 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Learning Joint Representation of Human Motion and Language
Oct 27, 2022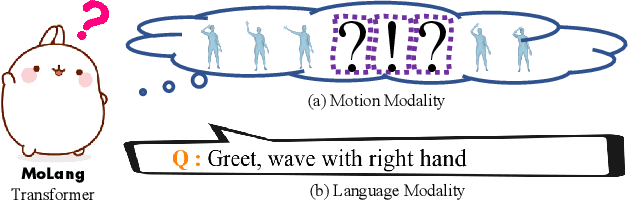
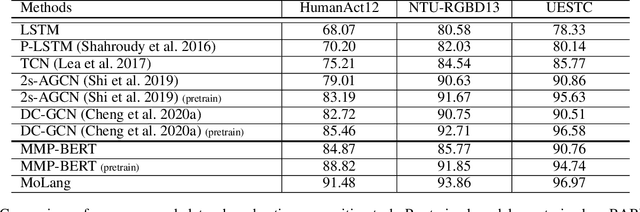
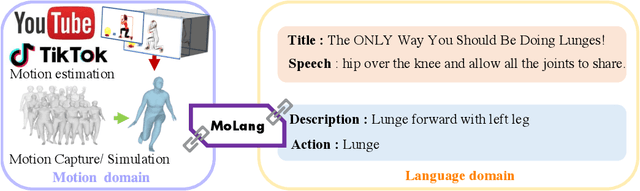
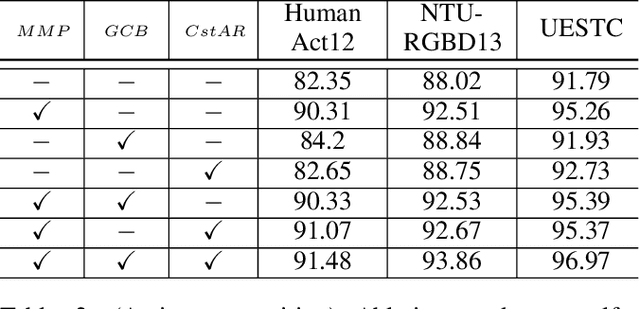
In this work, we present MoLang (a Motion-Language connecting model) for learning joint representation of human motion and language, leveraging both unpaired and paired datasets of motion and language modalities. To this end, we propose a motion-language model with contrastive learning, empowering our model to learn better generalizable representations of the human motion domain. Empirical results show that our model learns strong representations of human motion data through navigating language modality. Our proposed method is able to perform both action recognition and motion retrieval tasks with a single model where it outperforms state-of-the-art approaches on a number of action recognition benchmarks.
Conditional Motion In-betweening
Feb 09, 2022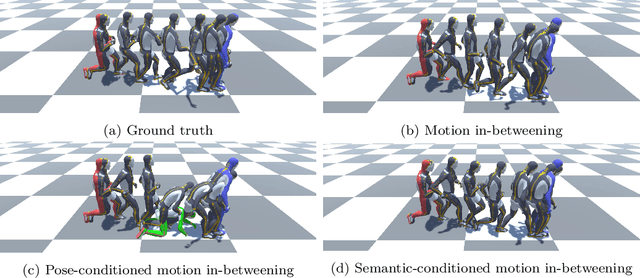
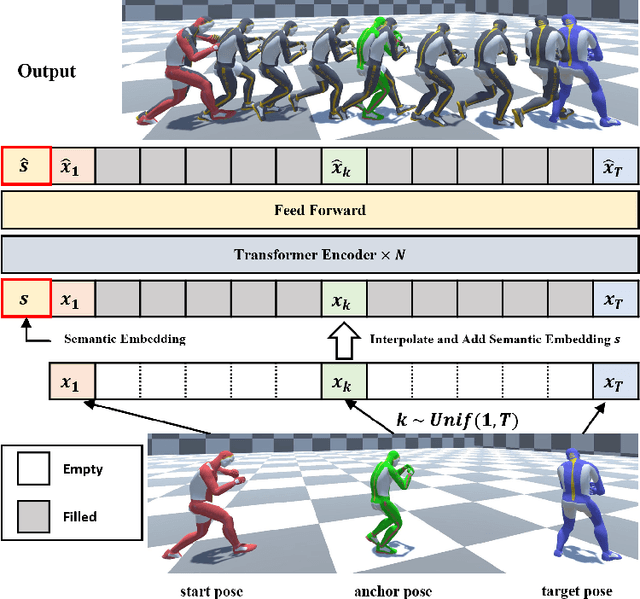
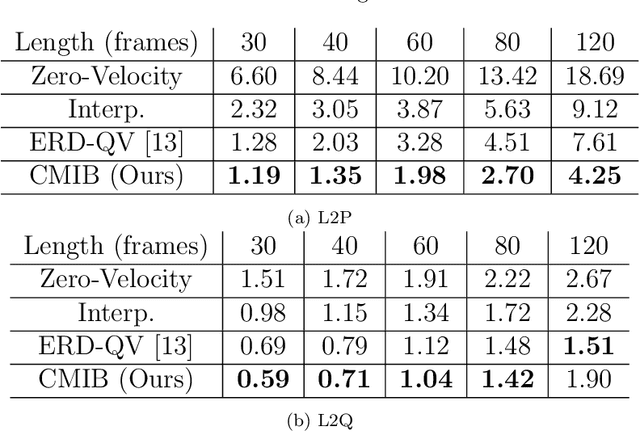
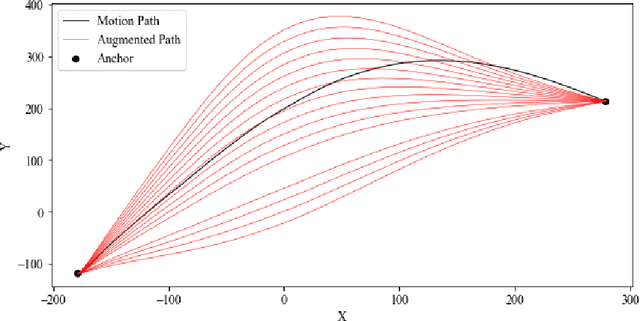
Motion in-betweening (MIB) is a process of generating intermediate skeletal movement between the given start and target poses while preserving the naturalness of the motion, such as periodic footstep motion while walking. Although state-of-the-art MIB methods are capable of producing plausible motions given sparse key-poses, they often lack the controllability to generate motions satisfying