 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetCCL: Accelerating LLM Training with Heterogeneous GPUs
Jan 30, 2026The rapid growth of large language models is driving organizations to expand their GPU clusters, often with GPUs from multiple vendors. However, current deep learning frameworks lack support for collective communication across heterogeneous GPUs, leading to inefficiency and higher costs. We present HetCCL, a collective communication library that unifies vendor-specific backends and enables RDMA-based communication across GPUs without requiring driver modifications. HetCCL introduces two novel mechanisms that enable cross-vendor communication while leveraging optimized vendor libraries, NVIDIA NCCL and AMD RCCL. Evaluations on a multi-vendor GPU cluster show that HetCCL matches NCCL and RCCL performance in homogeneous setups while uniquely scaling in heterogeneous environments, enabling practical, high-performance training with both NVIDIA and AMD GPUs without changes to existing deep learning applications.
CIMAGE: Exploiting the Conditional Independence in Masked Graph Auto-encoders
Mar 10, 2025Recent Self-Supervised Learning (SSL) methods encapsulating relational information via masking in Graph Neural Networks (GNNs) have shown promising performance. However, most existing approaches rely on random masking strategies in either feature or graph space, which may fail to capture task-relevant information fully. We posit that this limitation stems from an inability to achieve minimum redundancy between masked and unmasked components while ensuring maximum relevance of both to potential downstream tasks. Conditional Independence (CI) inherently satisfies the minimum redundancy and maximum relevance criteria, but its application typically requires access to downstream labels. To address this challenge, we introduce CIMAGE, a novel approach that leverages Conditional Independence to guide an effective masking strategy within the latent space. CIMAGE utilizes CI-aware latent factor decomposition to generate two distinct contexts, leveraging high-confidence pseudo-labels derived from unsupervised graph clustering. In this framework, the pretext task involves reconstructing the masked second context solely from the information provided by the first context. Our theoretical analysis further supports the superiority of CIMAGE's novel CI-aware masking method by demonstrating that the learned embedding exhibits approximate linear separability, which enables accurate predictions for the downstream task. Comprehensive evaluations across diverse graph benchmarks illustrate the advantage of CIMAGE, with notably higher average rankings on node classification and link prediction tasks. Notably, our proposed model highlights the under-explored potential of CI in enhancing graph SSL methodologies and offers enriched insights for effective graph representation learning.
Finetuning Pre-trained Model with Limited Data for LiDAR-based 3D Object Detection by Bridging Domain Gaps
Oct 02, 2024



LiDAR-based 3D object detectors have been largely utilized in various applications, including autonomous vehicles or mobile robots. However, LiDAR-based detectors often fail to adapt well to target domains with different sensor configurations (e.g., types of sensors, spatial resolution, or FOVs) and location shifts. Collecting and annotating datasets in a new setup is commonly required to reduce such gaps, but it is often expensive and time-consuming. Recent studies suggest that pre-trained backbones can be learned in a self-supervised manner with large-scale unlabeled LiDAR frames. However, despite their expressive representations, they remain challenging to generalize well without substantial amounts of data from the target domain. Thus, we propose a novel method, called Domain Adaptive Distill-Tuning (DADT), to adapt a pre-trained model with limited target data (approximately 100 LiDAR frames), retaining its representation power and preventing it from overfitting. Specifically, we use regularizers to align object-level and context-level representations between the pre-trained and finetuned models in a teacher-student architecture. Our experiments with driving benchmarks, i.e., Waymo Open dataset and KITTI, confirm that our method effectively finetunes a pre-trained model, achieving significant gains in accuracy.
Resolving Class Imbalance for LiDAR-based Object Detector by Dynamic Weight Average and Contextual Ground Truth Sampling
Oct 07, 2022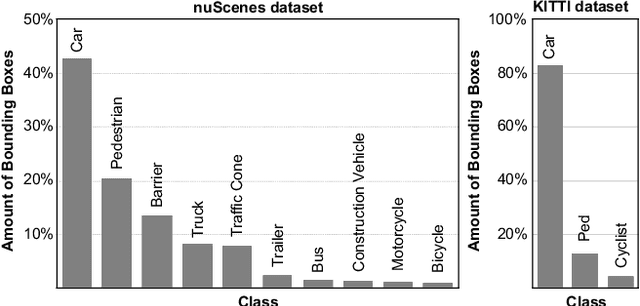

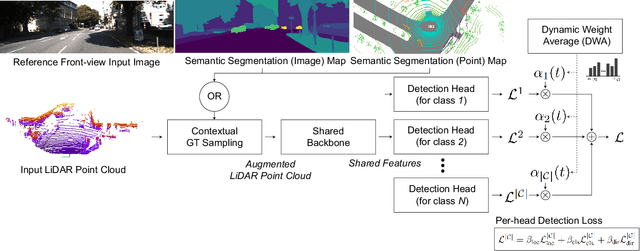

An autonomous driving system requires a 3D object detector, which must perceive all present road agents reliably to navigate an environment safely. However, real-world driving datasets often suffer from the problem of data imbalance, which causes difficulties in training a model that works well across all classes, resulting in an undesired imbalanced sub-optimal performance. In this work, we propose a method to address this data imbalance problem. Our method consists of two main components: (i) a LiDAR-based 3D object detector with per-class multiple detection heads where losses from each head are modified by dynamic weight average to be balanced. (ii) Contextual ground truth (GT) sampling, where we improve conventional GT sampling techniques by leveraging semantic information to augment point cloud with sampled ground truth GT objects. Our experiment with KITTI and nuScenes datasets confirms our proposed method's effectiveness in dealing with the data imbalance problem, producing better detection accuracy compared to existing approaches.