 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUOTIP: Unbalanced Optimal Transport Map for Unpaired Inverse Problems
May 20, 2026We investigate unpaired image inverse problems, a challenging setting where only independent, non-paired sets of noisy measurements and clean target signals are available for training. We propose a novel inverse problem solver based on Unbalanced Optimal Transport, called Unbalanced Optimal Transport Map for Inverse Problems (UOTIP). Our method formulates the reconstruction task, predicting clean target signals from noisy measurements, as learning a UOT Map from noisy measurement distribution to clean signal distribution by incorporating a likelihood-based cost function. By relaxing the exact marginal constraint, the UOT framework provides key advantages to our model: robustness to multi-level observation noise, adaptability to class imbalance between noisy and clean datasets, and generalizability to diverse noise-type scenarios. Furthermore, we theoretically demonstrate that incorporating a quadratic cost term ensures the existence and uniqueness of the transport map by satisfying the twist condition, even for ill-posed inverse problems. Our experiments demonstrate that UOTIP achieves state-of-the-art performance on unpaired image inverse problem benchmarks, across linear and nonlinear inverse problems.
Efficient Adjoint Matching for Fine-tuning Diffusion Models
May 12, 2026Reward fine-tuning has become a common approach for aligning pretrained diffusion and flow models with human preferences in text-to-image generation. Among reward-gradient-based methods, Adjoint Matching (AM) provides a principled formulation by casting reward fine-tuning as a stochastic optimal control (SOC) problem. However, AM inevitably requires a substantial computational cost: it requires (i) stochastic simulation of full generative trajectories under memoryless dynamics, resulting in a large number of function evaluations, and (ii) backward ODE simulation of the adjoint state along each sampled trajectory. In this work, we observe that both bottlenecks are closely tied to the \textit{non-trivial base drift} inherited from the pretrained model. Motivated by this observation, we propose \textbf{Efficient Adjoint Matching (EAM)}, which substantially improves training efficiency by reformulating the SOC problem with a \textit{linear base drift} and a correspondingly modified \textit{terminal cost}. This reformulation removes both sources of inefficiency; it enables training-time sampling with a few-step deterministic ODE solver and yields a closed-form adjoint solution that eliminates backward adjoint simulation. On standard text-to-image reward fine-tuning benchmarks, EAM converges up to 4x faster than AM and matches or surpasses it across various metrics including PickScore, ImageReward, HPSv2.1, CLIPScore and Aesthetics.
Unlearning for One-Step Generative Models via Unbalanced Optimal Transport
Mar 17, 2026Recent advances in one-step generative frameworks, such as flow map models, have significantly improved the efficiency of image generation by learning direct noise-to-data mappings in a single forward pass. However, machine unlearning for ensuring the safety of these powerful generators remains entirely unexplored. Existing diffusion unlearning methods are inherently incompatible with these one-step models, as they rely on a multi-step iterative denoising process. In this work, we propose UOT-Unlearn, a novel plug-and-play class unlearning framework for one-step generative models based on the Unbalanced Optimal Transport (UOT). Our method formulates unlearning as a principled trade-off between a forget cost, which suppresses the target class, and an $f$-divergence penalty, which preserves overall generation fidelity via relaxed marginal constraints. By leveraging UOT, our method enables the probability mass of the forgotten class to be smoothly redistributed to the remaining classes, rather than collapsing into low-quality or noise-like samples. Experimental results on CIFAR-10 and ImageNet-256 demonstrate that our framework achieves superior unlearning success (PUL) and retention quality (u-FID), significantly outperforming baselines.
Neural Optimal Transport in Hilbert Spaces: Characterizing Spurious Solutions and Gaussian Smoothing
Feb 15, 2026We study Neural Optimal Transport in infinite-dimensional Hilbert spaces. In non-regular settings, Semi-dual Neural OT often generates spurious solutions that fail to accurately capture target distributions. We analytically characterize this spurious solution problem using the framework of regular measures, which generalize Lebesgue absolute continuity in finite dimensions. To resolve ill-posedness, we extend the semi-dual framework via a Gaussian smoothing strategy based on Brownian motion. Our primary theoretical contribution proves that under a regular source measure, the formulation is well-posed and recovers a unique Monge map. Furthermore, we establish a sharp characterization for the regularity of smoothed measures, proving that the success of smoothing depends strictly on the kernel of the covariance operator. Empirical results on synthetic functional data and time-series datasets demonstrate that our approach effectively suppresses spurious solutions and outperforms existing baselines.
