 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesture-Aware Zero-Shot Speech Recognition for Patients with Language Disorders
Feb 18, 2025Individuals with language disorders often face significant communication challenges due to their limited language processing and comprehension abilities, which also affect their interactions with voice-assisted systems that mostly rely on Automatic Speech Recognition (ASR). Despite advancements in ASR that address disfluencies, there has been little attention on integrating non-verbal communication methods, such as gestures, which individuals with language disorders substantially rely on to supplement their communication. Recognizing the need to interpret the latent meanings of visual information not captured by speech alone, we propose a gesture-aware ASR system utilizing a multimodal large language model with zero-shot learning for individuals with speech impairments. Our experiment results and analyses show that including gesture information significantly enhances semantic understanding. This study can help develop effective communication technologies, specifically designed to meet the unique needs of individuals with language impairments.
VideoRepair: Improving Text-to-Video Generation via Misalignment Evaluation and Localized Refinement
Nov 22, 2024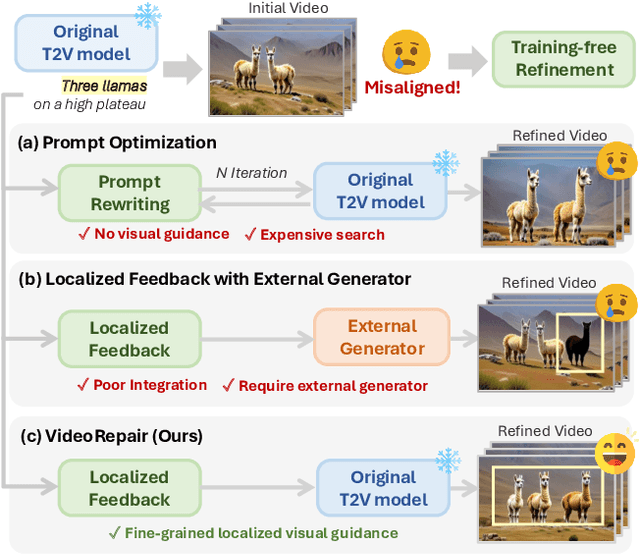
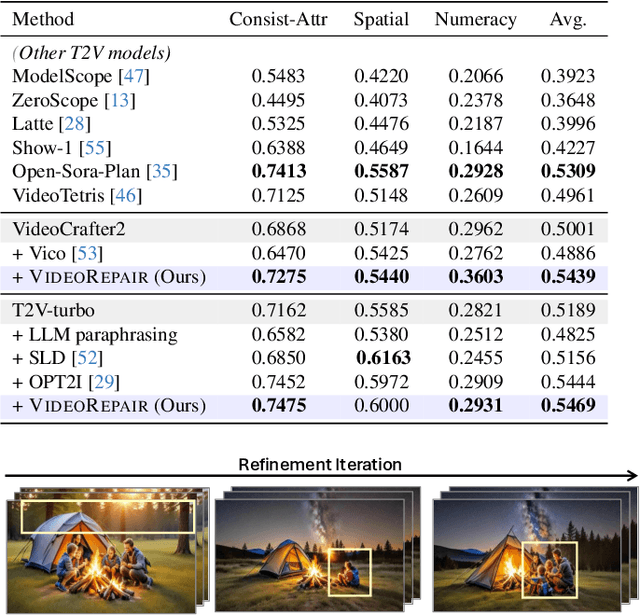

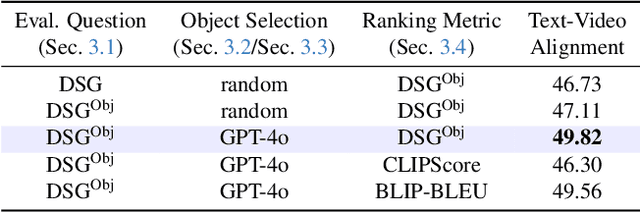
Recent text-to-video (T2V) diffusion models have demonstrated impressive generation capabilities across various domains. However, these models often generate videos that have misalignments with text prompts, especially when the prompts describe complex scenes with multiple objects and attributes. To address this, we introduce VideoRepair, a novel model-agnostic, training-free video refinement framework that automatically identifies fine-grained text-video misalignments and generates explicit spatial and textual feedback, enabling a T2V diffusion model to perform targeted, localized refinements. VideoRepair consists of four stages: In (1) video evaluation, we detect misalignments by generating fine-grained evaluation questions and answering those questions with MLLM. In (2) refinement planning, we identify accurately generated objects and then create localized prompts to refine other areas in the video. Next, in (3) region decomposition, we segment the correctly generated area using a combined grounding module. We regenerate the video by adjusting the misaligned regions while preserving the correct regions in (4) localized refinement. On two popular video generation benchmarks (EvalCrafter and T2V-CompBench), VideoRepair substantially outperforms recent baselines across various text-video alignment metrics. We provide a comprehensive analysis of VideoRepair components and qualitative examples.
