 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Rating-Based Reinforcement Learning to Effectively Leverage Feedback from Large Vision-Language Models
Jun 15, 2025



Designing effective reward functions remains a fundamental challenge in reinforcement learning (RL), as it often requires extensive human effort and domain expertise. While RL from human feedback has been successful in aligning agents with human intent, acquiring high-quality feedback is costly and labor-intensive, limiting its scalability. Recent advancements in foundation models present a promising alternative--leveraging AI-generated feedback to reduce reliance on human supervision in reward learning. Building on this paradigm, we introduce ERL-VLM, an enhanced rating-based RL method that effectively learns reward functions from AI feedback. Unlike prior methods that rely on pairwise comparisons, ERL-VLM queries large vision-language models (VLMs) for absolute ratings of individual trajectories, enabling more expressive feedback and improved sample efficiency. Additionally, we propose key enhancements to rating-based RL, addressing instability issues caused by data imbalance and noisy labels. Through extensive experiments across both low-level and high-level control tasks, we demonstrate that ERL-VLM significantly outperforms existing VLM-based reward generation methods. Our results demonstrate the potential of AI feedback for scaling RL with minimal human intervention, paving the way for more autonomous and efficient reward learning.
Slot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
May 26, 2025Recently, multimodal large language models (MLLMs) have emerged as a key approach in achieving artificial general intelligence. In particular, vision-language MLLMs have been developed to generate not only text but also visual outputs from multimodal inputs. This advancement requires efficient image tokens that LLMs can process effectively both in input and output. However, existing image tokenization methods for MLLMs typically capture only global abstract concepts or uniformly segmented image patches, restricting MLLMs' capability to effectively understand or generate detailed visual content, particularly at the object level. To address this limitation, we propose an object-centric visual tokenizer based on Slot Attention specifically for MLLMs. In particular, based on the Q-Former encoder, diffusion decoder, and residual vector quantization, our proposed discretized slot tokens can encode local visual details while maintaining high-level semantics, and also align with textual data to be integrated seamlessly within a unified next-token prediction framework of LLMs. The resulting Slot-MLLM demonstrates significant performance improvements over baselines with previous visual tokenizers across various vision-language tasks that entail local detailed comprehension and generation. Notably, this work is the first demonstration of the feasibility of object-centric slot attention performed with MLLMs and in-the-wild natural images.
FeRG-LLM : Feature Engineering by Reason Generation Large Language Models
Mar 30, 2025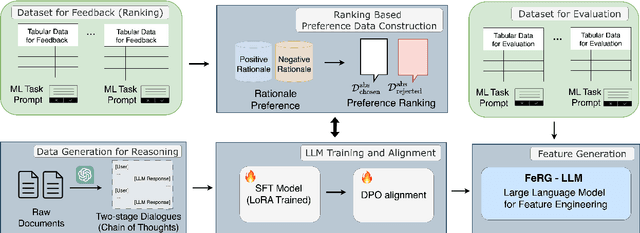


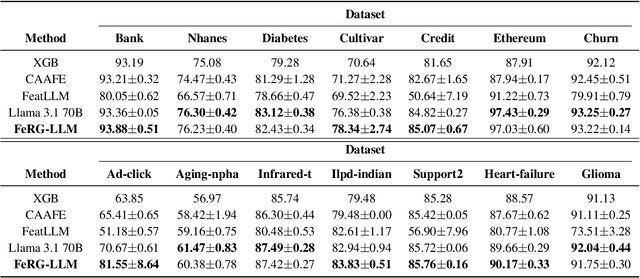
One of the key tasks in machine learning for tabular data is feature engineering. Although it is vital for improving the performance of models, it demands considerable human expertise and deep domain knowledge, making it labor-intensive endeavor. To address this issue, we propose a novel framework, \textbf{FeRG-LLM} (\textbf{Fe}ature engineering by \textbf{R}eason \textbf{G}eneration \textbf{L}arge \textbf{L}anguage \textbf{M}odels), a large language model designed to automatically perform feature engineering at an 8-billion-parameter scale. We have constructed two-stage conversational dialogues that enable language models to analyze machine learning tasks and discovering new features, exhibiting their Chain-of-Thought (CoT) capabilities. We use these dialogues to fine-tune Llama 3.1 8B model and integrate Direct Preference Optimization (DPO) to receive feedback improving quality of new features and the model's performance. Our experiments show that FeRG-LLM performs comparably to or better than Llama 3.1 70B on most datasets, while using fewer resources and achieving reduced inference time. It outperforms other studies in classification tasks and performs well in regression tasks. Moreover, since it does not rely on cloud-hosted LLMs like GPT-4 with extra API costs when generating features, it can be deployed locally, addressing security concerns.
