Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Joint Representation of Human Motion and Language
Paper and Code
Oct 27, 2022
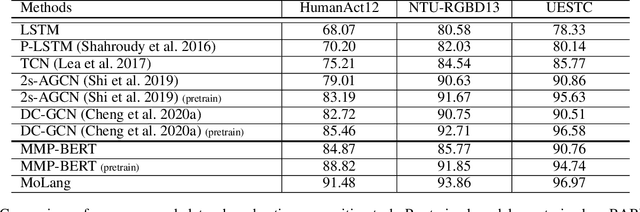
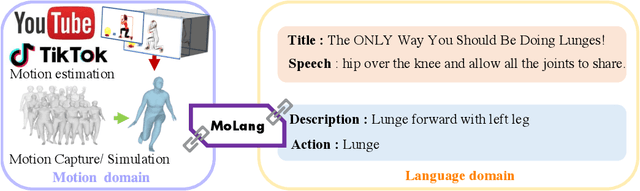
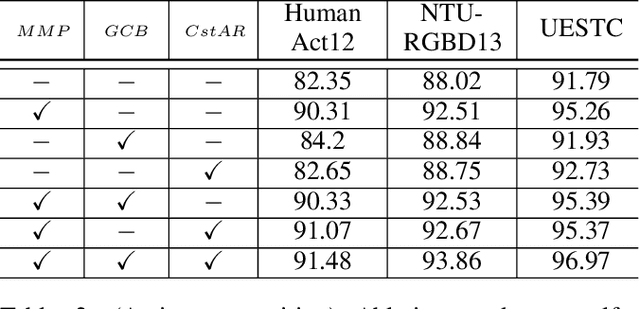
In this work, we present MoLang (a Motion-Language connecting model) for learning joint representation of human motion and language, leveraging both unpaired and paired datasets of motion and language modalities. To this end, we propose a motion-language model with contrastive learning, empowering our model to learn better generalizable representations of the human motion domain. Empirical results show that our model learns strong representations of human motion data through navigating language modality. Our proposed method is able to perform both action recognition and motion retrieval tasks with a single model where it outperforms state-of-the-art approaches on a number of action recognition benchmarks.
View paper on