 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adjoint Matching for Fine-tuning Diffusion Models
May 12, 2026Reward fine-tuning has become a common approach for aligning pretrained diffusion and flow models with human preferences in text-to-image generation. Among reward-gradient-based methods, Adjoint Matching (AM) provides a principled formulation by casting reward fine-tuning as a stochastic optimal control (SOC) problem. However, AM inevitably requires a substantial computational cost: it requires (i) stochastic simulation of full generative trajectories under memoryless dynamics, resulting in a large number of function evaluations, and (ii) backward ODE simulation of the adjoint state along each sampled trajectory. In this work, we observe that both bottlenecks are closely tied to the \textit{non-trivial base drift} inherited from the pretrained model. Motivated by this observation, we propose \textbf{Efficient Adjoint Matching (EAM)}, which substantially improves training efficiency by reformulating the SOC problem with a \textit{linear base drift} and a correspondingly modified \textit{terminal cost}. This reformulation removes both sources of inefficiency; it enables training-time sampling with a few-step deterministic ODE solver and yields a closed-form adjoint solution that eliminates backward adjoint simulation. On standard text-to-image reward fine-tuning benchmarks, EAM converges up to 4x faster than AM and matches or surpasses it across various metrics including PickScore, ImageReward, HPSv2.1, CLIPScore and Aesthetics.
Efficient Generative Modeling beyond Memoryless Diffusion via Adjoint Schrödinger Bridge Matching
Feb 17, 2026Diffusion models often yield highly curved trajectories and noisy score targets due to an uninformative, memoryless forward process that induces independent data-noise coupling. We propose Adjoint Schrödinger Bridge Matching (ASBM), a generative modeling framework that recovers optimal trajectories in high dimensions via two stages. First, we view the Schrödinger Bridge (SB) forward dynamic as a coupling construction problem and learn it through a data-to-energy sampling perspective that transports data to an energy-defined prior. Then, we learn the backward generative dynamic with a simple matching loss supervised by the induced optimal coupling. By operating in a non-memoryless regime, ASBM produces significantly straighter and more efficient sampling paths. Compared to prior works, ASBM scales to high-dimensional data with notably improved stability and efficiency. Extensive experiments on image generation show that ASBM improves fidelity with fewer sampling steps. We further showcase the effectiveness of our optimal trajectory via distillation to a one-step generator.
Discrete Adjoint Schrödinger Bridge Sampler
Feb 09, 2026Learning discrete neural samplers is challenging due to the lack of gradients and combinatorial complexity. While stochastic optimal control (SOC) and Schrödinger bridge (SB) provide principled solutions, efficient SOC solvers like adjoint matching (AM), which excel in continuous domains, remain unexplored for discrete spaces. We bridge this gap by revealing that the core mechanism of AM is $\mathit{state}\text{-}\mathit{space~agnostic}$, and introduce $\mathbf{discrete~ASBS}$, a unified framework that extends AM and adjoint Schrödinger bridge sampler (ASBS) to discrete spaces. Theoretically, we analyze the optimality conditions of the discrete SB problem and its connection to SOC, identifying a necessary cyclic group structure on the state space to enable this extension. Empirically, discrete ASBS achieves competitive sample quality with significant advantages in training efficiency and scalability.
Generalized Schrödinger Bridge on Graphs
Feb 04, 2026Transportation on graphs is a fundamental challenge across many domains, where decisions must respect topological and operational constraints. Despite the need for actionable policies, existing graph-transport methods lack this expressivity. They rely on restrictive assumptions, fail to generalize across sparse topologies, and scale poorly with graph size and time horizon. To address these issues, we introduce Generalized Schrödinger Bridge on Graphs (GSBoG), a novel scalable data-driven framework for learning executable controlled continuous-time Markov chain (CTMC) policies on arbitrary graphs under state cost augmented dynamics. Notably, GSBoG learns trajectory-level policies, avoiding dense global solvers and thereby enhancing scalability. This is achieved via a likelihood optimization approach, satisfying the endpoint marginals, while simultaneously optimizing intermediate behavior under state-dependent running costs. Extensive experimentation on challenging real-world graph topologies shows that GSBoG reliably learns accurate, topology-respecting policies while optimizing application-specific intermediate state costs, highlighting its broad applicability and paving new avenues for cost-aware dynamical transport on general graphs.
Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation Beyond Loss Design
Feb 04, 2026Reinforcement learning has been widely applied to diffusion and flow models for visual tasks such as text-to-image generation. However, these tasks remain challenging because diffusion models have intractable likelihoods, which creates a barrier for directly applying popular policy-gradient type methods. Existing approaches primarily focus on crafting new objectives built on already heavily engineered LLM objectives, using ad hoc estimators for likelihood, without a thorough investigation into how such estimation affects overall algorithmic performance. In this work, we provide a systematic analysis of the RL design space by disentangling three factors: i) policy-gradient objectives, ii) likelihood estimators, and iii) rollout sampling schemes. We show that adopting an evidence lower bound (ELBO) based model likelihood estimator, computed only from the final generated sample, is the dominant factor enabling effective, efficient, and stable RL optimization, outweighing the impact of the specific policy-gradient loss functional. We validate our findings across multiple reward benchmarks using SD 3.5 Medium, and observe consistent trends across all tasks. Our method improves the GenEval score from 0.24 to 0.95 in 90 GPU hours, which is $4.6\times$ more efficient than FlowGRPO and $2\times$ more efficient than the SOTA method DiffusionNFT without reward hacking.