the semantic contexts required in practical applications. We focus on the method that can handle pose or semantic conditioned MIB tasks using a unified model. We also present a motion augmentation method to improve the quality of pose-conditioned motion generation via defining a distribution over smooth trajectories. Our proposed method outperforms the existing state-of-the-art MIB method in pose prediction errors while providing additional controllability.
Elucidating Noisy Data via Uncertainty-Aware Robust Learning
Nov 02, 2021
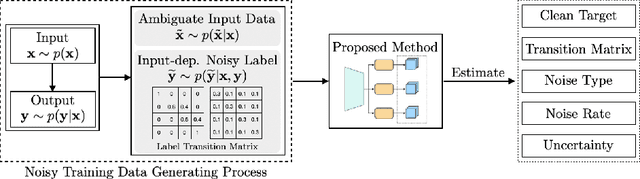
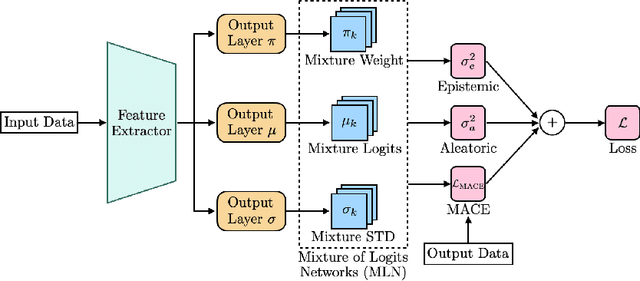
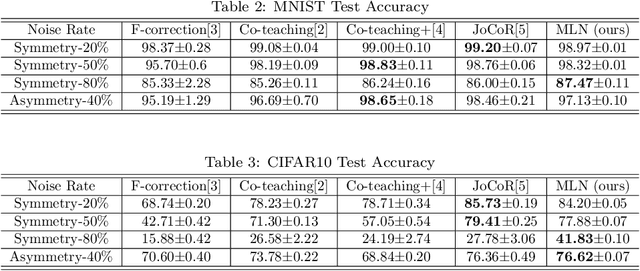
Robust learning methods aim to learn a clean target distribution from noisy and corrupted training data where a specific corruption pattern is often assumed a priori. Our proposed method can not only successfully learn the clean target distribution from a dirty dataset but also can estimate the underlying noise pattern. To this end, we leverage a mixture-of-experts model that can distinguish two different types of predictive uncertainty, aleatoric and epistemic uncertainty. We show that the ability to estimate the uncertainty plays a significant role in elucidating the corruption patterns as these two objectives are tightly intertwined. We also present a novel validation scheme for evaluating the performance of the corruption pattern estimation. Our proposed method is extensively assessed in terms of both robustness and corruption pattern estimation through a number of domains, including computer vision and natural language processing.
