 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup3D: MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection
Mar 23, 2026Open-vocabulary 3D object detection aims to localize and recognize objects beyond a fixed training taxonomy. In multi-view RGB settings, recent approaches often decouple geometry-based instance construction from semantic labeling, generating class-agnostic fragments and assigning open-vocabulary categories post hoc. While flexible, such decoupling leaves instance construction governed primarily by geometric consistency, without semantic constraints during merging. When geometric evidence is view-dependent and incomplete, this geometry-only merging can lead to irreversible association errors, including over-merging of distinct objects or fragmentation of a single instance. We propose Group3D, a multi-view open-vocabulary 3D detection framework that integrates semantic constraints directly into the instance construction process. Group3D maintains a scene-adaptive vocabulary derived from a multimodal large language model (MLLM) and organizes it into semantic compatibility groups that encode plausible cross-view category equivalence. These groups act as merge-time constraints: 3D fragments are associated only when they satisfy both semantic compatibility and geometric consistency. This semantically gated merging mitigates geometry-driven over-merging while absorbing multi-view category variability. Group3D supports both pose-known and pose-free settings, relying only on RGB observations. Experiments on ScanNet and ARKitScenes demonstrate that Group3D achieves state-of-the-art performance in multi-view open-vocabulary 3D detection, while exhibiting strong generalization in zero-shot scenarios. The project page is available at https://ubin108.github.io/Group3D/.
Low-pass Personalized Subgraph Federated Recommendation
Mar 20, 2026Federated Recommender Systems (FRS) preserve privacy by training decentralized models on client-specific user-item subgraphs without sharing raw data. However, FRS faces a unique challenge: subgraph structural imbalance, where drastic variations in subgraph scale (user/item counts) and connectivity (item degree) misalign client representations, making it challenging to train a robust model that respects each client's unique structural characteristics. To address this, we propose a Low-pass Personalized Subgraph Federated recommender system (LPSFed). LPSFed leverages graph Fourier transforms and low-pass spectral filtering to extract low-frequency structural signals that remain stable across subgraphs of varying size and degree, allowing robust personalized parameter updates guided by similarity to a neutral structural anchor. Additionally, we leverage a localized popularity bias-aware margin that captures item-degree imbalance within each subgraph and incorporates it into a personalized bias correction term to mitigate recommendation bias. Supported by theoretical analysis and validated on five real-world datasets, LPSFed achieves superior recommendation accuracy and enhances model robustness.
M$^3$KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation
Dec 24, 2025Retrieval-Augmented Generation (RAG) has recently been extended to multimodal settings, connecting multimodal large language models (MLLMs) with vast corpora of external knowledge such as multimodal knowledge graphs (MMKGs). Despite their recent success, multimodal RAG in the audio-visual domain remains challenging due to 1) limited modality coverage and multi-hop connectivity of existing MMKGs, and 2) retrieval based solely on similarity in a shared multimodal embedding space, which fails to filter out off-topic or redundant knowledge. To address these limitations, we propose M$^3$KG-RAG, a Multi-hop Multimodal Knowledge Graph-enhanced RAG that retrieves query-aligned audio-visual knowledge from MMKGs, improving reasoning depth and answer faithfulness in MLLMs. Specifically, we devise a lightweight multi-agent pipeline to construct multi-hop MMKG (M$^3$KG), which contains context-enriched triplets of multimodal entities, enabling modality-wise retrieval based on input queries. Furthermore, we introduce GRASP (Grounded Retrieval And Selective Pruning), which ensures precise entity grounding to the query, evaluates answer-supporting relevance, and prunes redundant context to retain only knowledge essential for response generation. Extensive experiments across diverse multimodal benchmarks demonstrate that M$^3$KG-RAG significantly enhances MLLMs' multimodal reasoning and grounding over existing approaches.
Balancing Graph Embedding Smoothness in Self-Supervised Learning via Information-Theoretic Decomposition
Apr 16, 2025Self-supervised learning (SSL) in graphs has garnered significant attention, particularly in employing Graph Neural Networks (GNNs) with pretext tasks initially designed for other domains, such as contrastive learning and feature reconstruction. However, it remains uncertain whether these methods effectively reflect essential graph properties, precisely representation similarity with its neighbors. We observe that existing methods position opposite ends of a spectrum driven by the graph embedding smoothness, with each end corresponding to outperformance on specific downstream tasks. Decomposing the SSL objective into three terms via an information-theoretic framework with a neighbor representation variable reveals that this polarization stems from an imbalance among the terms, which existing methods may not effectively maintain. Further insights suggest that balancing between the extremes can lead to improved performance across a wider range of downstream tasks. A framework, BSG (Balancing Smoothness in Graph SSL), introduces novel loss functions designed to supplement the representation quality in graph-based SSL by balancing the derived three terms: neighbor loss, minimal loss, and divergence loss. We present a theoretical analysis of the effects of these loss functions, highlighting their significance from both the SSL and graph smoothness perspectives. Extensive experiments on multiple real-world datasets across node classification and link prediction consistently demonstrate that BSG achieves state-of-the-art performance, outperforming existing methods. Our implementation code is available at https://github.com/steve30572/BSG.
