 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntention-Conditioned Long-Term Human Egocentric Action Forecasting @ EGO4D Challenge 2022
Paper and Code
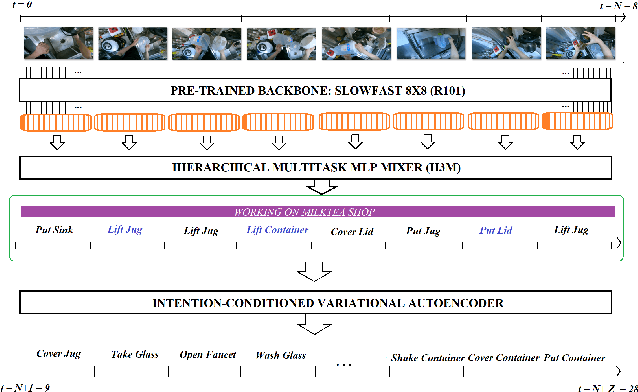
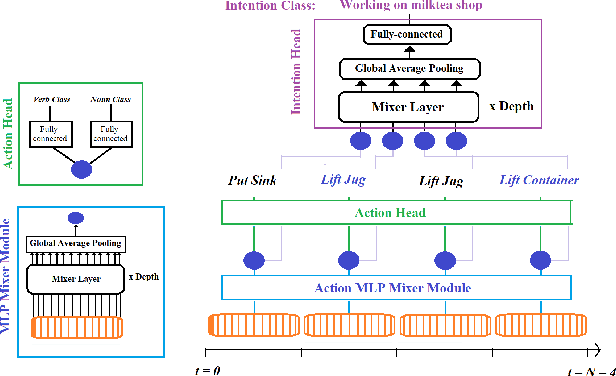
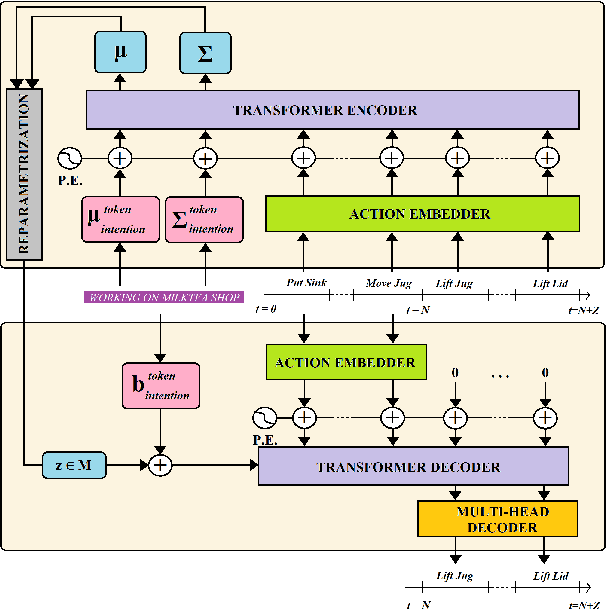
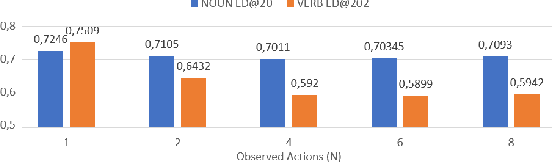
To anticipate how a human would act in the future, it is essential to understand the human intention since it guides the human towards a certain goal. In this paper, we propose a hierarchical architecture which assumes a sequence of human action (low-level) can be driven from the human intention (high-level). Based on this, we deal with Long-Term Action Anticipation task in egocentric videos. Our framework first extracts two level of human information over the N observed videos human actions through a Hierarchical Multi-task MLP Mixer (H3M). Then, we condition the uncertainty of the future through an Intention-Conditioned Variational Auto-Encoder (I-CVAE) that generates K stable predictions of the next Z=20 actions that the observed human might perform. By leveraging human intention as high-level information, we claim that our model is able to anticipate more time-consistent actions in the long-term, thus improving the results over baseline methods in EGO4D Challenge. This work ranked first in the EGO4D LTA Challenge by providing more plausible anticipated sequences, improving the anticipation of nouns and overall actions. The code is available at https://github.com/Evm7/ego4dlta-icvae.