Semi-Supervised Imitation Learning with Mixed Qualities of Demonstrations for Autonomous Driving
Sep 23, 2021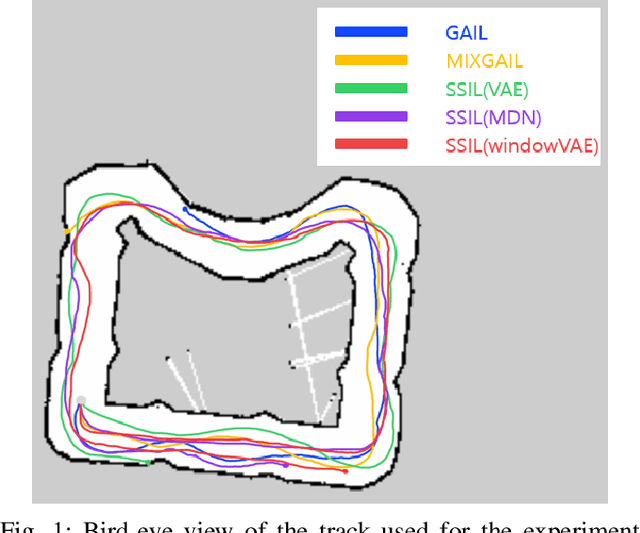
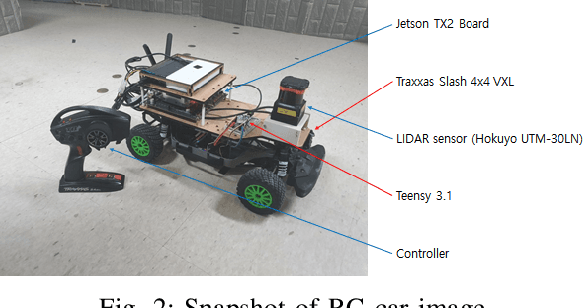

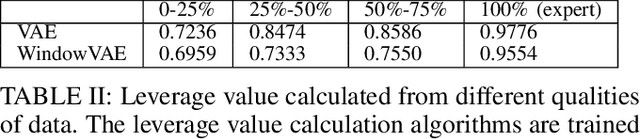
In this paper, we consider the problem of autonomous driving using imitation learning in a semi-supervised manner. In particular, both labeled and unlabeled demonstrations are leveraged during training by estimating the quality of each unlabeled demonstration. If the provided demonstrations are corrupted and have a low signal-to-noise ratio, the performance of the imitation learning agent can be degraded significantly. To mitigate this problem, we propose a method called semi-supervised imitation learning (SSIL). SSIL first learns how to discriminate and evaluate each state-action pair's reliability in unlabeled demonstrations by assigning higher reliability values to demonstrations similar to labeled expert demonstrations. This reliability value is called leverage. After this discrimination process, both labeled and unlabeled demonstrations with estimated leverage values are utilized while training the policy in a semi-supervised manner. The experimental results demonstrate the validity of the proposed algorithm using unlabeled trajectories with mixed qualities. Moreover, the hardware experiments using an RC car are conducted to show that the proposed method can be applied to real-world applications.