Rate-Optimal Noise Annealing in Semi-Dual Neural Optimal Transport: Tangential Identifiability, Off-Manifold Ambiguity, and Guaranteed Recovery
Feb 04, 2026Semi-dual neural optimal transport learns a transport map via a max-min objective, yet training can converge to incorrect or degenerate maps. We fully characterize these spurious solutions in the common regime where data concentrate on low-dimensional manifold: the objective is underconstrained off the data manifold, while the on-manifold transport signal remains identifiable. Following Choi, Choi, and Kwon (2025), we study additive-noise smoothing as a remedy and prove new map recovery guarantees as the noise vanishes. Our main practical contribution is a computable terminal noise level $\varepsilon_{\mathrm{stat}}(N)$ that attains the optimal statistical rate, with scaling governed by the intrinsic dimension $m$ of the data. The formula arises from a theoretical unified analysis of (i) quantitative stability of optimal plans, (ii) smoothing-induced bias, and (iii) finite-sample error, yielding rates that depend on $m$ rather than the ambient dimension. Finally, we show that the reduced semi-dual objective becomes increasingly ill-conditioned as $\varepsilon \downarrow 0$. This provides a principled stopping rule: annealing below $\varepsilon_{\mathrm{stat}}(N)$ can $\textit{worsen}$ optimization conditioning without improving statistical accuracy.
Overcoming Fake Solutions in Semi-Dual Neural Optimal Transport: A Smoothing Approach for Learning the Optimal Transport Plan
Feb 07, 2025



We address the convergence problem in learning the Optimal Transport (OT) map, where the OT Map refers to a map from one distribution to another while minimizing the transport cost. Semi-dual Neural OT, a widely used approach for learning OT Maps with neural networks, often generates fake solutions that fail to transfer one distribution to another accurately. We identify a sufficient condition under which the max-min solution of Semi-dual Neural OT recovers the true OT Map. Moreover, to address cases when this sufficient condition is not satisfied, we propose a novel method, OTP, which learns both the OT Map and the Optimal Transport Plan, representing the optimal coupling between two distributions. Under sharp assumptions on the distributions, we prove that our model eliminates the fake solution issue and correctly solves the OT problem. Our experiments show that the OTP model recovers the optimal transport map where existing methods fail and outperforms current OT-based models in image-to-image translation tasks. Notably, the OTP model can learn stochastic transport maps when deterministic OT Maps do not exist, such as one-to-many tasks like colorization.
Dynamic technology impact analysis: A multi-task learning approach to patent citation prediction
Nov 14, 2024



Machine learning (ML) models are valuable tools for analyzing the impact of technology using patent citation information. However, existing ML-based methods often struggle to account for the dynamic nature of the technology impact over time and the interdependencies of these impacts across different periods. This study proposes a multi-task learning (MTL) approach to enhance the prediction of technology impact across various time frames by leveraging knowledge sharing and simultaneously monitoring the evolution of technology impact. First, we quantify the technology impacts and identify patterns through citation analysis over distinct time periods. Next, we develop MTL models to predict citation counts using multiple patent indicators over time. Finally, we examine the changes in key input indicators and their patterns over different periods using the SHapley Additive exPlanation method. We also offer guidelines for validating and interpreting the results by employing statistical methods and natural language processing techniques. A case study on battery technologies demonstrates that our approach not only deepens the understanding of technology impact, but also improves prediction accuracy, yielding valuable insights for both academia and industry.
Novelty-focused R&D landscaping using transformer and local outlier factor
Nov 05, 2024



While numerous studies have explored the field of research and development (R&D) landscaping, the preponderance of these investigations has emphasized predictive analysis based on R&D outcomes, specifically patents, and academic literature. However, the value of research proposals and novelty analysis has seldom been addressed. This study proposes a systematic approach to constructing and navigating the R&D landscape that can be utilized to guide organizations to respond in a reproducible and timely manner to the challenges presented by increasing number of research proposals. At the heart of the proposed approach is the composite use of the transformer-based language model and the local outlier factor (LOF). The semantic meaning of the research proposals is captured with our further-trained transformers, thereby constructing a comprehensive R&D landscape. Subsequently, the novelty of the newly selected research proposals within the annual landscape is quantified on a numerical scale utilizing the LOF by assessing the dissimilarity of each proposal to others preceding and within the same year. A case study examining research proposals in the energy and resource sector in South Korea is presented. The systematic process and quantitative outcomes are expected to be useful decision-support tools, providing future insights regarding R&D planning and roadmapping.