Text-to-Battery Recipe: A language modeling-based protocol for automatic battery recipe extraction and retrieval
Jul 22, 2024Recent studies have increasingly applied natural language processing (NLP) to automatically extract experimental research data from the extensive battery materials literature. Despite the complex process involved in battery manufacturing -- from material synthesis to cell assembly -- there has been no comprehensive study systematically organizing this information. In response, we propose a language modeling-based protocol, Text-to-Battery Recipe (T2BR), for the automatic extraction of end-to-end battery recipes, validated using a case study on batteries containing LiFePO4 cathode material. We report machine learning-based paper filtering models, screening 2,174 relevant papers from the keyword-based search results, and unsupervised topic models to identify 2,876 paragraphs related to cathode synthesis and 2,958 paragraphs related to cell assembly. Then, focusing on the two topics, two deep learning-based named entity recognition models are developed to extract a total of 30 entities -- including precursors, active materials, and synthesis methods -- achieving F1 scores of 88.18% and 94.61%. The accurate extraction of entities enables the systematic generation of 165 end-toend recipes of LiFePO4 batteries. Our protocol and results offer valuable insights into specific trends, such as associations between precursor materials and synthesis methods, or combinations between different precursor materials. We anticipate that our findings will serve as a foundational knowledge base for facilitating battery-recipe information retrieval. The proposed protocol will significantly accelerate the review of battery material literature and catalyze innovations in battery design and development.
A Dual-Prompting for Interpretable Mental Health Language Models
Feb 20, 2024Despite the increasing demand for AI-based mental health monitoring tools, their practical utility for clinicians is limited by the lack of interpretability.The CLPsych 2024 Shared Task (Chim et al., 2024) aims to enhance the interpretability of Large Language Models (LLMs), particularly in mental health analysis, by providing evidence of suicidality through linguistic content. We propose a dual-prompting approach: (i) Knowledge-aware evidence extraction by leveraging the expert identity and a suicide dictionary with a mental health-specific LLM; and (ii) Evidence summarization by employing an LLM-based consistency evaluator. Comprehensive experiments demonstrate the effectiveness of combining domain-specific information, revealing performance improvements and the approach's potential to aid clinicians in assessing mental state progression.
BECoTTA: Input-dependent Online Blending of Experts for Continual Test-time Adaptation
Feb 15, 2024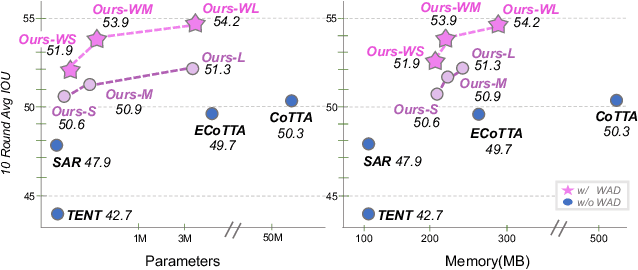
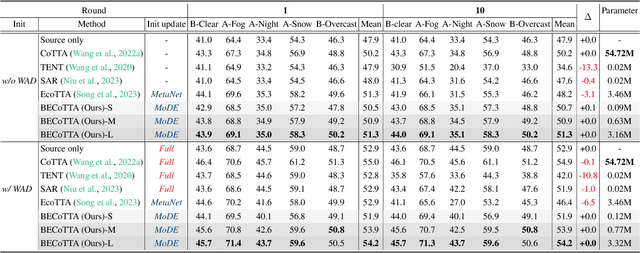
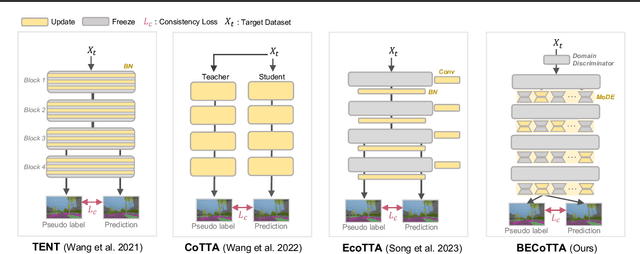
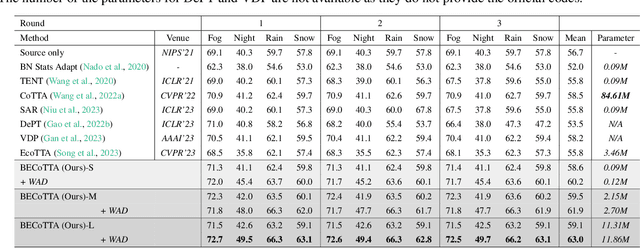