Predictive Coding for Decision Transformer
Oct 04, 2024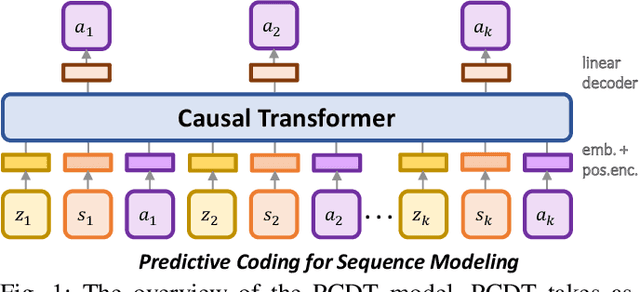
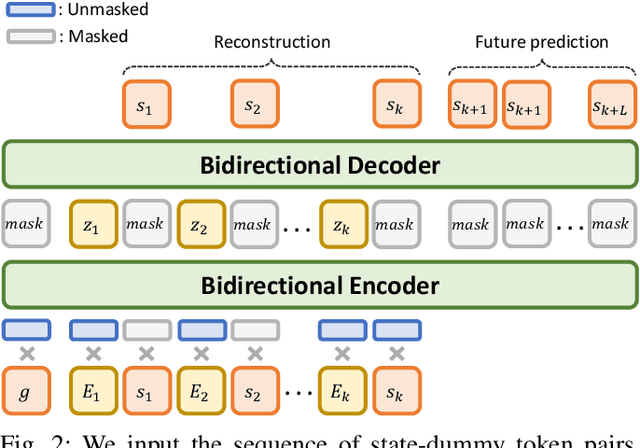
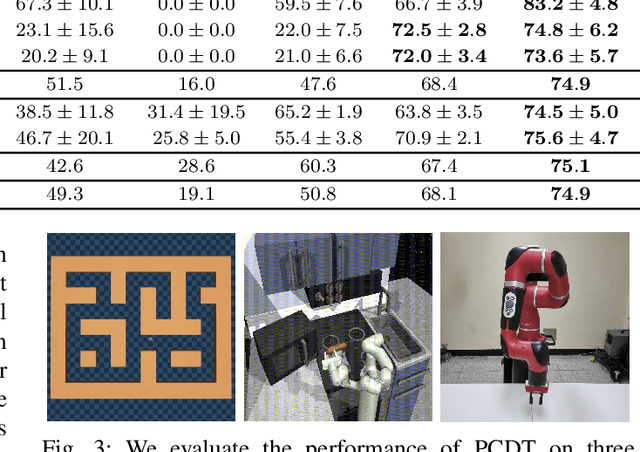
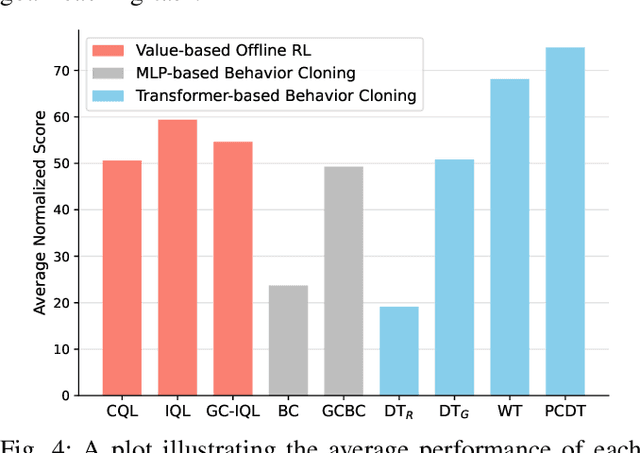
Recent work in offline reinforcement learning (RL) has demonstrated the effectiveness of formulating decision-making as return-conditioned supervised learning. Notably, the decision transformer (DT) architecture has shown promise across various domains. However, despite its initial success, DTs have underperformed on several challenging datasets in goal-conditioned RL. This limitation stems from the inefficiency of return conditioning for guiding policy learning, particularly in unstructured and suboptimal datasets, resulting in DTs failing to effectively learn temporal compositionality. Moreover, this problem might be further exacerbated in long-horizon sparse-reward tasks. To address this challenge, we propose the Predictive Coding for Decision Transformer (PCDT) framework, which leverages generalized future conditioning to enhance DT methods. PCDT utilizes an architecture that extends the DT framework, conditioned on predictive codings, enabling decision-making based on both past and future factors, thereby improving generalization. Through extensive experiments on eight datasets from the AntMaze and FrankaKitchen environments, our proposed method achieves performance on par with or surpassing existing popular value-based and transformer-based methods in offline goal-conditioned RL. Furthermore, we also evaluate our method on a goal-reaching task with a physical robot.
Enhancing Knowledge Tracing with Concept Map and Response Disentanglement
Aug 23, 2024In the rapidly advancing realm of educational technology, it becomes critical to accurately trace and understand student knowledge states. Conventional Knowledge Tracing (KT) models have mainly focused on binary responses (i.e., correct and incorrect answers) to questions. Unfortunately, they largely overlook the essential information in students' actual answer choices, particularly for Multiple Choice Questions (MCQs), which could help reveal each learner's misconceptions or knowledge gaps. To tackle these challenges, we propose the Concept map-driven Response disentanglement method for enhancing Knowledge Tracing (CRKT) model. CRKT benefits KT by directly leveraging answer choices--beyond merely identifying correct or incorrect answers--to distinguish responses with different incorrect choices. We further introduce the novel use of unchosen responses by employing disentangled representations to get insights from options not selected by students. Additionally, CRKT tracks the student's knowledge state at the concept level and encodes the concept map, representing the relationships between them, to better predict unseen concepts. This approach is expected to provide actionable feedback, improving the learning experience. Our comprehensive experiments across multiple datasets demonstrate CRKT's effectiveness, achieving superior performance in prediction accuracy and interpretability over state-of-the-art models.
