actions through a Hierarchical Multi-task MLP Mixer (H3M). Then, we condition the uncertainty of the future through an Intention-Conditioned Variational Auto-Encoder (I-CVAE) that generates K stable predictions of the next Z=20 actions that the observed human might perform. By leveraging human intention as high-level information, we claim that our model is able to anticipate more time-consistent actions in the long-term, thus improving the results over baseline methods in EGO4D Challenge. This work ranked first in the EGO4D LTA Challenge by providing more plausible anticipated sequences, improving the anticipation of nouns and overall actions. The code is available at https://github.com/Evm7/ego4dlta-icvae.
Self-Supervised Motion Retargeting with Safety Guarantee
Mar 11, 2021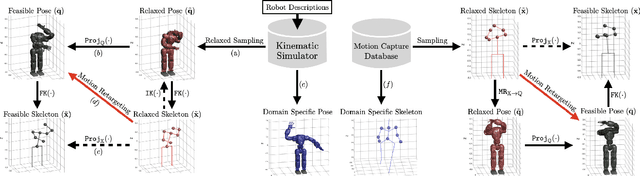
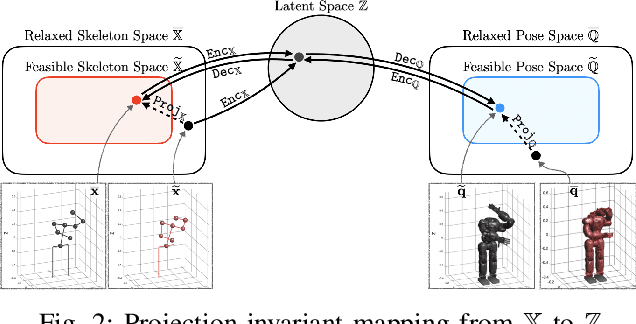

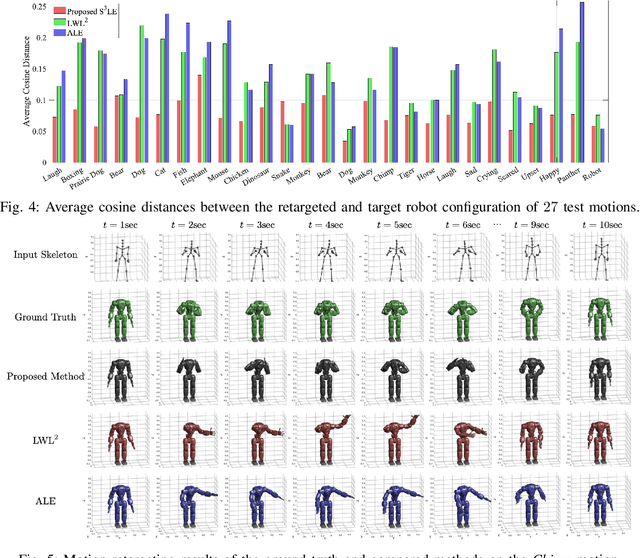
In this paper, we present self-supervised shared latent embedding (S3LE), a data-driven motion retargeting method that enables the generation of natural motions in humanoid robots from motion capture data or RGB videos. While it requires paired data consisting of human poses and their corresponding robot configurations, it significantly alleviates the necessity of time-consuming data-collection via novel paired data generating processes. Our self-supervised learning procedure consists of two steps: automatically generating paired data to bootstrap the motion retargeting, and learning a projection-invariant mapping to handle the different expressivity of humans and humanoid robots. Furthermore, our method guarantees that the generated robot pose is collision-free and satisfies position limits by utilizing nonparametric regression in the shared latent space. We demonstrate that our method can generate expressive robotic motions from both the CMU motion capture database and YouTube videos.
Visually Grounding Instruction for History-Dependent Manipulation
Dec 16, 2020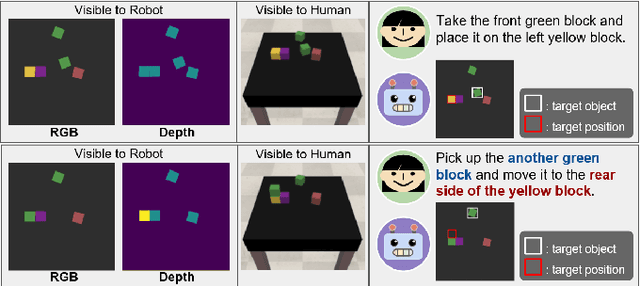


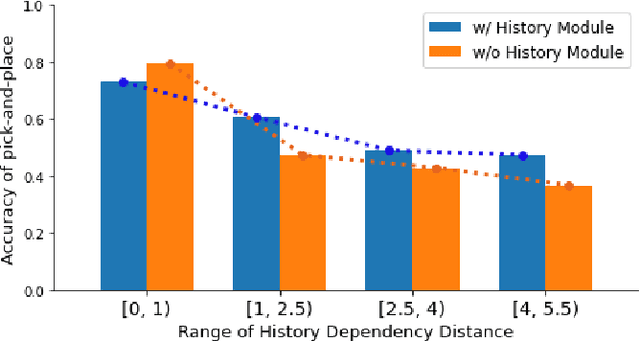
This paper emphasizes the importance of robot's ability to refer its task history, when it executes a series of pick-and-place manipulations by following text instructions given one by one. The advantage of referring the manipulation history can be categorized into two folds: (1) the instructions omitting details or using co-referential expressions can be interpreted, and (2) the visual information of objects occluded by previous manipulations can be inferred. For this challenge, we introduce the task of history-dependent manipulation which is to visually ground a series of text instructions for proper manipulations depending on the task history. We also suggest a relevant dataset and a methodology based on the deep neural network, and show that our network trained with a synthetic dataset can be applied to the real world based on images transferred into synthetic-style based on the CycleGAN.