Continual Test Time Adaptation (CTTA) is required to adapt efficiently to continuous unseen domains while retaining previously learned knowledge. However, despite the progress of CTTA, forgetting-adaptation trade-offs and efficiency are still unexplored. Moreover, current CTTA scenarios assume only the disjoint situation, even though real-world domains are seamlessly changed. To tackle these challenges, this paper proposes BECoTTA, an input-dependent yet efficient framework for CTTA. We propose Mixture-of-Domain Low-rank Experts (MoDE) that contains two core components: (i) Domain-Adaptive Routing, which aids in selectively capturing the domain-adaptive knowledge with multiple domain routers, and (ii) Domain-Expert Synergy Loss to maximize the dependency between each domain and expert. We validate our method outperforms multiple CTTA scenarios including disjoint and gradual domain shits, while only requiring ~98% fewer trainable parameters. We also provide analyses of our method, including the construction of experts, the effect of domain-adaptive experts, and visualizations.
Improving Lane Detection Generalization: A Novel Framework using HD Maps for Boosting Diversity
Nov 28, 2023Lane detection is a vital task for vehicles to navigate and localize their position on the road. To ensure reliable results, lane detection algorithms must have robust generalization performance in various road environments. However, despite the significant performance improvement of deep learning-based lane detection algorithms, their generalization performance in response to changes in road environments still falls short of expectations. In this paper, we present a novel framework for single-source domain generalization (SSDG) in lane detection. By decomposing data into lane structures and surroundings, we enhance diversity using High-Definition (HD) maps and generative models. Rather than expanding data volume, we strategically select a core subset of data, maximizing diversity and optimizing performance. Our extensive experiments demonstrate that our framework enhances the generalization performance of lane detection, comparable to the domain adaptation-based method.
Learning Co-Speech Gesture for Multimodal Aphasia Type Detection
Oct 20, 2023Aphasia, a language disorder resulting from brain damage, requires accurate identification of specific aphasia types, such as Broca's and Wernicke's aphasia, for effective treatment. However, little attention has been paid to developing methods to detect different types of aphasia. Recognizing the importance of analyzing co-speech gestures for distinguish aphasia types, we propose a multimodal graph neural network for aphasia type detection using speech and corresponding gesture patterns. By learning the correlation between the speech and gesture modalities for each aphasia type, our model can generate textual representations sensitive to gesture information, leading to accurate aphasia type detection. Extensive experiments demonstrate the superiority of our approach over existing methods, achieving state-of-the-art results (F1 84.2\%). We also show that gesture features outperform acoustic features, highlighting the significance of gesture expression in detecting aphasia types. We provide the codes for reproducibility purposes.