MAGVLT: Masked Generative Vision-and-Language Transformer
Mar 21, 2023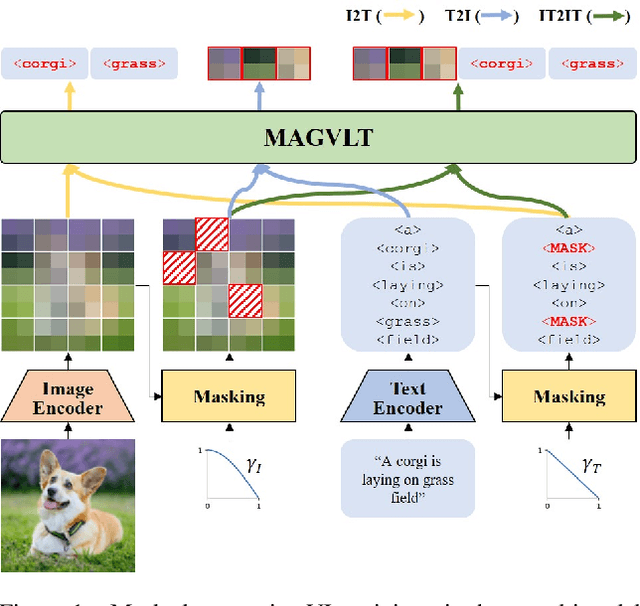
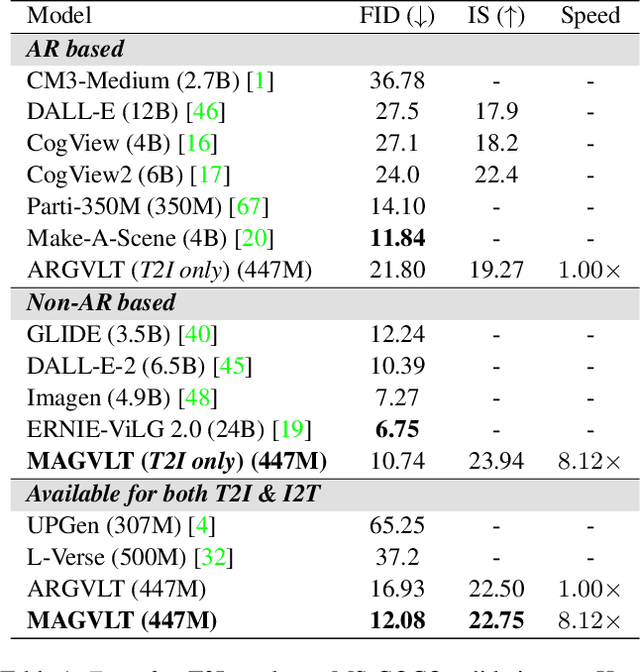
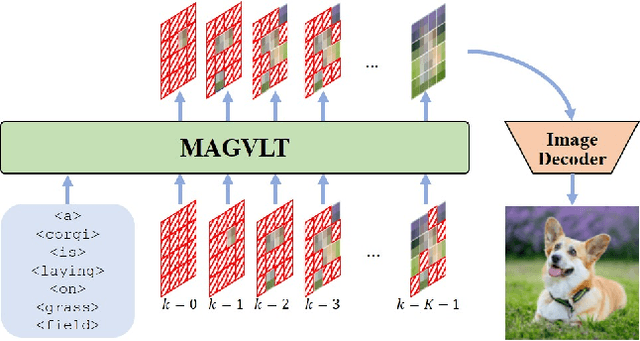
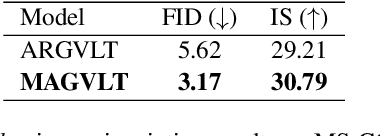
While generative modeling on multimodal image-text data has been actively developed with large-scale paired datasets, there have been limited attempts to generate both image and text data by a single model rather than a generation of one fixed modality conditioned on the other modality. In this paper, we explore a unified generative vision-and-language (VL) model that can produce both images and text sequences. Especially, we propose a generative VL transformer based on the non-autoregressive mask prediction, named MAGVLT, and compare it with an autoregressive generative VL transformer (ARGVLT). In comparison to ARGVLT, the proposed MAGVLT enables bidirectional context encoding, fast decoding by parallel token predictions in an iterative refinement, and extended editing capabilities such as image and text infilling. For rigorous training of our MAGVLT with image-text pairs from scratch, we combine the image-to-text, text-to-image, and joint image-and-text mask prediction tasks. Moreover, we devise two additional tasks based on the step-unrolled mask prediction and the selective prediction on the mixture of two image-text pairs. Experimental results on various downstream generation tasks of VL benchmarks show that our MAGVLT outperforms ARGVLT by a large margin even with significant inference speedup. Particularly, MAGVLT achieves competitive results on both zero-shot image-to-text and text-to-image generation tasks from MS-COCO by one moderate-sized model (fewer than 500M parameters) even without the use of monomodal data and networks.