Large Language Models Are Better Logical Fallacy Reasoners with Counterargument, Explanation, and Goal-Aware Prompt Formulation
Mar 30, 2025



The advancement of Large Language Models (LLMs) has greatly improved our ability to process complex language. However, accurately detecting logical fallacies remains a significant challenge. This study presents a novel and effective prompt formulation approach for logical fallacy detection, applicable in both supervised (fine-tuned) and unsupervised (zero-shot) settings. Our method enriches input text incorporating implicit contextual information -- counterarguments, explanations, and goals -- which we query for validity within the context of the argument. We then rank these queries based on confidence scores to inform classification. We evaluate our approach across multiple datasets from 5 domains, covering 29 distinct fallacy types, using models from the GPT and LLaMA series. The results show substantial improvements over state-of-the-art models, with F1 score increases of up to 0.60 in zero-shot settings and up to 0.45 in fine-tuned models. Extensive analyses further illustrate why and how our method excels.
CIMAGE: Exploiting the Conditional Independence in Masked Graph Auto-encoders
Mar 10, 2025Recent Self-Supervised Learning (SSL) methods encapsulating relational information via masking in Graph Neural Networks (GNNs) have shown promising performance. However, most existing approaches rely on random masking strategies in either feature or graph space, which may fail to capture task-relevant information fully. We posit that this limitation stems from an inability to achieve minimum redundancy between masked and unmasked components while ensuring maximum relevance of both to potential downstream tasks. Conditional Independence (CI) inherently satisfies the minimum redundancy and maximum relevance criteria, but its application typically requires access to downstream labels. To address this challenge, we introduce CIMAGE, a novel approach that leverages Conditional Independence to guide an effective masking strategy within the latent space. CIMAGE utilizes CI-aware latent factor decomposition to generate two distinct contexts, leveraging high-confidence pseudo-labels derived from unsupervised graph clustering. In this framework, the pretext task involves reconstructing the masked second context solely from the information provided by the first context. Our theoretical analysis further supports the superiority of CIMAGE's novel CI-aware masking method by demonstrating that the learned embedding exhibits approximate linear separability, which enables accurate predictions for the downstream task. Comprehensive evaluations across diverse graph benchmarks illustrate the advantage of CIMAGE, with notably higher average rankings on node classification and link prediction tasks. Notably, our proposed model highlights the under-explored potential of CI in enhancing graph SSL methodologies and offers enriched insights for effective graph representation learning.
MAMS: Model-Agnostic Module Selection Framework for Video Captioning
Jan 30, 2025



Multi-modal transformers are rapidly gaining attention in video captioning tasks. Existing multi-modal video captioning methods typically extract a fixed number of frames, which raises critical challenges. When a limited number of frames are extracted, important frames with essential information for caption generation may be missed. Conversely, extracting an excessive number of frames includes consecutive frames, potentially causing redundancy in visual tokens extracted from consecutive video frames. To extract an appropriate number of frames for each video, this paper proposes the first model-agnostic module selection framework in video captioning that has two main functions: (1) selecting a caption generation module with an appropriate size based on visual tokens extracted from video frames, and (2) constructing subsets of visual tokens for the selected caption generation module. Furthermore, we propose a new adaptive attention masking scheme that enhances attention on important visual tokens. Our experiments on three different benchmark datasets demonstrate that the proposed framework significantly improves the performance of three recent video captioning models.
Enhancing Knowledge Tracing with Concept Map and Response Disentanglement
Aug 23, 2024In the rapidly advancing realm of educational technology, it becomes critical to accurately trace and understand student knowledge states. Conventional Knowledge Tracing (KT) models have mainly focused on binary responses (i.e., correct and incorrect answers) to questions. Unfortunately, they largely overlook the essential information in students' actual answer choices, particularly for Multiple Choice Questions (MCQs), which could help reveal each learner's misconceptions or knowledge gaps. To tackle these challenges, we propose the Concept map-driven Response disentanglement method for enhancing Knowledge Tracing (CRKT) model. CRKT benefits KT by directly leveraging answer choices--beyond merely identifying correct or incorrect answers--to distinguish responses with different incorrect choices. We further introduce the novel use of unchosen responses by employing disentangled representations to get insights from options not selected by students. Additionally, CRKT tracks the student's knowledge state at the concept level and encodes the concept map, representing the relationships between them, to better predict unseen concepts. This approach is expected to provide actionable feedback, improving the learning experience. Our comprehensive experiments across multiple datasets demonstrate CRKT's effectiveness, achieving superior performance in prediction accuracy and interpretability over state-of-the-art models.