QUATRO: Query-Adaptive Trust Region Policy Optimization for LLM Fine-tuning
Feb 04, 2026GRPO-style reinforcement learning (RL)-based LLM fine-tuning algorithms have recently gained popularity. Relying on heuristic trust-region approximations, however, they can lead to brittle optimization behavior, as global importance-ratio clipping and group-wise normalization fail to regulate samples whose importance ratios fall outside the clipping range. We propose Query-Adaptive Trust-Region policy Optimization (QUATRO), which directly enforces trust-region constraints through a principled optimization. This yields a clear and interpretable objective that enables explicit control over policy updates and stable, entropy-controlled optimization, with a stabilizer terms arising intrinsically from the exact trust-region formulation. Empirically verified on diverse mathematical reasoning benchmarks, QUATRO shows stable training under increased policy staleness and aggressive learning rates, maintaining well-controlled entropy throughout training.
Overcoming Fake Solutions in Semi-Dual Neural Optimal Transport: A Smoothing Approach for Learning the Optimal Transport Plan
Feb 07, 2025



We address the convergence problem in learning the Optimal Transport (OT) map, where the OT Map refers to a map from one distribution to another while minimizing the transport cost. Semi-dual Neural OT, a widely used approach for learning OT Maps with neural networks, often generates fake solutions that fail to transfer one distribution to another accurately. We identify a sufficient condition under which the max-min solution of Semi-dual Neural OT recovers the true OT Map. Moreover, to address cases when this sufficient condition is not satisfied, we propose a novel method, OTP, which learns both the OT Map and the Optimal Transport Plan, representing the optimal coupling between two distributions. Under sharp assumptions on the distributions, we prove that our model eliminates the fake solution issue and correctly solves the OT problem. Our experiments show that the OTP model recovers the optimal transport map where existing methods fail and outperforms current OT-based models in image-to-image translation tasks. Notably, the OTP model can learn stochastic transport maps when deterministic OT Maps do not exist, such as one-to-many tasks like colorization.
Robust Barycenter Estimation using Semi-Unbalanced Neural Optimal Transport
Oct 04, 2024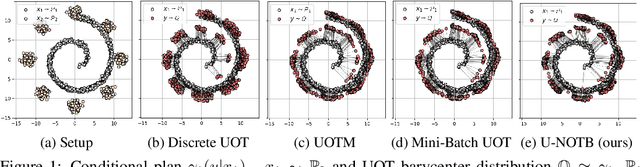
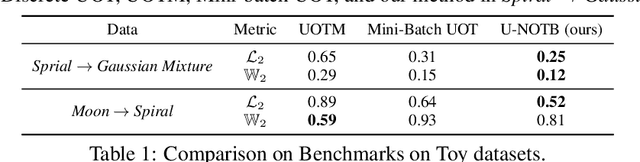
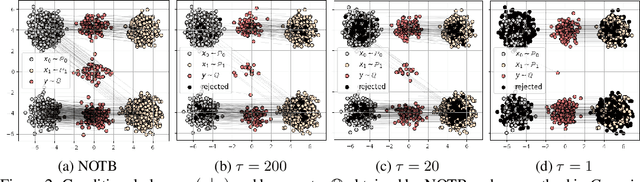
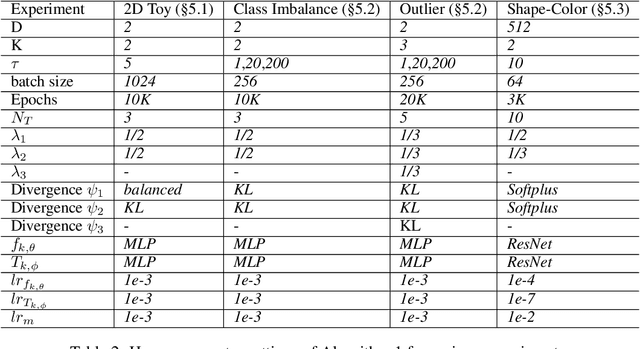
A common challenge in aggregating data from multiple sources can be formalized as an \textit{Optimal Transport} (OT) barycenter problem, which seeks to compute the average of probability distributions with respect to OT discrepancies. However, the presence of outliers and noise in the data measures can significantly hinder the performance of traditional statistical methods for estimating OT barycenters. To address this issue, we propose a novel, scalable approach for estimating the \textit{robust} continuous barycenter, leveraging the dual formulation of the \textit{(semi-)unbalanced} OT problem. To the best of our knowledge, this paper is the first attempt to develop an algorithm for robust barycenters under the continuous distribution setup. Our method is framed as a $\min$-$\max$ optimization problem and is adaptable to \textit{general} cost function. We rigorously establish the theoretical underpinnings of the proposed method and demonstrate its robustness to outliers and class imbalance through a number of illustrative experiments.