RMSim: Controlled Respiratory Motion Simulation on Static Patient Scans
Jan 26, 2023This work aims to generate realistic anatomical deformations from static patient scans. Specifically, we present a method to generate these deformations/augmentations via deep learning driven respiratory motion simulation that provides the ground truth for validating deformable image registration (DIR) algorithms and driving more accurate deep learning based DIR. We present a novel 3D Seq2Seq deep learning respiratory motion simulator (RMSim) that learns from 4D-CT images and predicts future breathing phases given a static CT image. The predicted respiratory patterns, represented by time-varying displacement vector fields (DVFs) at different breathing phases, are modulated through auxiliary inputs of 1D breathing traces so that a larger amplitude in the trace results in more significant predicted deformation. Stacked 3D-ConvLSTMs are used to capture the spatial-temporal respiration patterns. Training loss includes a smoothness loss in the DVF and mean-squared error between the predicted and ground truth phase images. A spatial transformer deforms the static CT with the predicted DVF to generate the predicted phase image. 10-phase 4D-CTs of 140 internal patients were used to train and test RMSim. The trained RMSim was then used to augment a public DIR challenge dataset for training VoxelMorph to show the effectiveness of RMSim-generated deformation augmentation. We validated our RMSim output with both private and public benchmark datasets (healthy and cancer patients). The proposed approach can be used for validating DIR algorithms as well as for patient-specific augmentations to improve deep learning DIR algorithms. The code, pretrained models, and augmented DIR validation datasets will be released at https://github.com/nadeemlab/SeqX2Y.
LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward
Oct 11, 2022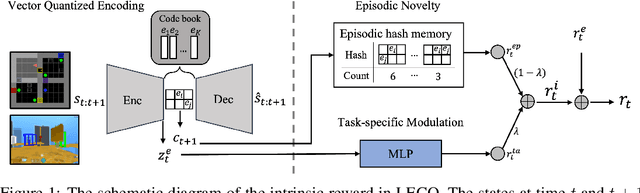
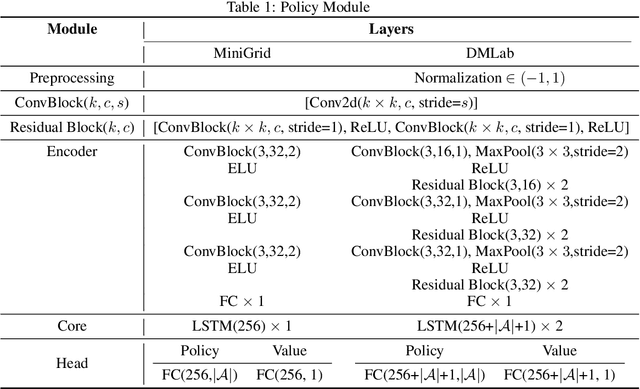
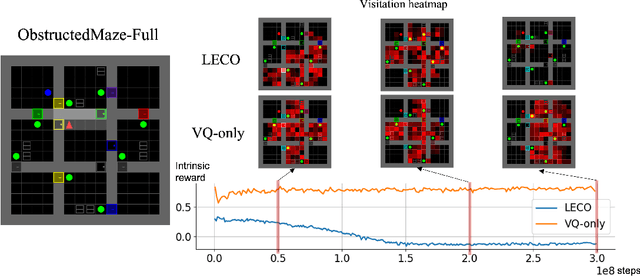
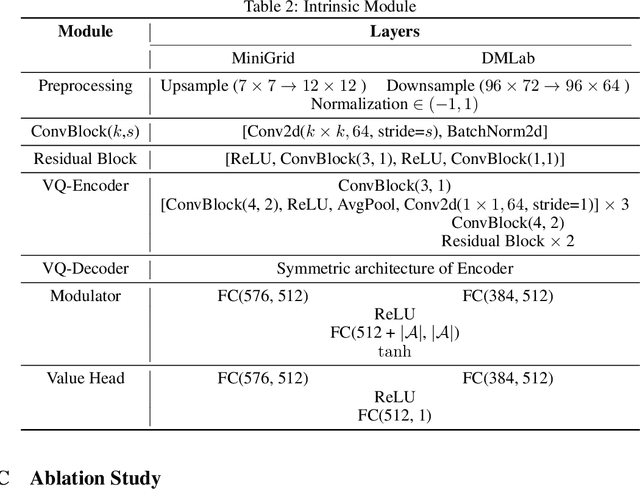
Episodic count has been widely used to design a simple yet effective intrinsic motivation for reinforcement learning with a sparse reward. However, the use of episodic count in a high-dimensional state space as well as over a long episode time requires a thorough state compression and fast hashing, which hinders rigorous exploitation of it in such hard and complex exploration environments. Moreover, the interference from task-irrelevant observations in the episodic count may cause its intrinsic motivation to overlook task-related important changes of states, and the novelty in an episodic manner can lead to repeatedly revisit the familiar states across episodes. In order to resolve these issues, in this paper, we propose a learnable hash-based episodic count, which we name LECO, that efficiently performs as a task-specific intrinsic reward in hard exploration problems. In particular, the proposed intrinsic reward consists of the episodic novelty and the task-specific modulation where the former employs a vector quantized variational autoencoder to automatically obtain the discrete state codes for fast counting while the latter regulates the episodic novelty by learning a modulator to optimize the task-specific extrinsic reward. The proposed LECO specifically enables the automatic transition from exploration to exploitation during reinforcement learning. We experimentally show that in contrast to the previous exploration methods LECO successfully solves hard exploration problems and also scales to large state spaces through the most difficult tasks in MiniGrid and DMLab environments.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022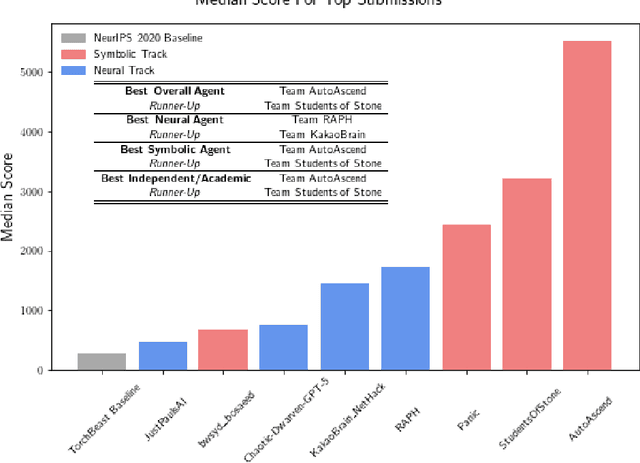