Improving Multi-hop Logical Reasoning in Knowledge Graphs with Context-Aware Query Representation Learning
Jun 11, 2024Multi-hop logical reasoning on knowledge graphs is a pivotal task in natural language processing, with numerous approaches aiming to answer First-Order Logic (FOL) queries. Recent geometry (e.g., box, cone) and probability (e.g., beta distribution)-based methodologies have effectively addressed complex FOL queries. However, a common challenge across these methods lies in determining accurate geometric bounds or probability parameters for these queries. The challenge arises because existing methods rely on linear sequential operations within their computation graphs, overlooking the logical structure of the query and the relation-induced information that can be gleaned from the relations of the query, which we call the context of the query. To address the problem, we propose a model-agnostic methodology that enhances the effectiveness of existing multi-hop logical reasoning approaches by fully integrating the context of the FOL query graph. Our approach distinctively discerns (1) the structural context inherent to the query structure and (2) the relation-induced context unique to each node in the query graph as delineated in the corresponding knowledge graph. This dual-context paradigm helps nodes within a query graph attain refined internal representations throughout the multi-hop reasoning steps. Through experiments on two datasets, our method consistently enhances the three multi-hop reasoning foundation models, achieving performance improvements of up to 19.5%. Our code is available at https://github.com/kjh9503/caqr.
Toward a Better Understanding of Loss Functions for Collaborative Filtering
Aug 11, 2023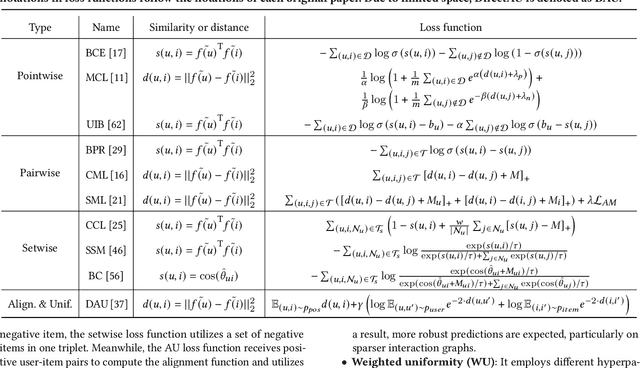
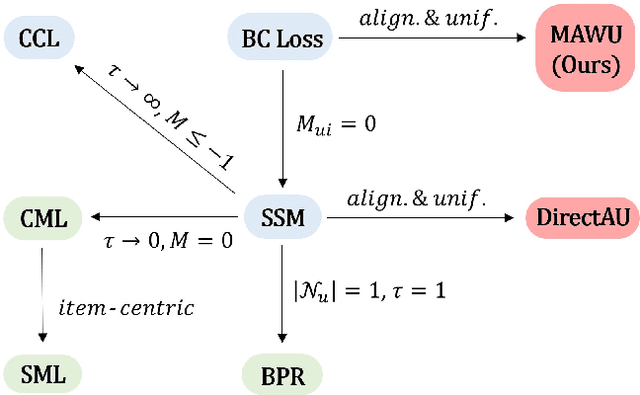
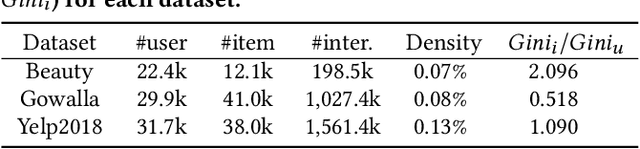
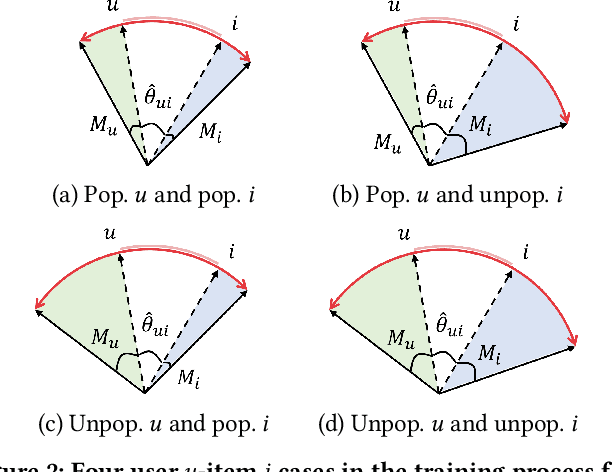
Collaborative filtering (CF) is a pivotal technique in modern recommender systems. The learning process of CF models typically consists of three components: interaction encoder, loss function, and negative sampling. Although many existing studies have proposed various CF models to design sophisticated interaction encoders, recent work shows that simply reformulating the loss functions can achieve significant performance gains. This paper delves into analyzing the relationship among existing loss functions. Our mathematical analysis reveals that the previous loss functions can be interpreted as alignment and uniformity functions: (i) the alignment matches user and item representations, and (ii) the uniformity disperses user and item distributions. Inspired by this analysis, we propose a novel loss function that improves the design of alignment and uniformity considering the unique patterns of datasets called Margin-aware Alignment and Weighted Uniformity (MAWU). The key novelty of MAWU is two-fold: (i) margin-aware alignment (MA) mitigates user/item-specific popularity biases, and (ii) weighted uniformity (WU) adjusts the significance between user and item uniformities to reflect the inherent characteristics of datasets. Extensive experimental results show that MF and LightGCN equipped with MAWU are comparable or superior to state-of-the-art CF models with various loss functions on three public datasets.