Towards Suicide Prevention from Bipolar Disorder with Temporal Symptom-Aware Multitask Learning
Jul 03, 2023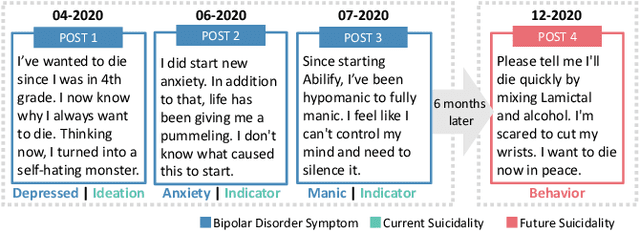
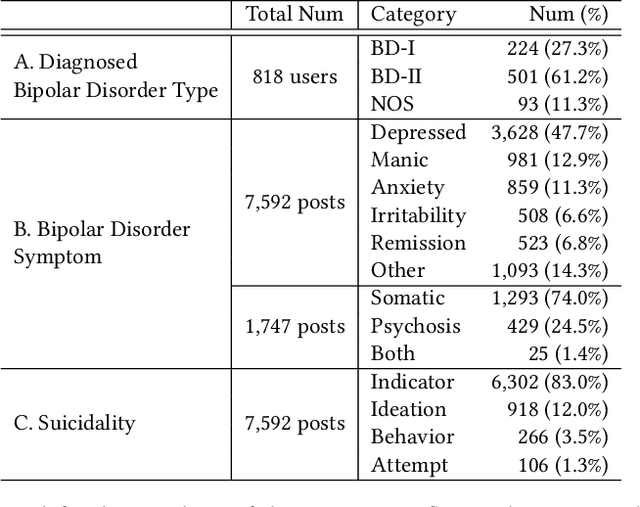
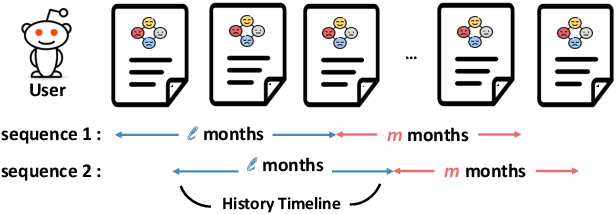
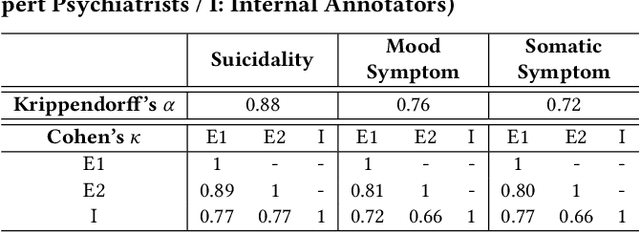
Bipolar disorder (BD) is closely associated with an increased risk of suicide. However, while the prior work has revealed valuable insight into understanding the behavior of BD patients on social media, little attention has been paid to developing a model that can predict the future suicidality of a BD patient. Therefore, this study proposes a multi-task learning model for predicting the future suicidality of BD patients by jointly learning current symptoms. We build a novel BD dataset clinically validated by psychiatrists, including 14 years of posts on bipolar-related subreddits written by 818 BD patients, along with the annotations of future suicidality and BD symptoms. We also suggest a temporal symptom-aware attention mechanism to determine which symptoms are the most influential for predicting future suicidality over time through a sequence of BD posts. Our experiments demonstrate that the proposed model outperforms the state-of-the-art models in both BD symptom identification and future suicidality prediction tasks. In addition, the proposed temporal symptom-aware attention provides interpretable attention weights, helping clinicians to apprehend BD patients more comprehensively and to provide timely intervention by tracking mental state progression.
* KDD 2023 accepted
Resolving Class Imbalance for LiDAR-based Object Detector by Dynamic Weight Average and Contextual Ground Truth Sampling
Oct 07, 2022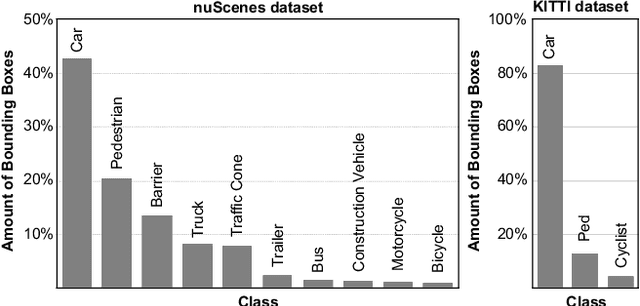

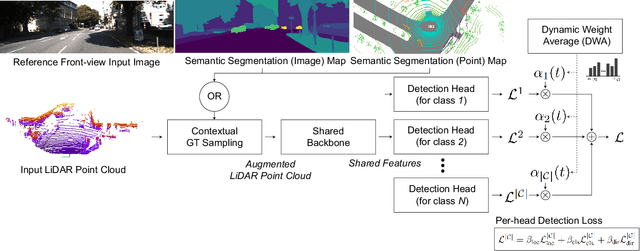

An autonomous driving system requires a 3D object detector, which must perceive all present road agents reliably to navigate an environment safely. However, real-world driving datasets often suffer from the problem of data imbalance, which causes difficulties in training a model that works well across all classes, resulting in an undesired imbalanced sub-optimal performance. In this work, we propose a method to address this data imbalance problem. Our method consists of two main components: (i) a LiDAR-based 3D object detector with per-class multiple detection heads where losses from each head are modified by dynamic weight average to be balanced. (ii) Contextual ground truth (GT) sampling, where we improve conventional GT sampling techniques by leveraging semantic information to augment point cloud with sampled ground truth GT objects. Our experiment with KITTI and nuScenes datasets confirms our proposed method's effectiveness in dealing with the data imbalance problem, producing better detection accuracy compared to existing approaches.