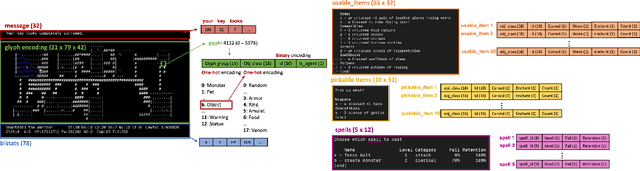
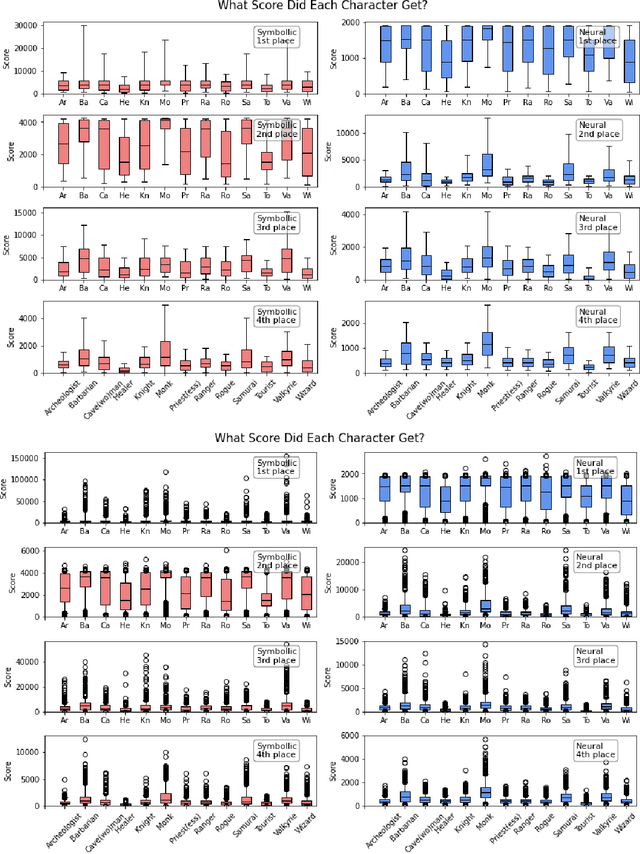
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
Automated Learning Rate Scheduler for Large-batch Training
Jul 13, 2021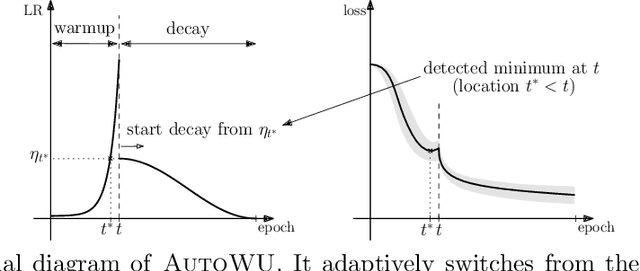
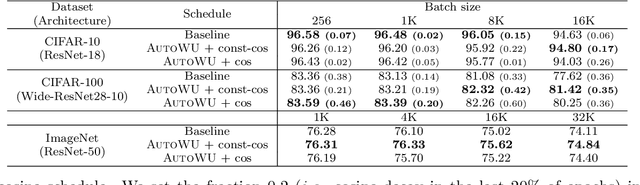
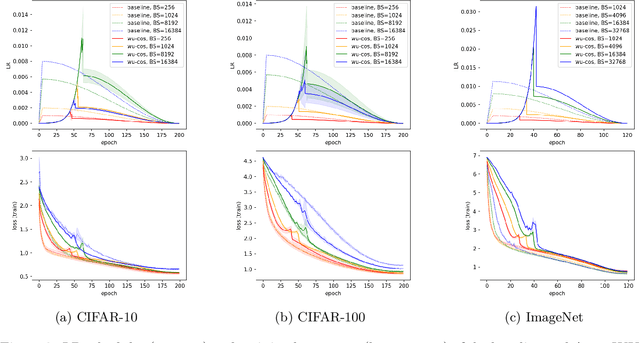

Large-batch training has been essential in leveraging large-scale datasets and models in deep learning. While it is computationally beneficial to use large batch sizes, it often requires a specially designed learning rate (LR) schedule to achieve a comparable level of performance as in smaller batch training. Especially, when the number of training epochs is constrained, the use of a large LR and a warmup strategy is critical in the final performance of large-batch training due to the reduced number of updating steps. In this work, we propose an automated LR scheduling algorithm which is effective for neural network training with a large batch size under the given epoch budget. In specific, the whole schedule consists of two phases: adaptive warmup and predefined decay, where the LR is increased until the training loss no longer decreases and decreased to zero until the end of training. Here, whether the training loss has reached the minimum value is robustly checked with Gaussian process smoothing in an online manner with a low computational burden. Coupled with adaptive stochastic optimizers such as AdamP and LAMB, the proposed scheduler successfully adjusts the LRs without cumbersome hyperparameter tuning and achieves comparable or better performances than tuned baselines on various image classification benchmarks and architectures with a wide range of batch sizes.