Scalable Simulation-free Entropic Unbalanced Optimal Transport
Oct 03, 2024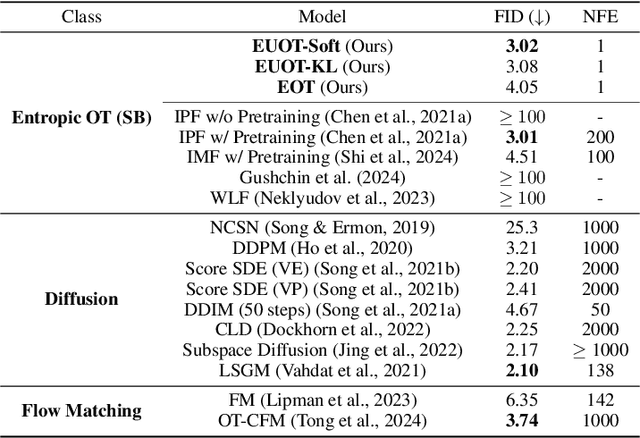


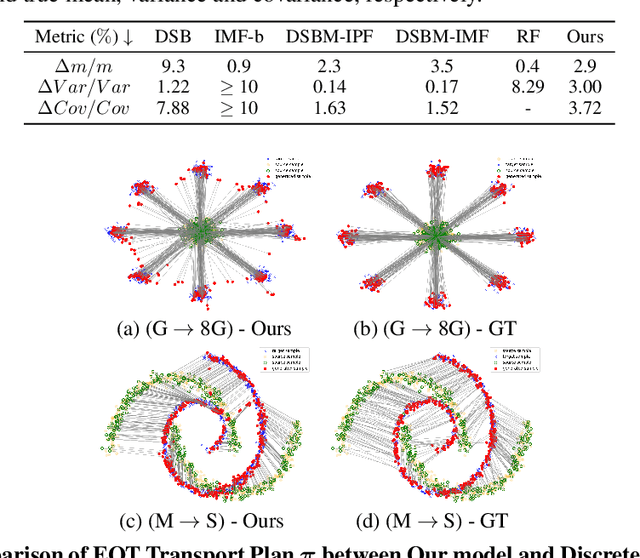
The Optimal Transport (OT) problem investigates a transport map that connects two distributions while minimizing a given cost function. Finding such a transport map has diverse applications in machine learning, such as generative modeling and image-to-image translation. In this paper, we introduce a scalable and simulation-free approach for solving the Entropic Unbalanced Optimal Transport (EUOT) problem. We derive the dynamical form of this EUOT problem, which is a generalization of the Schr\"odinger bridges (SB) problem. Based on this, we derive dual formulation and optimality conditions of the EUOT problem from the stochastic optimal control interpretation. By leveraging these properties, we propose a simulation-free algorithm to solve EUOT, called Simulation-free EUOT (SF-EUOT). While existing SB models require expensive simulation costs during training and evaluation, our model achieves simulation-free training and one-step generation by utilizing the reciprocal property. Our model demonstrates significantly improved scalability in generative modeling and image-to-image translation tasks compared to previous SB methods.
Unsupervised Point Cloud Completion through Unbalanced Optimal Transport
Oct 03, 2024


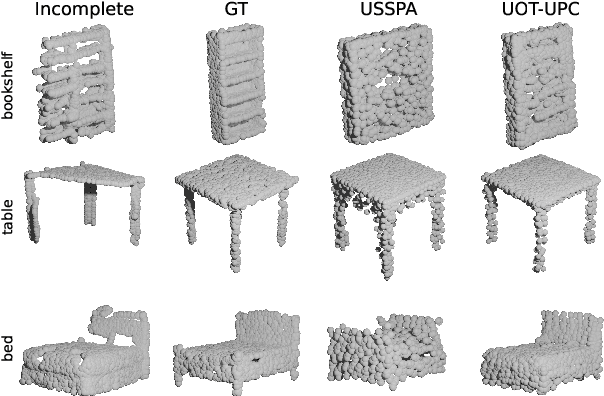
Unpaired point cloud completion explores methods for learning a completion map from unpaired incomplete and complete point cloud data. In this paper, we propose a novel approach for unpaired point cloud completion using the unbalanced optimal transport map, called Unbalanced Optimal Transport Map for Unpaired Point Cloud Completion (UOT-UPC). We demonstrate that the unpaired point cloud completion can be naturally interpreted as the Optimal Transport (OT) problem and introduce the Unbalanced Optimal Transport (UOT) approach to address the class imbalance problem, which is prevalent in unpaired point cloud completion datasets. Moreover, we analyze the appropriate cost function for unpaired completion tasks. This analysis shows that the InfoCD cost function is particularly well-suited for this task. Our model is the first attempt to leverage UOT for unpaired point cloud completion, achieving competitive or superior results on both single-category and multi-category datasets. In particular, our model is especially effective in scenarios with class imbalance, where the proportions of categories are different between the incomplete and complete point cloud datasets.