 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTidiness Score-Guided Monte Carlo Tree Search for Visual Tabletop Rearrangement
Feb 24, 2025


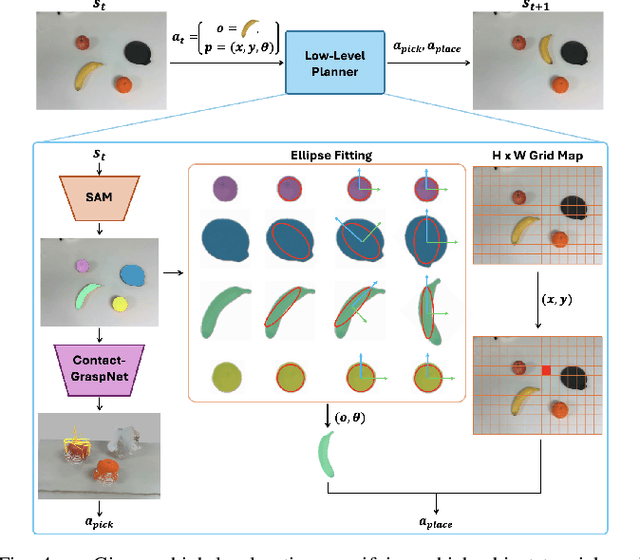
In this paper, we present the tidiness score-guided Monte Carlo tree search (TSMCTS), a novel framework designed to address the tabletop tidying up problem using only an RGB-D camera. We address two major problems for tabletop tidying up problem: (1) the lack of public datasets and benchmarks, and (2) the difficulty of specifying the goal configuration of unseen objects. We address the former by presenting the tabletop tidying up (TTU) dataset, a structured dataset collected in simulation. Using this dataset, we train a vision-based discriminator capable of predicting the tidiness score. This discriminator can consistently evaluate the degree of tidiness across unseen configurations, including real-world scenes. Addressing the second problem, we employ Monte Carlo tree search (MCTS) to find tidying trajectories without specifying explicit goals. Instead of providing specific goals, we demonstrate that our MCTS-based planner can find diverse tidied configurations using the tidiness score as a guidance. Consequently, we propose TSMCTS, which integrates a tidiness discriminator with an MCTS-based tidying planner to find optimal tidied arrangements. TSMCTS has successfully demonstrated its capability across various environments, including coffee tables, dining tables, office desks, and bathrooms. The TTU dataset is available at: https://github.com/rllab-snu/TTU-Dataset.
Semi-Supervised Imitation Learning with Mixed Qualities of Demonstrations for Autonomous Driving
Sep 23, 2021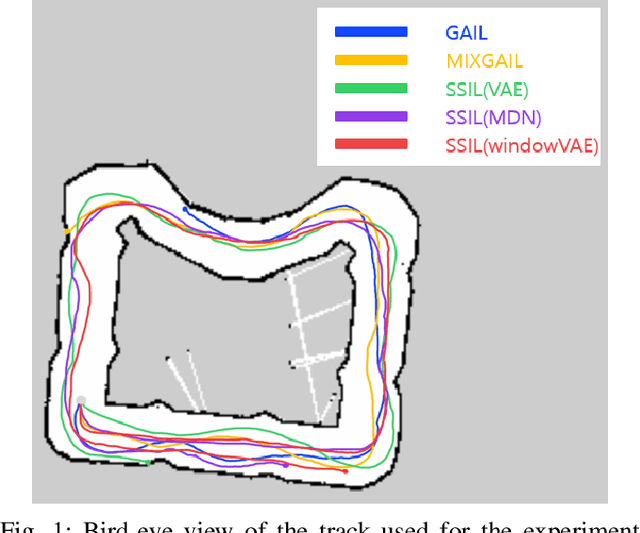

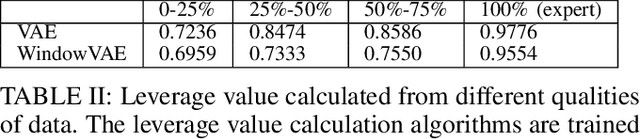
In this paper, we consider the problem of autonomous driving using imitation learning in a semi-supervised manner. In particular, both labeled and unlabeled demonstrations are leveraged during training by estimating the quality of each unlabeled demonstration. If the provided demonstrations are corrupted and have a low signal-to-noise ratio, the performance of the imitation learning agent can be degraded significantly. To mitigate this problem, we propose a method called semi-supervised imitation learning (SSIL). SSIL first learns how to discriminate and evaluate each state-action pair's reliability in unlabeled demonstrations by assigning higher reliability values to demonstrations similar to labeled expert demonstrations. This reliability value is called leverage. After this discrimination process, both labeled and unlabeled demonstrations with estimated leverage values are utilized while training the policy in a semi-supervised manner. The experimental results demonstrate the validity of the proposed algorithm using unlabeled trajectories with mixed qualities. Moreover, the hardware experiments using an RC car are conducted to show that the proposed method can be applied to real-world applications.
Towards Defensive Autonomous Driving: Collecting and Probing Driving Demonstrations of Mixed Qualities
Sep 18, 2021
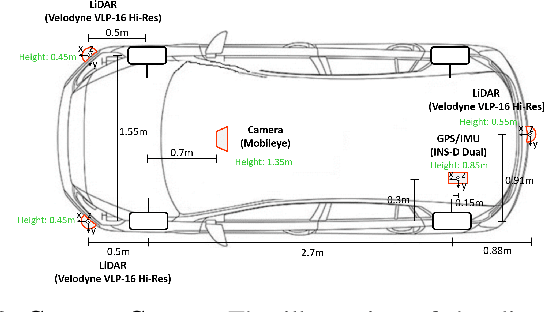

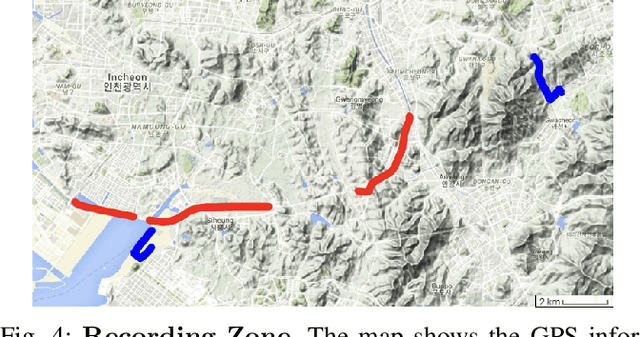
Designing or learning an autonomous driving policy is undoubtedly a challenging task as the policy has to maintain its safety in all corner cases. In order to secure safety in autonomous driving, the ability to detect hazardous situations, which can be seen as an out-of-distribution (OOD) detection problem, becomes crucial. However, most conventional datasets only provide expert driving demonstrations, although some non-expert or uncommon driving behavior data are needed to implement a safety guaranteed autonomous driving platform. To this end, we present a novel dataset called the R3 Driving Dataset, composed of driving data with different qualities. The dataset categorizes abnormal driving behaviors into eight categories and 369 different detailed situations. The situations include dangerous lane changes and near-collision situations. To further enlighten how these abnormal driving behaviors can be detected, we utilize different uncertainty estimation and anomaly detection methods to the proposed dataset. From the results of the proposed experiment, it can be inferred that by using both uncertainty estimation and anomaly detection, most of the abnormal cases in the proposed dataset can be discriminated. The dataset of this paper can be downloaded from https://rllab-snu.github.io/projects/R3-Driving-Dataset/doc.html.