Robust Barycenter Estimation using Semi-Unbalanced Neural Optimal Transport
Oct 04, 2024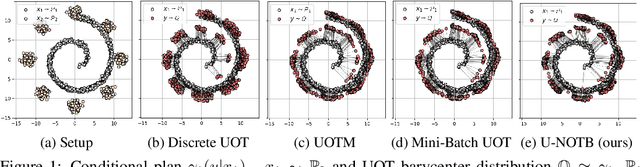
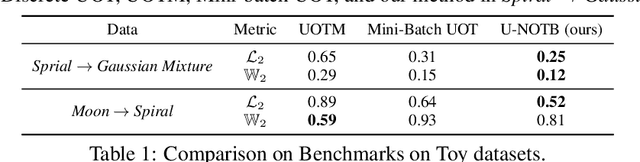
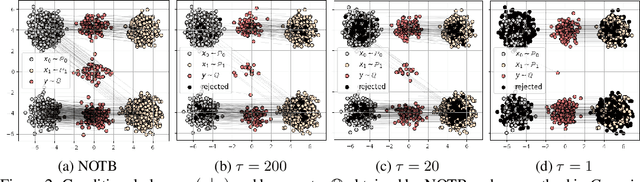
A common challenge in aggregating data from multiple sources can be formalized as an \textit{Optimal Transport} (OT) barycenter problem, which seeks to compute the average of probability distributions with respect to OT discrepancies. However, the presence of outliers and noise in the data measures can significantly hinder the performance of traditional statistical methods for estimating OT barycenters. To address this issue, we propose a novel, scalable approach for estimating the \textit{robust} continuous barycenter, leveraging the dual formulation of the \textit{(semi-)unbalanced} OT problem. To the best of our knowledge, this paper is the first attempt to develop an algorithm for robust barycenters under the continuous distribution setup. Our method is framed as a $\min$-$\max$ optimization problem and is adaptable to \textit{general} cost function. We rigorously establish the theoretical underpinnings of the proposed method and demonstrate its robustness to outliers and class imbalance through a number of illustrative experiments.
Scalable Simulation-free Entropic Unbalanced Optimal Transport
Oct 03, 2024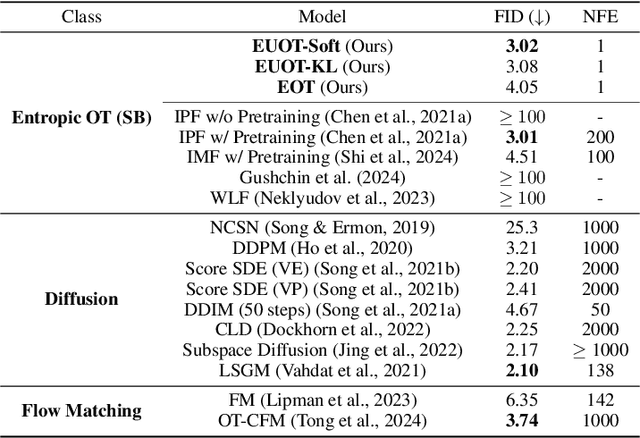


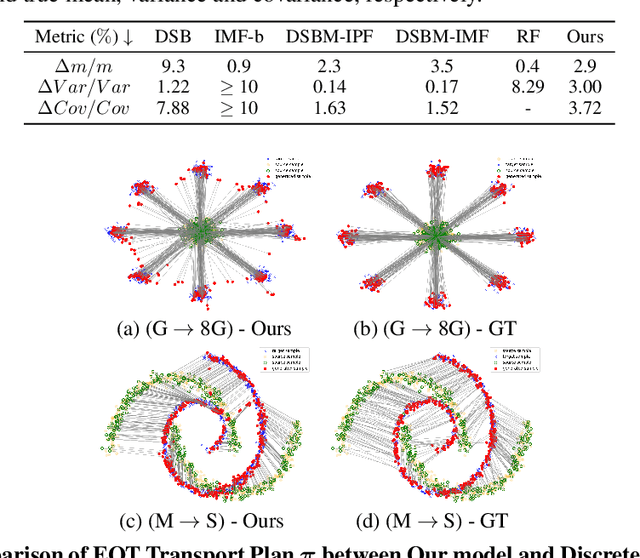
The Optimal Transport (OT) problem investigates a transport map that connects two distributions while minimizing a given cost function. Finding such a transport map has diverse applications in machine learning, such as generative modeling and image-to-image translation. In this paper, we introduce a scalable and simulation-free approach for solving the Entropic Unbalanced Optimal Transport (EUOT) problem. We derive the dynamical form of this EUOT problem, which is a generalization of the Schr\"odinger bridges (SB) problem. Based on this, we derive dual formulation and optimality conditions of the EUOT problem from the stochastic optimal control interpretation. By leveraging these properties, we propose a simulation-free algorithm to solve EUOT, called Simulation-free EUOT (SF-EUOT). While existing SB models require expensive simulation costs during training and evaluation, our model achieves simulation-free training and one-step generation by utilizing the reciprocal property. Our model demonstrates significantly improved scalability in generative modeling and image-to-image translation tasks compared to previous SB methods.